
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- YAI 9기
- 연세대학교 인공지능학회
- Faster RCNN
- transformer
- Googlenet
- rl
- CS231n
- RCNN
- YAI 10기
- 컴퓨터비전
- 3D
- CS224N
- VIT
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- YAI 11기
- NLP
- YAI
- cv
- Perception 강의
- 자연어처리
- 컴퓨터 비전
- Fast RCNN
- nerf
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- cl
- YAI 8기
- CNN
- GaN
- 강화학습
- PytorchZeroToAll
- Today
- Total
목록컴퓨터비전 : CV (24)
연세대 인공지능학회 YAI
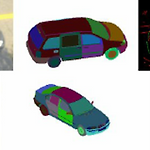 [논문 리뷰] Unsupervised Pixel-level Domain Adaptation with GAN
[논문 리뷰] Unsupervised Pixel-level Domain Adaptation with GAN
PixelDA ** YAI 9기 김기현님이 GAN 팀에서 작성한 글입니다. - 원글 링크 : https://aistudy9314.tistory.com/m/66 GAN을 사용하여 unsupervised domain adaption을 한 논문이다. 조금 오래 전 논문임에도 불구하고 foreground에 대한 높은 reconstruction performance를 보여준다. 이제 자세하게 살펴보도록 하자!! https://arxiv.org/abs/1612.05424 Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks Collecting well-annotated image datasets to train modern m..
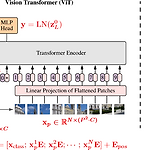 [논문 리뷰] Vision Transformer(ViT)
[논문 리뷰] Vision Transformer(ViT)
Vision Transformer(ViT) ** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다. 논문 소개 Papers with Code - Vision Transformer Explained Papers with Code - Vision Transformer Explained The Vision Transformer, or ViT, is a model for image classification that employs a Transformer-like architecture over patches of the image. An image is split into fixed-size patches, each of them are then linearly embedded, position emb..
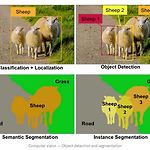 [논문 리뷰] Mask R-CNN
[논문 리뷰] Mask R-CNN
Mask R-CNN ** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다. 1. Introduction 비전 분야에서 객체 감지와 시멘틱 세그멘테이션은 단기간에 빠르게 성장했다. 이러한 발전은 대부분 Fast/Faster R-CNN과 FCN같은 강력한 기준 시스템에 의해 이루어졌다. 이 시스템들은 개념이 직관적이며, 유연성과 강건성(robustness)을 가질 뿐만 아니라 빠른 훈련 및 추론이 가능하다. 이 논문의 목표는 인스턴스 세그멘테이션에 대해 이와 비슷한 수준의 프레임워크를 개발하는 것이다. 1-1. Instance Segmentation 인스턴스 세그멘테이션은 이미지 내 모든 객체의 올바른 탐지와 각 인스턴스에 대한 정확한 분할이 동시에 이루어져야 하는 도전적인 작업이다. 따라서 다음의..
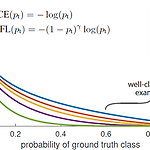 [논문 리뷰] Retina Net : Focal loss
[논문 리뷰] Retina Net : Focal loss
FPN + RetinaNet (Focal Loss) - (2) ** YAI 9기 조용기님이 비전 논문 심화팀에서 작성한 논문입니다. RetinaNet (Focal Loss) Papers with Code - RetinaNet Explained 1. Introduction 2020년 전까지의 object detecton milestones. 출처 : Murthy, C.B et al., Investigations of Object Detection in Images/Videos Using Various Deep Learning Techniques and Embedded Platforms—A Comprehensive Review. Applied Sciences. 2020. 당시의 SOTA object dete..
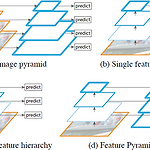 [논문 리뷰] FPN : Feature Pyramid Network
[논문 리뷰] FPN : Feature Pyramid Network
FPN + RetinaNet (Focal Loss) - (1) **YAI 9기 조용기님이 비전 논문 심화팀에서 작성한 글입니다. FPN Papers with Code - FPN Explained 1. Introduction Figure 1. (a) Using an image pyramid to build a feature pyramid. Features are computed on each of the image scales independently, which is slow. (b) Recent detection systems have opted to use only single scale features for faster detection. (c) An alternative is to reuse t..
 [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3)
[논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3)
R-CNN + Fast R-CNN + Faster R-CNN (3) ** YAI 9기 조용기님이 비전 논문심화팀에서 작성한 글입니다. Faster R-CNN Papers with Code - Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks 1 Introduction 이 논문이 쓰인 시점에 탐지 신경망 시스템에 존재하는 병목은 region proposal이었다. Selective Search는 CPU에서 연산되어, Fast R-CNN의 탐지 신경망에 비해 매우 느리다. EdgeBoxes는 proposal의 품질과 속도 사이 최상의 균형을 이루었지만 여전히 탐지 신경망만큼의 실행 시간을 필요로 한다. CNN이 GPU..
 [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (2)
[논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (2)
R-CNN + Fast R-CNN + Faster R-CNN ** YAI 9기 조용기님이 비전 논문심화팀에서 작성한 글입니다. Fast R-CNN Papers with Code - Fast R-CNN Explained 1. Introduction 이미지 분류 및 객체 탐지에서 Deep ConvNet의 활약으로 정확성은 올라갔으나, 복잡도 또한 증가해 모델의 처리 속도가 매우 느려졌다. 이러한 복잡성은 탐지 작업이 객체의 정확한 localization을 요구하기에 발생했고, 이는 두 가지 주요한 문제를 만들었다. 수많은 후보 객체의 proposal이 각각 CNN에서 처리되어야 한다. 이러한 후보들은 대략적인 localization만을 제공 하며 정확한 localization을 위해 개선을 필요로 한다. 이..
 [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN
[논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN
R-CNN + Fast R-CNN + Faster R-CNN ** YAI 9기 조용기님이 비전 논문심화팀에서 작성한 글입니다. R-CNN Papers with Code - R-CNN Explained 1. Introduction 다양한 시각적 인식 작업에서 SIFT와 HOG가 많이 사용되었지만, 최근 2010 ~ 2012년 사이 큰 발전이 없었다. SIFT와 HOG보다 시각적 인식에 더 유능한 feature를 계산하는 hierarchical, multi-scale process가 존재하는데, 역전파와 확률적 경사하강법(SGD)을 사용한 LeCun et al.의 convolution neural network(CNN)가 그렇다. CNN은 1990년대에 활발하게 사용되다 support vector machi..