
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- nerf
- CS224N
- cl
- CNN
- 자연어처리
- CS231n
- GaN
- RCNN
- 3D
- transformer
- YAI 8기
- Googlenet
- Perception 강의
- 강화학습
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- Faster RCNN
- 컴퓨터 비전
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- NLP
- YAI
- YAI 11기
- 연세대학교 인공지능학회
- YAI 9기
- PytorchZeroToAll
- Fast RCNN
- cv
- 컴퓨터비전
- YAI 10기
- VIT
- rl
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] Vision Transformer(ViT) 본문
Vision Transformer(ViT)
** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다.
논문 소개
Papers with Code - Vision Transformer Explained
Papers with Code - Vision Transformer Explained
The Vision Transformer, or ViT, is a model for image classification that employs a Transformer-like architecture over patches of the image. An image is split into fixed-size patches, each of them are then linearly embedded, position embeddings are added, a
paperswithcode.com
GitHub - google-research/vision_transformer
GitHub - google-research/vision_transformer
Contribute to google-research/vision_transformer development by creating an account on GitHub.
github.com
1. Introduction
- Self-attention 기반의 아키텍처, 특히 Transformer는 자연어 처리 (neural language processing, NLP)에서 표준 모델이다.
- 대규모 텍스트 말뭉치 (corpus)에서 사전훈련을 진행한 후 더 작은 작업별 데이터셋에서 미세조정을 수행하는 것이 일반적인 접근 방법이다.
- Transformer의 계산적 효율성과 확장성 덕분에, 100B 이상의 파라미터로 전례 없는 크기의 모델 훈련이 가능하게 되었다.
- 이에 반해 컴퓨터 비전에서는 컨볼루션 아키텍처가 일반적으로 사용되고 있다.
- NLP 분야에서의 성공에 힘입어, CNN 같은 아키텍처에 self-attention을 결합하는 다양한 연구가 있었으며, 그 중 일부는 컨볼루션을 완전히 대체할 정도의 성능을 보여주었다.
- 컨볼루션이 완전히 대체된 모델은 이론상 효율적이지만, 전문적인 attention 패턴을 사용했으므로 아직 최신 하드웨어 가속기에 확장되지 않았다.
- 따라서 대규모 이미지 인식 작업에서는 ResNet과 같은 아키텍처가 여전히 SOTA를 차지하고 있다.
- 이 논문에서는 NLP에서 Transformer 확장의 성공에 힘입어, 최소한의 수정을 가한 Transformer를 이미지에 직접적으로 적용하는 실험을 진행했다.
- 이를 위해, 이미지를 패치로 분할하고 (이 이미지 패치는 NLP에서 토큰 (단어)로 취급된다) 분할된 패치의 선형 임베딩 시퀀스를 만들어 Transformer의 입력으로 사용한다.
- 이미지 분류 모델 훈련에는 지도 학습 방식을 사용했다.
- 강력한 정규화 없이 ImageNet과 같은 중간 규모의 데이터셋에서 훈련되었을 때, 이 모델과 비슷한 크기인 ResNet보다 조금 낮은 퍼센트의 정확도를 산출해내었다.
- 이는 Transformer가 CNN 고유의 translation equivalence와 locality같은 귀납적 편향 (inductive bias)이 부족하기 때문에 부족한 양의 데이터에 훈련될 때 제대로 일반화되지 않기 때문으로 예측할 수 있다.
- 그러나 더 큰 크기의 데이터셋에서 모델을 훈련시킬 때는 이러한 대규모 훈련의 결과 귀납적 편향을 능가했다.
- 논문의 Vision Transformer (ViT)는 충분한 규모로 사전훈련되고 더 적은 데이터 포인트가 있는 작업으로 전달되면 훌륭한 결과를 얻어내었다.
- ImageNet-21k 데이터셋이나 JFT-300M 데이터셋에서 사전훈련되면, ViT는 다중 이미지 인식 벤치마크에서 SOTA에 접근하거나 능가하는 모습을 보여주었다. 특히, 최상의 모델은 ImageNet에서 88.55%, ImageNet-ReaL에서 90.72%, CIFAR-100에서 94.55%, 19개 작업의 VTAB (Visual Task Adaptation Benchmark)에서 77.63%의 정확도에 도달한다.
2. Related Work
- Transformer는 기계 번역 작업에서 제안되어 많은 NLP 작업에서 SOTA 방법이 되었다.
- 대규모의 Transformer 기반 모델은 보통 대규모 말뭉치에 사전훈련되고 당면한 작업에 미세조정된다.
- BERT는 자기지도 학습을 이용한 사전훈련 작업에 대한 denoising을 사용한다.
- GPT에서는 사전훈련 작업으로 언어 모델링을 사용한다.
- 대규모의 Transformer 기반 모델은 보통 대규모 말뭉치에 사전훈련되고 당면한 작업에 미세조정된다.
- Self-attention을 이미지에 naive하게 사용하려면 각 픽셀이 모든 다른 픽셀에 대해 attention을 적용해야 한다.
- 픽셀 수에 대한 이차 비용 함수를 사용할 경우 실제 입력 크기로 확장되지 않으므로 이미지 처리에서 transformer를 사용하기 위해 몇 가지 근사 방법이 제안되었다.
- Parmar et al.은 self-attention을 각 query 픽셀에 대해 global하게 적용하는 대신 local neighborhood에만 적용했다.
- 이러한 local multi-head dot-product self attention block은 컨볼루션을 완전히 대체할 수 있다.
- Sparse Transformer는 global self-attention에 확장 가능한 근사를 사용했다.
- Attention을 확장하는 또다른 방법은 다양한 크기의 블록에 attention을 적용하는 것인데, 극단적인 경우에 개별 축에만 적용되었다.
- 이러한 전문화된 attention 매커니즘은 컴퓨터 비전 작업에서 좋은 결과를 보여주지만, 하드웨어 가속기에 효율적으로 구현되기 위해 복잡한 엔지니어링 작업을 필요로 한다.
- 논문의 모델과 가장 비슷한 작업은 입력 이미지로부터 2 × 2 크기의 패치를 추출하고 맨 위에 full self-attention을 적용하는 Cordonnier et al.의 모델이었다.
- ViT와 매우 비슷하나, ViT는 대규모 사전작업이 Transformer를 SOTA CNN에 경쟁력이 있도록 만들었다.
- 또한 Cordonnier et al.의 모델이 2 × 2 픽셀의 작은 패치 크기를 사용하여 저해상도에만 적용이 가능한 반면, ViT가 중간 크기의 해상도를 다룰 수 있다는 점도 다르다.
- CNN을 self-attention과 결합하거나, self-attention을 사용하여 CNN의 출력을 처리하는 방식도 많은 연구가 있었다.
- CNN과의 결합 : augmenting feature maps for image classification (Bello et al., 2019)
- CNN 출력 처리 : object detection (Hu et al., 2018; Carion et al., 2020), video processing (Wang et al., 2018; Sun et al., 2019), image classification (Wu et al., 2020), unsupervised object discovery (Locatello et al., 2020), or unified text-vision tasks (Chen et al., 2020c; Lu et al., 2019; Li et al., 2019)
- ViT와 관련한 또 다른 모델로는 이미지의 해상도와 색상 공간을 줄인 후 Transformer를 이미지 픽셀에 적용하는 image GPT (iGPT)가 있었다.
- 비지도 학습 생성 모델로 훈련되었으며, 결과 표현이 분류 성능을 위해 미세조정되거나 linear probe가 적용되었다.
- 이 모델은 ImageNet에서 최대 정확도 72%를 달성했다.
- ViT는 표준 ImageNet 데이터셋보다 더 큰 규모의 이미지 인식도 수행한다.
- 추가적인 데이터 소스를 사용하면 표준 벤치마크에서 SOTA의 결과를 얻어낼 수 있었다.
- 이 논문에서는 ImageNet-21k와 JFT-300M 데이터셋을 사용했으며, ResNet 기반 모델 대신 Transformer를 훈련시켰다.
3. Method
3.1 Vision Transformer (ViT)

- 표준 Transformer는 입력으로 1차원의 토큰 임베딩 시퀀스를 받는다.
- 2차원 이미지를 입력으로 사용하기 위해, 이미지 $\bf{x}\in\mathbb{R}^{H\times W\times C}$ 를 flatten된 2차원 패치 $\bf{x}_p\in\mathbb{R}^{N\times(P^2\cdot C)} $ 로 reshape한다.
- $(H,W)$는 원래 이미지의 해상도, $C$는 채널 수이며 $(P,P)$는 각 이미지 패치의 해상도이다.
- $N=HW/P^2$는 계산된 패치 개수이며 Transformer의 effective input sequence 길이로 작용한다.
- Transformer는 상수의 잠재 벡터 (latent vector) 크기 $D$를 사용하며, 이에 따라 패치는 학습 가능한 선형 투영을 통해 flatten된 후 $D$ 차원으로 매핑된다 (Eq. 1).
- 이 투영의 출력을 패치 임베딩 (patch embedding)이라고 부른다.
- BERT의
[class]토큰과 비슷하게, 패치 임베딩의 맨 앞에 학습 가능한 임베딩을 붙인다 ($\bf{z}_0^0=\bf{x}_\text{class}$) (Eq. 4). 이 임베딩이 Transformer 인코더를 통과한 출력 ($\bf{z}_L^0$)의 상태가 이미지 표현 $\bf{y}$ 역할을 한다.- 사전훈련과 미세조정 동안, classification head는 $\bf{z}_L^0$에 연결된다.
- Classification head는 사전훈련 동안 은닉층이 하나인 MLP로, 미세조정 동안 단일 선형 레이어로 구현된다.
- 위치 정보를 유지하기 위해 위치 임베딩 (position embedding)이 패치 임베딩에 추가되었다.
- 학습 가능한 1차원 위치 임베딩을 사용했다. 2차원 위치 임베딩은 상당한 성능 향상을 보이지 않았다 (Appendix D.4).
- 생성된 임베딩 벡터 시퀀스는 인코더의 입력으로 사용된다.
- Transformer 인코더는 multiheaded self-attention (MSA, Appendix A)과 MLP 블록 (Eq. 2, 3)으로 구성되어 있다.
- Layernorm (LN)이 두 블록 앞에 각각 적용되었으며, residual connection은 두 블록 뒤에 각각 적용되었다.
- MLP는 GELU를 비선형 활성화 함수를 사용한 두 레이어를 포함한다.

Inductive bias
- Vision Transformer는 CNN보다 이미지별 귀납적 편향이 많이 부족하다.
- CNN에서는 locality, 2D neighborhood structure, 그리고 translation equivariance가 모델 전체에서 적용된다.
- ViT에서는 MLP 레이어만 locality와 translation equivariance를 가지며 self-attention은 이러한 특성을 가지고 있지 않는다.
- 2D neighborhood structure는 모델의 시작 부분에서 이미지를 패치로 자르고, 미세조정 동안에는 서로 다른 해상도에 대해 위치 임베딩을 조정하는 등으로 드물게 사용된다.
- 초기화시 위치 임베딩은 패치의 2D 위치 정보를 전달하지 않으며 패치의 모든 공간 관계는 처음부터 학습해야 한다.
- 2D neighborhood structure는 모델의 시작 부분에서 이미지를 패치로 자르고, 미세조정 동안에는 서로 다른 해상도에 대해 위치 임베딩을 조정하는 등으로 드물게 사용된다.
Hybrid Architecture
- 원래의 이미지 패치에 대한 대안으로, 입력 시퀀스는 CNN의 feature map으로부터 만들어질 수 있다.
- 이 hybrid 모델에서는 패치 임베딩 투영 $\bf{E}$ (Eq. 1)이 CNN feature map에서 추출된 패치에 적용된다.
- 패치는 1 × 1 크기를 가지며 이는 입력 시퀀스가 feature map의 공간 차원을 단순히 flatten하고 Transformer 차원에 투영함을 의미한다.
- 분류 입력 임베딩과 위치 임베딩이 위의 과정대로 추가된다.
3.2 Fine-tuning and Higher Resolution
- 일반적으로, ViT를 대규모 데이터셋에 사전훈련시키고 작은 개별 작업에 미세조정한다.
- 이를 위해, 사전훈련된 prediction head를 제거하고 0으로 초기화된 $D\times K$ 피드포워드 레이어를 추가했다.
- 이 때 $K$는 클래스의 수이다.
- 사전훈련보다 높은 해상도로 미세조정하는 것이 종종 효과적이다.
- 고해상도의 이미지를 사용하면 패치 크기를 똑같이 유지할 때 더 큰 effective sequence를 가지게 된다.
- 이를 위해, 사전훈련된 prediction head를 제거하고 0으로 초기화된 $D\times K$ 피드포워드 레이어를 추가했다.
- ViT는 임의의 시퀀스 길이를 다룰 수 있으나, 사전훈련된 위치 임베딩에서는 그렇지 못할 수 있다.
- 따라서 논문에서는 사전훈련된 위치 임베딩의 원 이미지 상의 위치에 따른 2D 보간을 적용한다.
- 이 해상도 조정과 패치 추출이 ViT가 사용할 수 있는 이미지 2D 구조에 대한 유일한 귀납적 편향이다.
4. Experiment
- ResNet, ViT, 그리고 hybrid 아키텍처의 표현 학습 능력을 평가했다.
- 각 모델의 데이터 요구 사항을 이해하기 위해, 다양한 크기의 데이터셋에 사전학습 후 많은 벤치마크를 사용해 평가했다.
- ViT는 대부분의 인식 벤치마크에서 적은 사전훈련 비용으로 SOTA를 달성했다.
- 자기지도 학습을 사용한 실험도 진행했다.
4.1 Set up
Datasets
- 모델 확장성을 탐구하기 위해 다음의 데이터셋들을 사용했다.
- ILSVRC-2012 ImageNet 1k 1.3M images, and ImageNet-21k 14M images
- JFT with 18k classes and 303M high-resolution images
- Kolesnikov et al. 을 따라 downstream task의 테스트 세트에 맞춰 사전훈련 데이터셋에서 중복을 제거했다.
- 데이터셋들로 훈련된 모델을 다음의 벤치마크 테스트에 대해 전이학습시켰다. 전처리는 Kolesnikov et al. 의 방식을 따랐다.
- ImageNet on the original validation labels and the cleaned-up ReaL labels
- CIFAR-10/100
- Oxford-IIIT Pets
- Oxford Flowers-102
- 19-task VTAB 분류 작업 또한 사용하여 모델을 평가했다.
- VTAB은 작업별로 1000개의 훈련 샘플을 사용하여 low-data의 다양한 작업에 대한 전이학습을 평가한다.
- 작업은 세 가지 그룹으로 나뉜다.
- Natural : Pets, CIFAR와 같은 작업
- Specialized : 의료나 위성 이미지
- Structured : localization과 같은 기하학적 이해가 필요한 작업
Model Variants

- BERT에서 사용된 설정을 기반으로 ViT 설정을 구성했으며, 이는 Table 1에 요약되어 있다.
- “Base”와 “Large” 모델은 BERT의 모델을 직접 채택했으며, 논문에서는 더 큰 “Huge” 모델을 추가헀다.
- 이 논문에서는 모델 크기와 입력 패치 크기에 대한 모델 표기법을 사용한다.
- 예를 들어 ViT-L/16은 입력 패치 크기 16 × 16의 “Large” 모델이다.
- Transformer의 시퀀스 길이는 패치 크기의 제곱에 반비례하므로 더 작은 패치 크기를 가진 모델의 계산 비용이 더 많이 든다.
- CNN baseline에서는 ResNet을 사용하며 Batch Normalization 레이어를 Group Normalization으로 대체하고 standardized convolution을 사용했다.
- 이러한 “ResNet (BiT)”에서의 수정 사항은 전이학습 성능을 향상시킨다.
- Hybrid 아키텍처에서는 ViT에 중간 feature-map을 패치 크기 1 × 1로 사용했다.
- 서로 다른 시퀀스 길이로 실험하기 위해 다음을 사용했다.
- ResNet50의 stage 4 출력
- ResNet40의 같은 수 레이어의 stage 3 출력 (4배 긴 시퀀스 길이)
- 서로 다른 시퀀스 길이로 실험하기 위해 다음을 사용했다.
Training & Fine-tuning
- 훈련 : 다음의 하이퍼파라미터 값들이 전이학습에 효과적임을 찾아냈다.
- 최적화기 : Adam with $\beta_1=0.9,\beta_2=0.999$
- 배치 크기 : 4096
- 가중치 감쇠 : 0.1 (높은 값을 채택)
- 선형 학습률에 warm up과 decay를 적용 (Appendix B.1)
- 미세조정
- 최적화기 : SGD with momentum
- 배치 크기 : 512
- Table 2의 ImageNet 결과에서는 다음과 같은 변경이 있었다.
- 해상도 변경 : ViT-L/16 → 512, ViT-H/16 → 518
- Polyak & Judisky averaging with a factor of 0.999
Metrics
- Few-shot과 fine-tuning 정확도를 사용하여 downstream dataset의 결과를 측정했다.
- Fine-tuning 정확도 : 각 데이터셋에 대한 미세조정 이후에 성능을 측정했다.
- Few-shot 정확도 : 훈련 이미지 부분집합의 (frozen) representation을 ${-1,1}^K$ 타깃 벡터로 매핑하는, 정규화된 최소제곱법 (regularized least squares, RLS) 회귀를 계산하여 측정했다.
- 주로 fine-tuning 정확도에 주목하지만, fine-tuning 비용이 너무 클 때 빠른 측정을 위해 few-shot 정확도를 사용했다.
4.2 Comparison to State of the Art
- ViT-H/14와 ViT-L/16을 SOTA CNN들과 비교했다.
- 첫 번째 비교는 large ResNet에 지도 전이학습을 진행한 Big Transfer (BiT)이다.
- 두 번째 비교는 레이블 없는 ImageNet과 JET-300M으로 large EfficientNet에 준지도 학습을 진행한 Noisy Student이다.
- 모든 모델들은 TPUv3 하드웨어로 훈련되었으며, 각 모델을 사전훈련하는데 걸린 TPUv3-core-days, 즉 훈련에 사용된 TPUv3 core 수에 일별 훈련시간을 곱한 것을 기록했다.

Table 2: Comparison with state of the art on popular image classification benchmarks. We report mean and standard deviation of the accuracies, averaged over three fine-tuning runs. Vision Transformer models pre-trained on the JFT-300M dataset outperform ResNet-based baselines on all datasets, while taking substantially less computational resources to pre-train. ViT pre-trained on the smaller public ImageNet-21k dataset performs well too. Slightly improved 88:5% result reported in Touvron et al. (2020).

4.3 Pre-training Data Requirements
- Vision Transformer는 JFT-300M 데이터셋에서 사전훈련될 경우 좋은 성능을 보인다.
- 이 section에서는 ResNet보다 적은 귀납적 편향을 가지는 ViT에서 데이터셋 크기의 중요성을 두 가지 실험을 통해 탐구한다.
- ViT 모델을 증가하는 크기의 다른 데이터셋들 (ImageNet, ImageNet-21k, JFT-300M)에 사전훈련시킨다. Figure 3에서는 ImageNet에서 사전훈련된 결과를, Table 5에서는 다른 데이터셋에 대한 결과를 보여주고 있다 (ImageNet에서 사전훈련된 모델들은 또한 ImageNet에서 해상도를 키워서 미세조정되었다).
- 더 작은 데이터셋에서 성능을 향상시키기 위해, weight decay, dropout, label smoothing의 세 가지 기본 정규화 매개변수를 추가했다.
- 가장 작은 ImageNet에서 사전훈련된 ViT-Large 모델은 적당한 정규화를 사용했음에도 ViT-Base 모델에 비해 낮은 성능을 보여주었다. ImageNet-21k 사전훈련에서도 성능 양상은 비슷했다. 가장 큰 JFT-300M에서 더 큰 모델의 이점을 볼 수 있었다.
- Figure 3에서는 또한 다양한 크기의 BiT 모델의 성능 영역도 확인할 수 있다. BiT CNN은 ImageNet에서 ViT를 능가하지만, JFT-300M에서는 ViT의 성능이 우세하다.
- 모델을 JFM-300M 데이터셋 전체와 그 무작위 9M , 30M, 90M 부분집합에서 훈련시켰다. Figure 4에서 결과를 보여준다.
- 부분집합에서는 추가적인 정규화를 가하지 않고 똑같은 하이퍼파라미터를 사용해, 고유 모델 속성을 평가했다.
- Early-stopping을 사용해 훈련 중 최상의 검증 정확도를 측정했으며, 계산 비용울 줄이기 위해 fine-tuning 정확도 대신 few-shot 선형 정확도를 측정했다.
- 더 작은 데이터셋에서 ViT가 비슷한 계산 비용으로 ResNet보다 과적합되었다. 예를 들어 ViT-B/32가 ResNet50보다 조금 더 빠르고, 9M에서는 성능이 좋지 않지만 90M+에서는 더 좋은 성능을 보여준다.
- ViT 모델을 증가하는 크기의 다른 데이터셋들 (ImageNet, ImageNet-21k, JFT-300M)에 사전훈련시킨다. Figure 3에서는 ImageNet에서 사전훈련된 결과를, Table 5에서는 다른 데이터셋에 대한 결과를 보여주고 있다 (ImageNet에서 사전훈련된 모델들은 또한 ImageNet에서 해상도를 키워서 미세조정되었다).
- 이러한 결과는 컨볼루션의 귀납적 편향이 작은 데이터셋에서는 유용하지만, 더 큰 데이터셋에서는 데이터에서 직접적으로 패턴을 학습하는 것이 충분하고 심지어 유용하다는 것을 암시한다.


4.4 Scaling Study
- JFT-300M으로부터의 전이학습 성능을 측정하기 위해 여러 모델에 대한 scaling study를 수행했다.
- 여기서 데이터의 크기가 모델 성능에 병목이 되지 않으며, 각 모델의 사전훈련 비용 대비 성능을 평가했다 (Figure 5, Appendix D.5, Table 6).
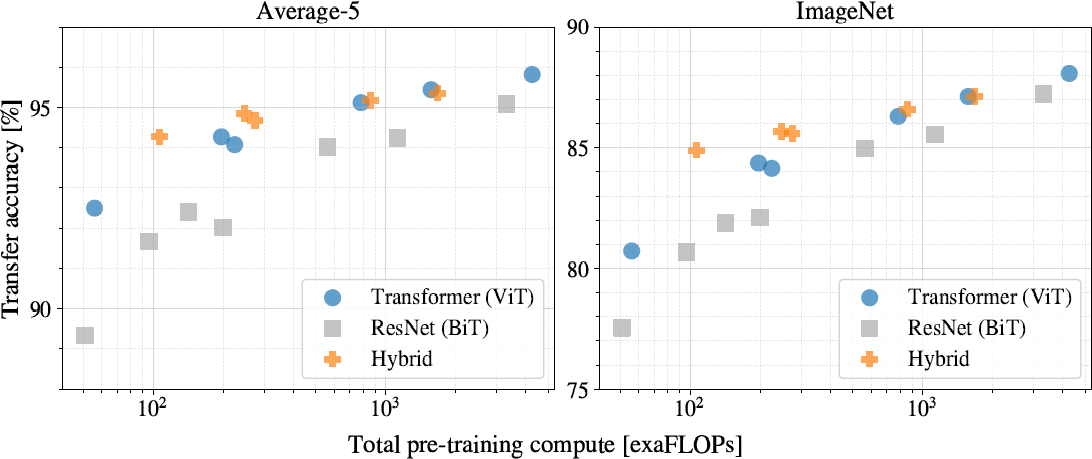
- Figure 5에서 몇 가지 패턴을 관측할 수 있었다.
- ViT는 성능/계산량 트레이드오프에서 ResNet에 비해 월등했다. 같은 성능을 얻어는데 ViT는 2~4 배 적은 비용이 들었다.
- Hybrid는 적은 계산에서 ViT보다 우수하지만 모델이 커질 수록 그 차이가 사라졌다.
- ViT는 시도한 스케일에서 포화되지 않는 것으로 보여 성능이 더 좋아질 수 있음을 암시한다.
4.5 Inspecting Vision Transformer
- Vision Transformer가 이미지 데이터 처리를 어떻게 하는지 이해하기 위해 내부 표현 (internal representation)을 분석했다.

- ViT의 첫 번째 레이어는 flatten된 패치를 저차원 공간으로 선형 투영한다.
- Figure 7 (left)에서는 학습된 임베딩 필터에서 맨 위의 주성분 (principal component, PC)를 보여준다.
- 각 성분들은 각 패치 미세 구조의 저차원 표현에 대한 기저 함수와 유사하다.

- 투영 이후에는 패치 표현에 학습된 위치 임베딩이 추가된다.
- Figure 7 (center)에서는 모델이 위치 임베딩 유사도 (position embedding similarity)로 이미지 내 거리 인코딩을 학습함을 보여준다. 가까운 패치가 더 비슷한 위치 임베딩을 가지는 것으로 보인다.
- 또한 행-열 구조를 볼 수 있다. 똑같은 행/열의 패치는 비슷한 임베딩을 가진다.
- 때때로 더 큰 그리드에서 사인파 구조가 분명하게 드러난다 (Appendix D).
- 위치 임베딩이 2D 이미지 위상을 학습한다는 사실은 hand-crafted 2D 임베딩이 성능 향상을 못하는 이유를 설명한다.

- Self-attention를 통해, ViT는 심지어 가장 아래의 레이어에서도 전체 이미지에 걸쳐 정보를 통합할 수 있다.
- Figure 7 (right)에서 attention 가중치에 기반해 논문에서는 신경망이 이러한 능력을 얼마나 사용하는지 조사했다.
- 이 “attention distance”는 CNN의 receptive field 크기와 유사하다.
- 일부 attention head는 가장 아래의 레이어에서 이미 존재하는 대부분의 이미지에 attention을 가하며 이는 모델이 실제로 전역적으로 정보를 통합하는 능력을 사용함을 알 수 있다.
- 다른 attention head는 낮은 레이어에서 작은 attention distance를 가진다.
- 이 highly localized attention은 ResNet을 사용하는 hybrid 모델보다 Transformer에서 두드러지며, 이는 CNN의 초기 컨볼루션 레이어와 비슷한 기능을 수행함을 시사한다.
- 또한 attention distance는 신경망의 깊이에 따라 증가한다.
- 전역적으로 모델이 분류 작업에서 의미적으로 관련이 있는 영역에 attention을 가한다는 사실을 알아내었다 (Figure 6).

4.6 Self-supervision
- Transformer는 NLP 작업에서 인상적인 성능을 보여주었다.
- 이 성능의 대부분은 Transformer의 확장성 뿐만 아니라 대규모의 자기지도 사전학습에서 비롯된다.
- 논문에서는 BERT에서 사용된 마스크 언어 모델 작업을 따라해, 자기지도 학습 마스크 패치 예측에 대한 예비 탐색을 수행했다.
- 자기지도 사전훈련을 사용해 ViT-B/16 모델은 ImageNet에서 79.9% 정확도를 달성했다.
- 처음부터 훈련되었을 때에 비해 2%의 향상이 있었으나, 지도 사전훈련에 비해서는 여전히 4% 낮은 성능을 보였다.
- 자기지도 사전훈련을 사용해 ViT-B/16 모델은 ImageNet에서 79.9% 정확도를 달성했다.
5. Conclusion
- 컴퓨터 비전에서 self-attention을 사용한 이전 연구들과 다르게, Vision Trasformer는 초기 패치 추출 스텝을 제외한 나머지 아키텍처에서 이미지별 귀납적 편향을 사용하지 않았다.
- 그 대신 이미지를 패치의 시퀀스로 해석하고 NLP에서 사용하는 표준 Transformer 인코더로 처리했다.
- 이 간단하고 확장 가능한 전략은 대규모 데이터셋 사전훈련과 같이 사용될 경우 훌륭한 성능을 보여준다.
- 따라서 ViT는 많은 이미지 분류 데이터셋에서 SOTA 이상의 성능을 보여주면서 적은 훈련 비용을 필요로 하는 모델이다.
- ViT는 좋은 성능을 보여주지만, 아직 해결할 과제가 많이 남아있다.
- 탐지와 세그멘테이션 등의 다른 비전 작업에 적용
- 자기지도 사전훈련 방법의 탐구
- ViT 모델 크기의 확장
'컴퓨터비전 : CV > Transformer based' 카테고리의 다른 글
| [논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (0) | 2022.08.13 |
|---|
