
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- RCNN
- YAI 10기
- PytorchZeroToAll
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- Googlenet
- CS231n
- NLP
- 컴퓨터비전
- Fast RCNN
- nerf
- 연세대학교 인공지능학회
- 자연어처리
- CS224N
- CNN
- YAI 8기
- YAI
- YAI 9기
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- cv
- 강화학습
- cl
- Perception 강의
- YAI 11기
- 3D
- VIT
- rl
- GaN
- Faster RCNN
- transformer
- 컴퓨터 비전
- Today
- Total
목록컴퓨터비전 : CV/Transformer based (2)
연세대 인공지능학회 YAI
 [논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ** YAI 9기 박찬혁님이 비전논문팀에서 작성한 글입니다. Introduction 현재 Transformer와 같은 Self-attention-based 구조들이 NLP에서 주된 방식이다. 이 방법들은 주로 큰 모델에서 사전학습을 진행 후에 작은 데이터셋으로 Fine tuning하여 사용하는 방식으로 쓰인다. 이 Transformer 방식을 이미지에 바로 적용시키는 것이 이 논문의 목적이다. 이미지를 patch라는 작은 단위로 나누어서 NLP의 token과 같은 방식으로 간단한 imbedding 후에 Transformer에 집어넣는다. 이 방식은 기존 CNN이 이미지에 ..
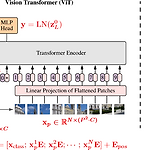 [논문 리뷰] Vision Transformer(ViT)
[논문 리뷰] Vision Transformer(ViT)
Vision Transformer(ViT) ** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다. 논문 소개 Papers with Code - Vision Transformer Explained Papers with Code - Vision Transformer Explained The Vision Transformer, or ViT, is a model for image classification that employs a Transformer-like architecture over patches of the image. An image is split into fixed-size patches, each of them are then linearly embedded, position emb..