
Notice
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
Tags
- Faster RCNN
- 컴퓨터 비전
- 강화학습
- Perception 강의
- GaN
- transformer
- CS224N
- cl
- 연세대학교 인공지능학회
- YAI 8기
- YAI 10기
- 자연어처리
- VIT
- Fast RCNN
- 컴퓨터비전
- Googlenet
- rl
- YAI 9기
- YAI
- NLP
- YAI 11기
- CNN
- PytorchZeroToAll
- nerf
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- 3D
- CS231n
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- cv
- RCNN
Archives
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (2) 본문
R-CNN + Fast R-CNN + Faster R-CNN
** YAI 9기 조용기님이 비전 논문심화팀에서 작성한 글입니다.
Fast R-CNN
Papers with Code - Fast R-CNN Explained
1. Introduction
- 이미지 분류 및 객체 탐지에서 Deep ConvNet의 활약으로 정확성은 올라갔으나, 복잡도 또한 증가해 모델의 처리 속도가 매우 느려졌다.
- 이러한 복잡성은 탐지 작업이 객체의 정확한 localization을 요구하기에 발생했고, 이는 두 가지 주요한 문제를 만들었다.
- 수많은 후보 객체의 proposal이 각각 CNN에서 처리되어야 한다.
- 이러한 후보들은 대략적인 localization만을 제공 하며 정확한 localization을 위해 개선을 필요로 한다.
- 이러한 문제에 대한 해답은 종종 속도, 정확성, 또는 단순성을 손상시키는 것이었다.
- 이 논문에서는 SOTA ConvNet 기반 object detector의 훈련 과정을 간소화한다. Object proposal 분류와 spatial location 수정을 공동으로 학습하는 single-stage 훈련 알고리즘을 소개한다.
1.1. R-CNN and SPPnet
R-CNN
- R-CNN은 object proposal 분류를 위해 deep ConvNet을 사용하며 훌륭한 객체 탐지 정확도를 보여주지만, 주목할 만한 단점이 있다:
- Training is a multi-stage pipeline : R-CNN은 다음과 같이 훈련된다.
- 로그 손실을 사용하여 object proposal에 ConvNet을 fine-tuning시킨다.
- Object detection SVM을 ConvNet feature로 훈련시킨다.
- Bounding-box regressor를 학습시킨다.
- Training is expensive in space and time : SVM과 bounding-box regressor 훈련에서, 각 이미지의 모든 object proposal에서 feature가 각각 추출되어 디스크에 기록된다. 깊은 신경망에서 이러한 훈련 과정은 매우 오래 걸리고 고용량이다.
- Object detection is slow : 테스트 단계에서도 각 테스트 이미지의 object proposal마다 feature가 추출되므로 여전히 시간이 오래 걸린다.
- R-CNN이 느린 이유는 결정적으로 각 object proposal마다 CNN 연산이 수행되고, 이 연산을 공유하지 않는 데에 있다.
- Training is a multi-stage pipeline : R-CNN은 다음과 같이 훈련된다.
SPPnet
- Spatial pyramid pooling networks(SPPnets)는 R-CNN의 느린 속도를 개선하기 위해 제안되었다.
- 전체 입력 이미지에 대한 convolutional feature map을 계산하고, 이 공유되는 feature map에서 추출한 feature vector를 사용하여 각 object proposal을 분류한다.
- Proposal에 해당하는 feature map 부분에 max-pooling을 진행해 proposal을 위한 고정된 크기의 출력으로 추출된다.
- Spatial pyramid pooling처럼 출력 크기에 상관없이 풀링되고 합쳐진다.
- SPPnet 또한 단점이 있다.
- R-CNN처럼, 훈련이 multi-stage pipeline이며 공간적으로 비용이 크다.
- Fine-tuning 알고리즘이 spatial pyramid pooling의 레이어까지 도달하지 못한다.
- 참고 : https://yeomko.tistory.com/14
1.2. Contributions
- R-CNN과 SPPnet보다 높은 탐지 성능(mAP)을 가진다.
- 훈련 단계가 multi-task loss를 사용한 single-stage이다.
- 훈련 단계에서 모든 신경망 레이어를 수정할 수 있다.
- Feature 캐싱을 위해 디스크 공간이 필요하지 않는다.
2. Fast R-CNN architecture and training

Figure 1. Fast R-CNN architecture. An input image and multiple regions of interest (RoIs) are input into a fully convolutional network. Each RoI is pooled into a fixed-size feature map and then mapped to a feature vector by fully connected layers (FCs). The network has two output vectors per RoI: softmax probabilities and per-class bounding-box regression offsets. The architecture is trained end-to-end with a multi-task loss.
- Fast R-CNN의 아키텍처의 흐름은 다음과 같다:
- 전체 이미지와 일련의 object proposal을 입력으로 받는다.
- 전체 이미지를 convolutional ($conv$)과 max pooling layer에서 처리하여 conv feature map을 만들어낸다.
- Region of interest ($RoI$) pooling layer가 feature map에서 각의 object proposal마다 고정된 길이의 feature vector를 추출한다.
- 각 feature vector는 일련의 fully connected ($fc$) layer에 입력되어 두 출력 레이어로 나온다:
- Softmax : $K+1$개의 클래스에 대한 (하나는 “background”) softmax 확률을 만들어내는 레이어
- Bounding box regressor : $K$개 객체 클래스 각각에 대한 bounding-box 위치 실수 값 4개를 출력하는 레이어
2.1. The RoI pooling layer

이해를 돕기 위해 추가한 사진. 출처 : [https://yeomko.tistory.com/15](https://yeomko.tistory.com/15)
- RoI pooling layer는 max pooling을 사용하여 유효한 region of interest를 고정된 $H\times W$ 크기를 가진 작은 feature map으로 변환 한다. 이 때 $H$와 $W$는 특정 RoI와 무관한 레이어 하이퍼파라미터이다.
- 이 논문에서 RoI는 conv feature map 안에 project된 직사각형 window 이다. 튜플 $(r,c,h,w)$로 정의되며 각각 좌상 꼭짓점 $(r,c)$의 좌표와 너비 및 높이 $(h,w)$이다.
- RoI max pooling은 $h \times w$의 RoI window를 $H \times W$개의 sub-window의 그리드로 나누고 (sub-window의 크기는 약 $h/H \times w/W$) 각 sub-window마다 max-pooling을 처리한다.
2.2. Initializing from pre-trained networks
- 이 논문에서는 5개의 max pooling layer와 5~13개의 conv layer를 가진 사전훈련된 ImageNet 신경망으로 실험했다.
- 이 신경망으로 Fast R-CNN을 초기화할 때, 세 가지 변환을 거친다.
- 마지막 max pooling layer는 RoI pooling layer로 대체하며 첫 번쨰 fully connected layer와 연결되도록 $H$와 $W$로 크기를 조정한다.
- 신경망의 마지막 FC layer와 softmax가 앞서 소개한 두 출력 레이어로 대체하다.
- 신경망이 두 데이터 입력인 이미지 리스트와 각 이미지의 RoI 리스트를 받도록 수정한다.
2.3. Fine-tuning for detection
- Fast R-CNN의 중요한 기능 중 하나는 모든 신경망의 가중치에 역전파가 도달하는 것이다.
- SPPnet이 spatial pyramid pooling layer에서 가중치를 업데이트할 수 없는 근본적인 원인은 다음과 같다.
- SPP layer를 통한 역전파가 매우 비효율적이다. R-CNN과 SPPnet은 각 훈련 샘플(RoI)가 각각 다른 이미지에서 샘플링 된다. 비효율은 또 RoI가 떄로 전체 이미지까지 커질 수 있는 매우 큰 receptive field를 가진다는 것에서 비롯된다. 순방향 전파가 전체 receptive field를 처리해야 하므로, 훈련 입력이 매우 커진다.
- 이에 대해 Fast R-CNN에서는 훈련 동안에 feature를 공유할 수 있는 더 효율적인 훈련 방법을 제안했다.
- SGD 미니 배치가 계층적으로 샘플링(hierarchical sampling)되며 먼저 $N$개의 이미지를 샘플링하고 각 이미지에서 $R/N$개의 RoI를 샘플링한다.
- 이를 통해, 같은 이미지의 RoI들은 순방향 및 역방향 전파에서 연산과 메모리를 공유한다.
- $N$을 줄이면 미니 배치 연산도 줄어든다. 예를 들어 $N=2, R=128$으로 샘플링할 경우, 서로 다른 128장의 이미지에서 하나의 RoI를 샘플링할 때보다 훈련이 64배 빨라졌다.
- 이 전략에 대한 우려는 같은 이미지의 RoI는 서로 상관관계가 있어 학습의 수렴이 느려질 수 있다는 것이다. 하지만 위의 샘플링 예를 실험해보았을 때 좋은 결과를 얻어내었기 때문에 우려는 실질적인 문제로 보이지 않는다.
- 계층적 샘플링에 더해, Fast R-CNN은 softmax classifier와 bounding-box regressor를 동시에 최적화하는 간소화된 훈련을 사용했다.
Multi-task loss
- Fast R-CNN 신경망은 두 개의 출력 레이어를 가진다.
- Softmax classifier : RoI별로 $K+1$ 카테고리에 대한 이산 확률 분포 $p=(p_0,\dots,p_K)$ 를 출력한다. 일반적으로 $p$는 FC layer의 $K+1$ 출력에 대한 softmax로 계산된다.
- Bounding box regressor : $K$ 객체 클래스 각각에 대한 bounding-box regression offset $t^k=(t_\text{x}^k,t_\text{y}^k,t_\text{w}^k,t_\text{h}^k)$를 출력한다. $t^k$는 object proposal에 대한 scale-invariant translation과 로그 공간에서 너비 및 높이의 shift를 의미한다.
- 각 RoI 훈련은 ground-truth class $u$와 ground-truth bounding-box regression target $v$로 레이블링된다. classification과 bounding-box regression을 동시에 훈련시키기 위한 multi-task loss $L$은 다음과 같다:
- $L_\text{cls}(p,u)=-\log p_u$는 정답 클래스 $u$의 로그 손실이다.
- $L_\text{loc}$는 $u$의 true bounding-box regression target인 $v=(u_\text{x},u_\text{y},u_\text{w},u_\text{h})$와 예측 튜플 $t^u=(t_\text{x}^u,t_\text{y}^u,t_\text{w}^u,t_\text{h}^u)$의 식으로 정의된다. Iverson bracket indicator function $[u\geq 1]$은 $u\geq 1$일 경우 1, 그렇지 않으면 0을 출력한다. Background는 모두 0으로 처리하며 따라서 이에 대한 $L_\text{loc}$는 무시한다. $L_\text{loc}$는 다음과 같이 정의된다:이 때 smooth 함수는 다음과 같은 robust $L_1$ loss이며 R-CNN과 SPPnet에서 쓰인 $L_2$ loss보다 이상치에 덜 민감하다:Regression target이 제한되지 않는 경우 $L_2$ loss로 훈련시킬 때 gradient가 급격히 커지지 않도록 신중한 조정이 필요하다. Smooth 함수는 이러한 상황을 피할 수 있다.
- $$
\begin{equation}
\text{smooth}_{L_1}(x)=
\begin{cases}
0.5x^2 & \text{if } |x|<1, \
|x|-0.5 & \text{otherwise,}
\end{cases}
\end{equation}
$$ - $$
\begin{equation}
L_\text{loc}(t^u,v)=\sum_{i\in{\text{x,y,w,h}}} \text{smooth}_{L_1}(t_i^u-v_u),
\end{equation}
$$ - 하이퍼 파라미터 $\lambda$는 두 손실 간의 균형을 조절한다. 모든 실험에서는 $\lambda=1$로 두었다.
- Ground-truth regression target $v_i$는 평균 0, 표쥰편차 1로 정규화되었다.
- $$
\begin{equation}
L(p,u,t^u,v)=L_\text{cls}(p,u)+\lambda[u\geq 1]L_\text{loc}(t^u,v).
\end{equation}
$$
Mini-batch sampling
- Fine-tuning에서 각 SGD 미니배치는 무작위로 뽑힌 $N=2$ 이미지로 만들어졌다. 이 미니배치는 크기 $R=128$로 각 이미지에서 64개의 RoI를 샘플링하여 구성되었다.
- Foreground ($u \geq 1$) : R-CNN처럼 ground-truth와 0.5 이상의 IoU overlap을 가진 object proposal에서 RoI의 25%를 가져왔다.
- Background ($u=0$) : SPPnet처럼 최대 IoU overlap이 $[0.1, 0.5)$인 object proposal에서 나머지 RoI를 가져왔다. Lower threshold 0.1은 hard example mining을 통한 heuristic이다.
- 훈련 동안 이미지들은 0.5의 확률로 horizontal flip이 적용된다.
Back-propagation through RoI pooling layers
- 역전파는 RoI pooling layer에서 미분을 수행한다. 명확성을 위해 각 미니배치당 하나의 이미지만을($N=1$) 사용한다고 가정했지만, 순방향 전파가 모든 이미지를 독립적으로 처리하기 때문에 $N$의 확장은 간단하다.
- $x_i\in \mathbb{R}$를 RoI pooling layer로의 $i$번째 활성화 입력, $y_{rj}$를 $r$번째 RoI에 의한 $j$번째 레이어 출력이라고 하자.
- RoI pooling layer는 $ y_{ri}=x_{i^* (r,j)} $를 계산한다. 이 때 $i^* (r,j)= \arg max_{i'\in\mathcal{R}(r,j)}x_{i'}$이며 $\mathcal{R}(r,j)$는 출력 단위 $y_{rj}$가 max pooling되는 sub-window의 입력 인덱스 집합이다. 하나의 $x_i$는 여러 다른 출력 $y_{rj}$에 할당될 수 있다.
- RoI pooling layer의
backwards함수는 손실 함수의 각 입력 변수 $x_i$에 따른 편미분을 계산한다: - $$
\begin{equation}
\dfrac{\partial L}{\partial x_i}=\sum_r\sum_j[i=i^*(r,j)]\dfrac{\partial L}{\partial y_{rj}}.
\end{equation}
$$ - 즉, 각 미니배치 RoI $r$과 각 pooling 출력 단위 $y_{rj}$에 대해 $i$가 max pooling에 의해 $y_{rj}$에 대해 선택된 argmax일 때 편미분 $\partial L / \partial y_{rj}$가 $\partial L / \partial x_i$에 축적된다는 것이다.
- 편미분 $\partial L / \partial y_{rj}$은 RoI pooling layer의 맨 위에서
backwards함수에 의해 계산된다.
2.4. Scale invariance
- 논문에서는 스케일 불변 객체 탐지 를 달성하는 두 가지 방법을 탐구한다.
- Brute force : 훈련과 테스트 동안 각 이미지가 사전에 정의된 픽셀 크기로 처리된다. 신경망은 훈련 데이터로부터 스케일 불변 객체 탐지를 직접적으로 학습한다.
- Image pyramid : 다중 스케일 접근으로, 신경망에서 스케일 불변에 근사할 수 있다. 테스트 단계에서, image pyramid는 각 object proposal을 대략적으로 스케일 정규화하는데 사용된다. 훈련에서는 이미지가 샘플링될 때마다 무작위로 pyramid의 스케일을 샘플링한다.
3. Fast R-CNN detection
- 신경망은 입력으로 이미지 (또는 이미지 리스트로 인코딩된 image pyramid) 와 점수를 매길 $R$개의 object proposal 리스트를 받는다.
- 각 테스트 RoI $r$에 대해, 순방향 전파는 클래스 사후 확률 분포 $p$와 $r$의 ($K$ 클래스에 대해) 예측 bounding-box offset 집합을 출력한다.
- 각 객체 클래스 $k$에 대해 추정된 확률 $\Pr(\text{class}=k\ |\ r) \overset{\Delta}{=} p_k$을 사용하여 $r$에 탐지 신뢰도를 할당한다.
- 이후 R-CNN의 설정과 알고리즘을 사용하여 각 클래스에 대해 비최대 억제를 독립적으로 수행한다.
3.1. Truncated SVD for faster detection
- 전체 이미지에 대한 분류에서는 FC layer를 계산하는 시간이 conv layer를 계산하는 시간에 비해 적다.
- 이에 반해, 탐지 작업에서는 처리할 RoI의 수가 많고, 순방향 전파 시간의 거의 절반 가까이 FC layer를 계산하는데 소요된다.
- 이 문제는 FC layer를 truncated SVD로 압축하여 손쉽게 해결할 수 있다.
- $u \times v$의 가중치 행렬 $W$로 파라미터화되는 레이어는 SVD를 사용하여 다음과 같이 근사적으로 분해할 수 있다:
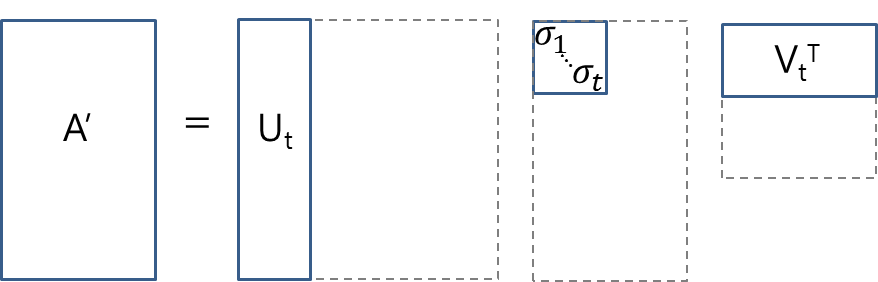 Truncated SVD. 출처 : [https://darkpgmr.tistory.com/106] (https://darkpgmr.tistory.com/106)
Truncated SVD. 출처 : [https://darkpgmr.tistory.com/106] (https://darkpgmr.tistory.com/106)
- $$ W \approx U\Sigma_tV^T $$
- $U$는 $W$의 첫 $t$개의 left-singular vector를 포함하는 $u \times t$ 행렬이다.
- $\Sigma_t$는 $W$의 상위 $t$개의 signular value를 포함하는 $t \times t$ 대각행렬이다.
- $V$는 $W$의 첫 $t$개의 right-singular vector를 포함하는 $v \times t$ 행렬이다.
- Truncated SVD는 파라미터 수를 $uv$에서 $t(u+v)$로 줄여준다. $t$가 $\min(u,v)$보다 매우 적으면 이 파라미터 수가 매우 줄어들 것이다.
- 신경망을 압축하기 위해, $W$에 해당하는 하나의 FC layer를 서로 비선형성을 가지지 않는 두 개의 FC layer로 대체한다.
- 첫 번째 레이어는 편향 없이 가중치 행렬 $\Sigma_tV^T$을 사용한다.
- 두 번째 레이어는 $W$에 해당하는 편향과 함께 $U$를 사용한다.

Figure 2. Timing for VGG16 before and after truncated SVD. Before SVD, fully connected layers fc6 and fc7 take 45% of the time.
4. Main results
- 세 가지 주된 결과가 이 논문의 기여의 근거이다.
- VOC07, 2010, 그리고 2012에서 SOTA mAP 달성
- R-CNN과 SPPnet보다 따른 훈련과 테스트
- VGG16의 conv layer를 fine-tuning하여 mAP 향상
4.5. Which layers to fine-tune?
- 상대적으로 얕은 신경망에 대하여 FC layer만을 fine-tuning하는 것은 좋은 정확도를 보이기에 충분했다.
- 이에 대해 논문에서는 매우 깊은 신경망에 대해서는 이런 결과가 나오지 않을 것이라는 가설을 세웠다.
- VGG16에서 conv layer를 fine-tuning하는 것이 중요하다는 것을 입증하기 위해, 13번째 conv layer를 고정하여 FC layer만 학습하도록 Fast R-CNN을 fine-tuning했다.
- 실험 결과 가설이 옳았다. 매우 깊은 훈련망에서는 RoI pooling layer로 훈련시키는 것이 중요하다.

Table 5. Effect of restricting which layers are fine-tuned for VGG16. Fine-tuning ≥ fc6 emulates the SPPnet training algorithm [11], but using a single scale. SPPnet L results were obtained using five scales, at a significant (7×) speed cost.
- 그렇다고 모든 conv layer가 fine-tuning되어야 한다는 것은 아니다.
- 더 작은 신경망 (S와 M) 에서 conv1이 일반적, 독립적이었고 conv1의 학습 여부는 mAP에서 의미있는 영향을 주지 않았다.
- VGG16의 경우 conv3_1 이상의 레이어만 (13개 중 9개) 업데이트하면 된다.
5. Design evaluation
- 이 논문에서는 Fast R-CNN이 R-CNN과 SPPnet과 어떻게 다른지 이해하고, 설계를 평가하기 위해 실험을 진행했다.
5.1. Does multi-task training help?
- Multi-task training은 순차적으로 훈련된 작업 파이프라인의 관리를 피할 수 있어 편리하다. 그런데 여기서의 작업이 공유되는 representation(ConvNet)을 통해 서로 영향을 미치기 때문에 결과를 향상시킬 가능성을 가지고 있다.
- 이를 확인해보기 위해, 논문에서는 신경망을 다르게 훈련 및 테스트해 결과를 비교했다. 각 그룹의 열 별로 다른 방식이 나열되어 있다.
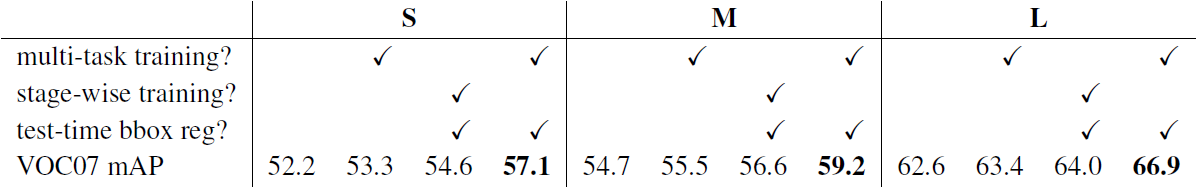
Table 6. Multi-task training (forth column per group) improves mAP over piecewise training (third column per group).
- 분류 손실 $L_\text{cls}$만을 사용하는 ($\lambda=0$) baseline network를 훈련시켰다. 이 신경망에서는 bounding-box regressor가 없다.
- Multi-task loss를 사용하여 ($\lambda = 1$) 신경망을 훈련시켰으나, 테스트 단계에서는 bounding-box regression을 제외시켰다. 이는 신경망의 분류 정확도를 분리하고 baseline network와 제대로 된 비교를 가능하게 한다.
- 1의 baseline network에 bounding-box regression layer를 더하고 모든 다른 신경망 파라미터를 고정시킨채 $L_\text{loc}$로 훈련시킨다. 이는 stage-wise training의 결과를 보여준다.
- 실험 결과를 보았을 때, Multi-task를 이용할 때 분류 정확도를 향상시킨다는 것을 알 수 있다.
5.2. Scale invariance: to brute force or finesse?
- 스케일 불변 객체 탐지를 위한 두 가지 전략, brute-force learning (single scale)과 image pyramids (multi-scale)을 비교했다.
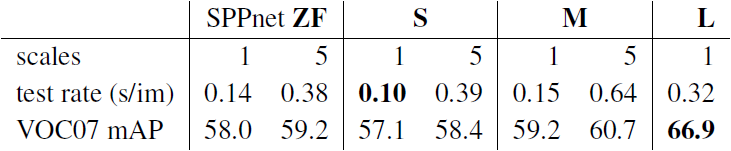
Table 7. Multi-scale vs. single scale. SPPnet ZF (similar to model S) results are from [11]. Larger networks with a single-scale offer the best speed / accuracy tradeoff. (L cannot use multi-scale in our implementation due to GPU memory constraints.)
- 실험 결과 놀랍게도 단일 스케일 탐지가 다중 스케일 탐지와 거의 같은 성능을 냈다.
- 단일 스케일 처리는 특히 매우 깊은 모델의 경우 속도와 정확도 간의 최상의 균형을 이룬다.
- 따라서 이 sub-section 외의 모든 실험은 단일 스케일을 사용했다.
5.3. Do we need more training data?
- 좋은 object detector는 더 많은 훈련 데이터가 주어져도 성능이 향상되어야 한다.
- VOC10과 2012에서 합친 21.5k 이미지 데이터셋을 만들어내어 실험을 진행했다. 이러한 데이터셋으로 훈련한 결과 VOC10와 2021에 대해 mAP가 각각 66.1%에서 68.8%로, 65.7%에서 68.4%로 증가했다.
5.4. Do SVMs outperform softmax?
- Fast R-CNN은 R-CNN과 SPPnet에서의 one-vs-rest (OvR) linear SVM을 사용하지 않고 softmax classifier를 사용한다.
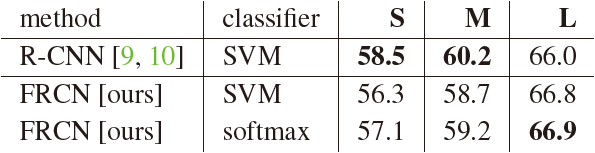
Table 8. Fast R-CNN with softmax vs. SVM (VOC07 mAP).
- 실험 결과 softmax가 미미하게 우세하며 이전의 multi-stage training에 비해 “one-shot” fine-tuning만으로 충분함을 보여준다.
- 논문에서는 OvR SVM과는 달리, softmax가 RoI scoring에서 클래스 간에 경쟁을 유발한다는 점을 주목하고 있다.
5.5. Are more proposals always better?
- Object detector는 사용하는 object proposal set가 sparse한지(selective search 등) dense한지(DPM 등)에 따라서 구분할 수 있다.
- Sparse proposal을 분류하는 것은 proposal 매커니즘이 classifier에 우선 평가할 작은 후보들을 남겨두고 방대한 수의 후보를 거부하는 일종의 cascade이다. (참고 : https://hohodu.tistory.com/14)
- 이 cascade는 DPM 탐지에 적용될 경우 탐지 성능이 향상된다.
- 논문에서는 이 proposal-classifier cascade가 Fast R-CNN 정확도를 향상시킨다는 증거를 찾았다.
- Selective search의 quality mode를 사용하여, 모델 ${M}$을 다시 훈련 및 테스트할 때마다 이미지당 1k~10k의 proposal을 sweep한다.
- Proposal이 순전히 계산적인 역할을 할 경우, 이미지당 proposal 수를 늘리는 것은 mAP를 감소시키지 않아야 한다.

Figure 3. VOC07 test mAP and AR for various proposal schemes.
- 실험 결과 더 많은 proposal을 사용하는 것이 정확도 개선에 도움을 주지 않는다는 것을 알 수 있다.
- Object proposal의 품질 측정의 SOTA는 Average Recall (AR) 로, 이미지당 고정된 수의 proposal을 사용할 때 R-CNN을 사용하는 몇 가지 proposal 방법의 mAP와 좋은 상관관계를 가진다. 하지만 이미지당 proposal의 수가 다르면 AR과 mAP는 상관관계를 가지지 않는다. 따라서 AR을 metric으로 사용하는 것은 신중해야 한다.
- 한편 이미지당 45k box의 (scale, position, aspect ratio에 대한) densely generated box를 사용한 Fast R-CNN도 조사했다.
- 이 dense set는 각 selective search box가 가까운 dense box로 대체되어도 mAP가 1%만 떨어질 정도로 풍부하다 (57.7%, 파란색 삼각형).
- Dense box에 대한 실험 결과는 selective search box의 결과와 다르게 나타났다.
- 2k의 selective search box로 시작해서, 1000 × {2, 4, 6, 8, 10, 32, 45} 개의 dense box 무작위 샘플을 추가해나가며 mAP를 측정했다.
- Dense box가 추가될 수록 mAP가 selective search box를 추가할 때보다 더 크게 떨어졌다.
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Mask R-CNN (0) | 2022.03.20 |
|---|---|
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] FPN : Feature Pyramid Network (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3) (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (0) | 2022.03.02 |
'컴퓨터비전 : CV/CNN based' Related Articles
more




Comments