
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- YAI 9기
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- cv
- transformer
- Fast RCNN
- NLP
- YAI 10기
- rl
- 컴퓨터 비전
- Perception 강의
- 자연어처리
- 강화학습
- 컴퓨터비전
- cl
- PytorchZeroToAll
- GaN
- RCNN
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- YAI 11기
- Googlenet
- Faster RCNN
- VIT
- 3D
- CS224N
- YAI 8기
- nerf
- 연세대학교 인공지능학회
- CS231n
- YAI
- CNN
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] FPN : Feature Pyramid Network 본문
FPN + RetinaNet (Focal Loss) - (1)
**YAI 9기 조용기님이 비전 논문 심화팀에서 작성한 글입니다.
FPN
Papers with Code - FPN Explained
1. Introduction

Featurized image pyramid
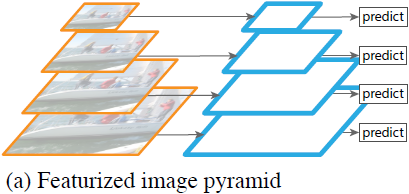
- 광범위한 스케일의 객체를 인식하는 것은 컴퓨터 비전에 있어 근본적인 도전 과제이다. 이에 대한 일반적인 해답은 Image pyramids에 만들어진 **feature pyramids (featurized image pyramids)**이다. - 이 pyramid는 객체의 스케일 변화가 pyramid 안에서의 level shift에 의한 offset이라는 점에서 스케일에 불변하다. - 따라서 모델은 position과 pyramid level을 훑으며 넓은 범위의 스케일에 대해서 객체를 탐지할 수 있다. - Hand-engineered features era, 즉 머신러닝을 주로 사용했을 때 (DPM) Featurized image pyramid가 활발하게 사용되었다.
Single feature map (CNN)
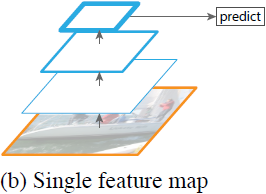
- Engineered feature는 곧 deep CNN (ConvNet)으로 계산된 feature로 대체되었다.
- ConvNet은 high level semantic representation이 가능하면서 스케일에 불변하므로 단일 입력 스케일에서 계산된 feature를 통한 인식 작업에 용이하다.
- 하지만 featurized image pyramid는 여전히 정확한 결과를 얻기 위해 필요하다.
- Featurized image pyramid의 장점은 모든 level에서 강력한 semantic을 가진 다중 스케일의 feature representation을 생성한다는 것이다.
- ConvNet은 high level semantic representation이 가능하면서 스케일에 불변하므로 단일 입력 스케일에서 계산된 feature를 통한 인식 작업에 용이하다.
- 그럼에도 level featurizing은 명백한 한계가 존재한다.
- 추론 시간이 상당히 증가하기 때문에, 실제 사용에서는 비실용적이다.
- Image pyramid에서 심층 신경망의 end-to-end 훈련은 메모리 측면에서 실행이 불가능하고 테스트 단에서만 사용이 가능하며, 그럴 경우 훈련/테스트 추론 사이에 불일치가 발생한다.
- 따라서 Fast/Faster R-CNN은 기본 설정에서 featurized image pyramid를 사용하지 않는다.
- 추론 시간이 상당히 증가하기 때문에, 실제 사용에서는 비실용적이다.
- 하지만, image pyramid가 다중 스케일 feature representation을 계산하는 유일한 방법은 아니다.
- Deep ConvNet은 레이어별로 feature hierarchy를 계산하며, subsampling layer로 인해 이 feature hierarchy는 고유한 다중 스케일의 pyramid 형태를 가진다.
- 이 feature hierarchy는 다양한 크기의 feature map을 만들어내는데, 이 map 사이에서는 서로 다른 depth에 의해 큰 semantic gap이 발생한다. 이 때 high-resolution map은 객체 인식을 위한 표현 능력이 좋지 않은 low-level feature를 가진다.
- Deep ConvNet은 레이어별로 feature hierarchy를 계산하며, subsampling layer로 인해 이 feature hierarchy는 고유한 다중 스케일의 pyramid 형태를 가진다.
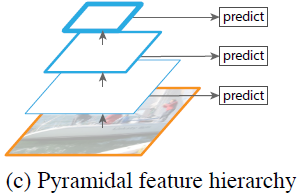
- Single Shot Detector (SSD)는 ConvNet의 pyramidal feature hierarchy를 featurized image pyramid처럼 사용한 초기 모델이다.
- 이상적으로, 이 pyramid는 순방향 전파에서 계산된 다양한 레이어의 다중 스케일 feature map을 재사용하므로 비용이 들지 않는다.
- 하지만 low level feature를 사용하지 않기 위해 레이어의 재사용을 포기하고 신경망의 높은 부분에서 여러 새 레이어를 추가해 pyramid를 구축했다.
- 따라서 작은 객체 감지에 중요한 high-resolution map을 재사용할 수 없게 된다.
Feature Pyramid Network
- 이 논문의 목표는 ConvNet의 feature hierarchy를 자연스럽게 활용하는 동시에 모든 스케일에서 강력한 semantic을 가지는 feature pyramid를 만드는 것이다.
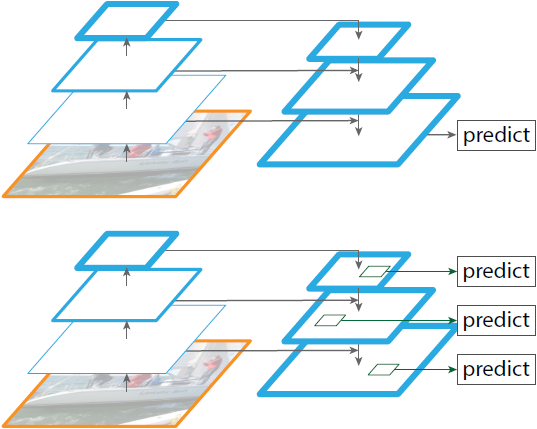
- 논문에서는 이 목표를 위해 top-down path와 lateral connection을 통해 low-resolution, strong semantic을 갖는 feature와 high-resolution, weak semantic을 갖는 feature를 결합하는 아키텍처를 사용한다.
- 이 아키텍처는 모든 level에서 풍부한 semantic을 가지며 단일 입력 이미지 스케일에 빠르게 만들어지는 feature pyramid로, 표현력과 속도, 메모리를 희생하지 않고 featurzied image pyramid를 대체할 수 있다.
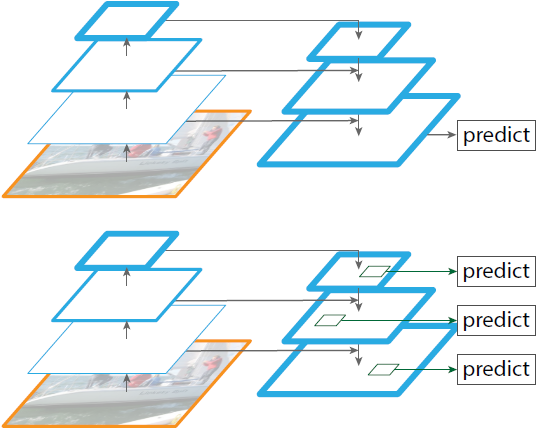
- Top-down과 skip connection을 채택한 유사 아키텍처들이 인기가 있었다.
- 이들의 목표는 예측이 진행될 하나의 fine resolution, high level feature map 을 만드는 것이다.
- 이와는 다르게 FPN에서는 각 level에서 서로 독립적으로 예측이 만들어지는 feature pyramid 아키텍처를 활용한다.
- 이 구조는 image pyramid와는 다르게 모든 스케일에 대해 end-to-end로 훈련될 수 있으며 훈련/테스트 때 일관되게 사용될 수 있다.
2. Related work
Hand-engineered features and early neural networks
- SIFT feature는 원래 스케일 공간 극값에서 추출되어 feature point matching에 사용되었다.
- HOG feature와 SIFT feature는 전체 image pyramid에서 조밀하게 계산되었으며, 이미지 분류, 객체 탐지, human pose estimation 등의 수많은 작업에 사용되었다.
- Featurized image pyramid를 빠르게 계산하는 방법도 상당한 관심이 있었다. Dollár et al.은 희소 샘플링 pyramid 계산으로 missing level을 보간해 빠른 연산을 보여주었다.
- HOG와 SIFT 이전의 ConvNet을 사용한 초기 얼굴 탐지 논문은 여러 스케일에서 얼굴을 탐지하기 위해 image pyramid를 통해 얕은 신경망을 계산했다.
Deep ConvNet object detectors
- Deep ConvNet의 개발로 인해 OverFeat과 R-CNN같은 object detector는 극적인 정확도 향상을 보여주었다.
- OverFeat : Image pyramid에서 ConvNet을 sliding window detector로 적용하는 초기 신경망 얼굴 인식과 비슷한 전략을 채택했다.
- R-CNN : 각 proposal이 ConvNet으로 분류하기 전에 스케일 정규화되는 region proposal에 기반한 전략을 채택했다.
- SPPnet : Region-based detector가 단일 이미지 스케일에서 추출된 feature map에서 더 효과적으로 적용될 수 있음을 입증했다.
- Fast/Faster R-CNN과 같은 보다 정확한 탐지 방법은 정확도와 속도의 좋은 트레이드오프를 제공하므로 단일 스케일 계산을 사용한다. 하지만 다중 스케일 탐지가 여전히 작은 객체에 대해 더 나은 성능을 보여준다.
Methods using multiple layers
- 최근의 여러 접근 방식들은 ConvNet의 여러 레이어를 사용하여 탐지와 세그멘테이션 작업을 개선했다.
- FCN : 시멘틱 세그멘테이션 계산을 위해 다중 스케일에서 각 카테고리 부분 점수를 합한다. Hypercolumns는 객체 인스턴스 세그멘테이션에서 비슷한 방법을 사용한다.
- 몇 가지 다른 접근 방법 (HyperNet, ParseNet, ION)은 예측 계산 전에 feature들을 연결하며, 이는 변환된 feature들을 합하는 것과 같다.
- SSD와 MS-CNN : Feature나 score를 결합하지 않고 feature hierarchy의 여러 레이어에서 객체를 예측한다.
- 한편 lateral/skip connection을 사용하여 resolution과 semantic level 전반에 걸쳐 low level feature map을 연결하는 방법이 있었다.
- 세그멘테이션 : U-Net, SharpMask
- 얼굴 탐지 : Recombinator networks
- 특징점(keypoint) 예측 : Stacked Hourglass networks
- Ghiasi et al.은 점진적으로 세그멘테이션을 개선하기 위해 FCN에 대한 Laplacian pyramid presentation을 소개한다.
- 이러한 방법들이 pyramid 모양의 아키텍처를 채택했지만, 모든 level에서 예측이 독립적으로 만들어지는 featurized image pyramid와는 다르다. Image pyramid는 여전히 여러 스케일에서 객체를 인식하는데 필요하다.
3. Feature Pyramid Networks
- 이 논문의 목표는 ConvNet의 low level부터 high level까지의 semantic을 가진 pyramidal feature hierarchy를 활용하고, 전체에 걸쳐 high level semantic을 가지는 feature pyramid를 구축하는 것이다.
- Feature Pyramid Network (FPN)는 범용적으로 쓰일 수 있으며, 이 논문에서는 sliding window proposer (Region Proposal Network, RPN)와 region-based detector (Fast R-CNN)에 주목한다.
- FPN은 임의 크기의 단일 스케일 이미지를 입력으로 받고, full convolutaion 방식으로 여러 level에 비례적으로 feature map을 출력한다.
- 이 과정은 backbone의 convolutional architecture와 독립적이며, 논문에서는 ResNet을 사용했다.
- Pyramid 구성은 bottom-up pathway, top-down pathway, 그리고 lateral connection을 포함한다.
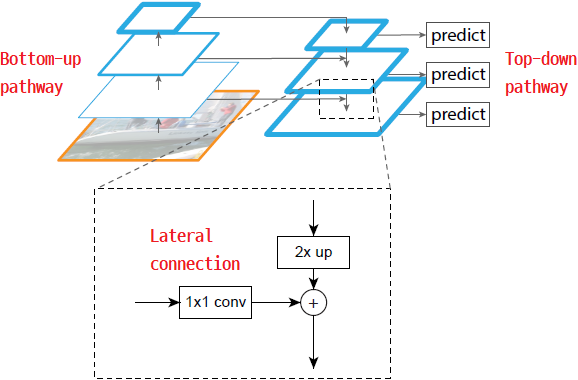
Bottom-up pathway
- Bottom-up pathway (상향식 경로)는 backbone ConvNet의 순방향 계산으로, scaling step이 2인 (즉 feature map이 1/2씩 작아지는) 여러 스케일의 feature map을 포함하는 feature hierarchy를 계산한다.
- 같은 크기의 map 출력을 만들어내는 레이어들을 같은 network stage에 속해 있다고 부른다.
- Feature pyramid에서는 각 stage마다 하나의 pyramid level을 정의한다.
- 각 stage의 마지막 레이어 출력이 stage에서 가장 강력한 feature를 가지므로 pyramid에 사용할 feature map의 reference set로 선택된다.
- ResNet에서는 출력 feature activation으로 각 stage의 마지막 residual block을 사용했다.
- 이 마지막 residual block들의 conv2, conv3, conv4, conv5 출력들을 ${C_2,C_3,C_4,C_5}$로 표시한다. 각각 입력 이미지에 대해 ${4,8,16,32}$의 stride를 가진다.
- conv1은 차지하는 메모리가 커 pyramid에 포함하지 않았다.
Top-down pathway and lateral connections
- Top-down pathway (하향식 경로)는 더 높은 pyramid level로 부터 coarser space, stronger semantic을 가지는 feature map을 업샘플링하여 higher resolution의 feature를 만들어낸다.
- 이 feature들은 lateral connection을 통해 bottom-up pathway의 feature를 받아 개선된다.
- 각 lateral connection은 bottom-up pathway와 top-down pathway의 같은 크기의 feature map을 병합한다.
- Bottom-up feature map은 lower level의 semantic을 가지지만, activation이 더 정확히 localize된다.
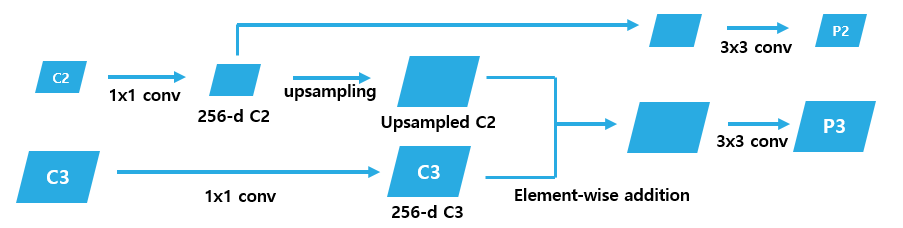
- Top-down feature map $P_k$ (${P_2, P_3, P_4, P_5}$)를 만드는 과정은 다음과 같다:
- 각 $C_k$에 1 × 1 convolution을 적용하여 $d=256$ 채널로 만든다.
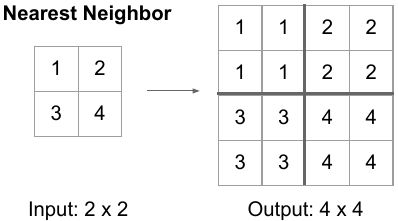
- 대응되는 $C_k$보다 coarser-resolution을 가진 feature map $C_{k-1}$에 2× 업샘플링을 적용한다 (단순화를 이용하여 nearest neighbor upsampling을 사용한다).
- 업샘플링된 $C_{k-1}$과 $C_k$를 element-wise addition으로 병합한다.
- 병합된 각 feature map에 3 × 3 convolution을 적용하여 업샘플링의 앨리어싱 효과를 없앤 $P_k$를 만든다.
- 각 $C_k$에 1 × 1 convolution을 적용하여 $d=256$ 채널로 만든다.
- Pyramid의 모든 level이 기존의 featurized image pyramid와 같이 공유되는 classifier/regressor를 사용하기 때문에, 모든 feature map에서 feature의 차원(채널 수, $d$로 표시)을 수정했다. 이 논문에서 $d=256$이며, 따라서 모든 extra convolutional layer는 256 채널의 출력을 가진다.
- 이러한 설계는 매우 단순하게 구성되며, 이로 인해 FPN은 많은 디자인 선택에 대하여 강력하다고 할 수 있다.
4. Applications
- FPN은 deep ConvNet에 feature pyramid를 구축하는 일반적인 솔루션이다. 이 section에서는 bounding box proposal generation을 위한 RPN과 object detection을 위한 Fast R-CNN에 FPN을 적용했다.
- FPN의 단순함과 효율성을 입증하기 위해, RPN과 Fast R-CNN을 feature pyramid에 적용시킬 때 최소한의 수정을 가했다.
4.1. Feature Pyramid Networks for RPN
- RPN은 sliding-window를 사용하는 class-agnostic object detector이다.
- class-agnostic detector : 영상에서 classification 정보 없이 foreground object 자체만 찾아내는 detector (참고 https://cvml.tistory.com/3).
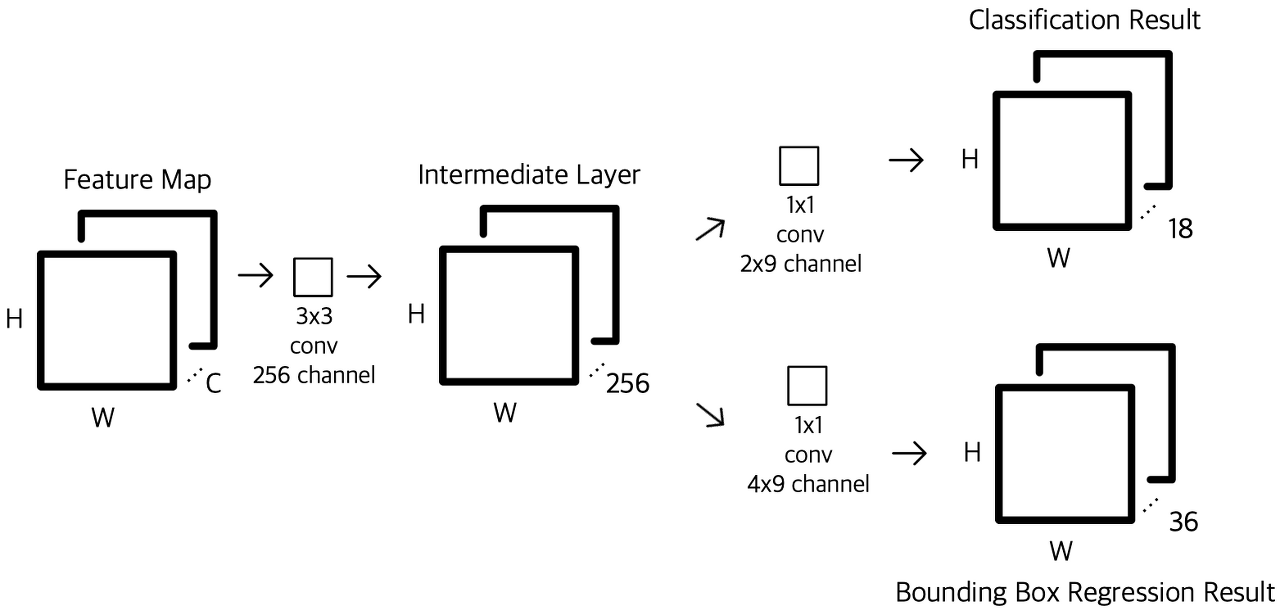
- 원래의 RPN 설계에서는 feature map 위의 3 × 3 sliding window에서 objectness binary classification과 bounding box regression을 수행한다.
- 이는 하나의 3 × 3 convolutional layer와, 이어지는 classification과 regression에 대한 2개의 1 × 1 convolution의 형태로 구현되며 이러한 구조를 network head라고 부른다.
- Objectness criterion과 bounding box regression target은 일련의 reference box인 anchor에 대해 정의된다.
- Anchor는 다양한 모양의 객체에 대응하기 위한 사전정의된 다중 스케일 및 종횡비의 box이다.
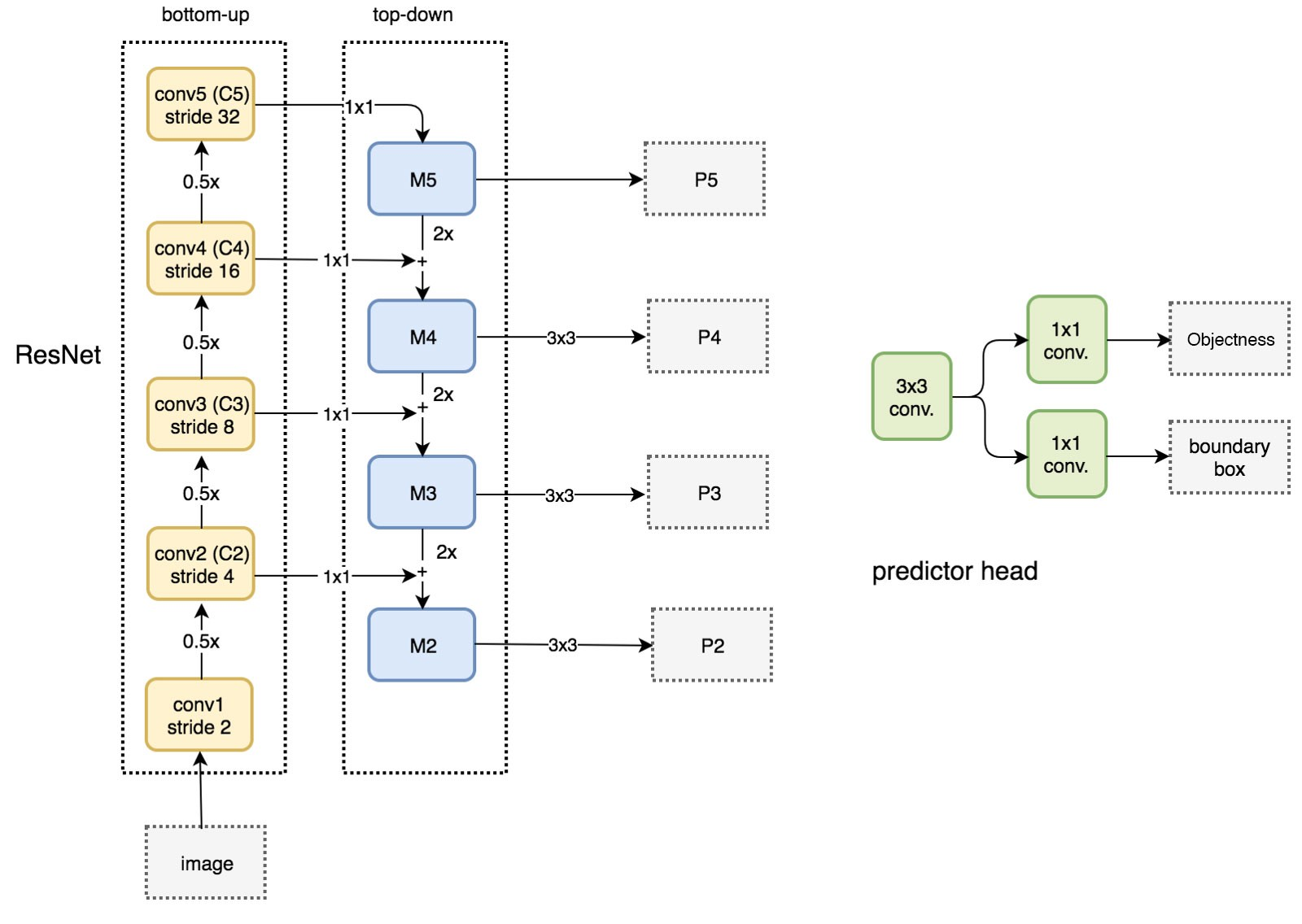
- 이 논문에서는 단일 스케일의 feature map을 FPN으로 바꾸어 RPN을 사용했다.
- Network head를 feature pyramid의 각 level에 붙인다.
- 모든 pyramid level에서 head를 sliding하므로, 하나의 level이 여러 스케일의 anchor를 가질 필요가 없다. 따라서 각 level에 단일 스케일의 anchor를 할당했다.
- ${P_2, P_3, P_4, P_5, P_6}$에 대해 각각 ${32^2,64^2,128^2,256^2,512^2}$픽셀의 영역을 가지는 anchor를 정의했으며 각 level마다 ${1:2,1:1,2:1}$의 종횡비를 사용해, pyramid를 통틀어 총 15개의 anchor가 존재한다.
- 각 anchor에 대한 훈련 레이블을 ground-truth bounding box와의 IoU ratio에 기반하여 할당했다.
- 양성 레이블 : 주어진 ground-truth box와 가장 높은 IoU를 가지거나 임의의 ground-truth box와 0.7보다 큰 IoU를 가지는 샘플.
- 음성 레이블 : 모든 ground-truth box와 0.3 보다 작은 IoU를 가진 샘플.
- Ground-truth box는 pyramid level에 (스케일을 이용해) 직접적으로 할당되지 않았으며, pyramid level에 할당된 anchor와 연결되었다.
- Network head의 파라미터는 모든 feature pyramid level 사이에 공유되는데, 파라미터가 공유되지 않는 경우에서도 비슷한 정확도를 보였는데, 이는 pyramid의 모든 level이 비슷한 sematic을 공유함을 의미한다.
4.2. Feature Pyramid Networks for Fast R-CNN
- Fast R-CNN은 Region-of-Interest (RoI) pooling을 사용하여 feature를 추출하는 region-based object detector이다.
- 일반적으로 단일 스케일 feature map에서 수행 된다.
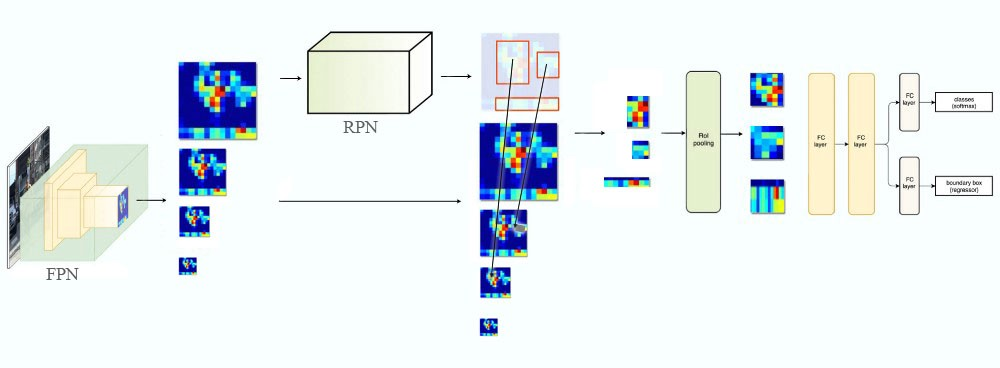
- 이 논문에서는 다양한 스케일의 RoI를 대응되는 pyramid level에 할당하여 FPN을 적용했다.
- Feature pyramid를 image pyramid에서 만들어진 것으로 볼 수 있으므로 image pyramid에서 region-based detector의 할당 전략을 적용할 수 있다.
- 너비 $w$, 높이 $h$의 RoI를 feature pyramid의 level $P_k$에 다음과 같이 할당한다:
\begin{equation}
k=\lfloor k_0 + \log_2(\sqrt{wh}/224)\rfloor.
\end{equation}
$$- 크기 224는 표준 ImageNet 사전훈련 크기이고 $k_0$는 $w \times h = 224^2$의 RoI가 매핑되어야 하는 target level이다.
- $C_4$를 단일 스케일 feature map으로 사용하는 ResNet 기반 Faster R-CNN과 비슷하게 $k_0=4$로 두었다.
- 직관적으로 보면, Eqn. (1)은 RoI의 스케일이 작아질 경우 finear resolution level에 매핑 되어야 함을 의미한다.
- 이 논문에서는 predictor head (Fast R-CNN에서는 클래스별 classifier와 bounding box regressor)를 모든 level의 모든 RoI에 연결했다. 이때 predictor head는 level에 상관 없이 모두 파라미터를 공유한다.
5. Experiments on Object Detection
- 모든 backbone은 Imagenet1k 분류 세트로 사전훈련된 후 탐지 데이터셋에서 미세조정되었다.
- ResNet-50과 ResNet-101 모델을 사용했다.
5.1. Region Proposal with RPN
5.1.1 Ablation Experiments
Comparions with baselines
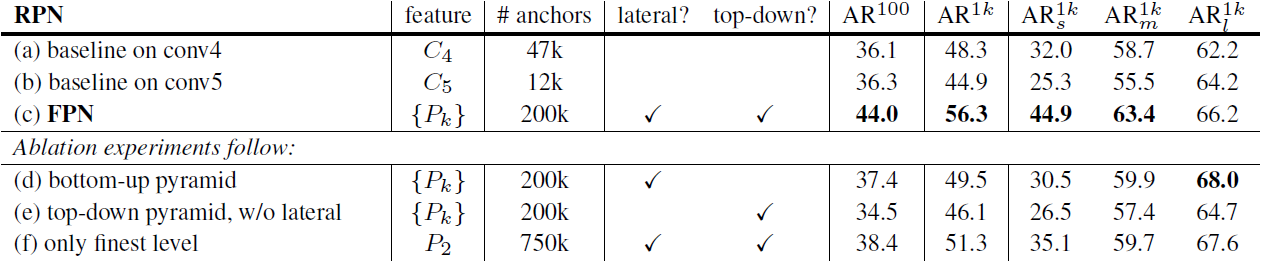
- 원래의 RPN과의 공정한 비교를 위해 $C_4$ 또는 $C_5$의 단일 스케일 map을 사용한 사용한 두 가지 baseline(Table 1(a, b))을 실행했다.
- Table 1의 (b)는 (a)에 비해 얻는 이득이 없으며, 이는 resolution과 sematic 사이의 trade-off 때문이다.
- RPN에 FPN을 적용하는 것(Table 1(c))은 AR 점수를 상당히 증가시켰다.
- FPN이 객체 스케일 변화에 대한 RPN의 robustness를 향상시켰다고 볼 수 있다.
How important is top-down enrichment?
- Table 1(d)는 top-down pathway를 제외한 feature pyramid의 결과를 보여주고 있다.
- 이 모델에서는 bottom-up pyramid에 1 × 1 lateral connection과 3 × 3 convolution을 붙였다.
- 이러한 아키텍처는 Fig. 1(b)의 pyramidal feature hierarchy를 재사용하는 효과를 시뮬레이션한다.
- 결과는 RPN baseline과 비슷하며, FPN에 비해서는 매우 뒤쳐져 있다.
- Bottom-up pyramid의 여러 level 사이 커다란 semantic gap이 존재하기 때문이다.
- Head 파라미터의 공유가 없는 변종도 평가했는데, 비슷하게 나쁜 성능을 보였다.
How important are lateral connections?
- Table 1(e)는 1 × 1 lateral connection이 없는 top-down feature pyramid의 결과를 보여주고 있다.
- 이 방식은 strong semantic, fine resolution의 feature를 가지지만, 이 feature의 location이 정확하지 않다.
- Feature map이 몇 번에 걸쳐 다운샘플링 및 업샘플링되었기 때문이다.
- FPN이 이 방식에 비해 10점의 $\text{AR}^{1k}$ 점수를 더 얻었다.
How important are pyramid representations?
- Pyramid representation에 의존하는 대신, (pyramid의 finest level인) $P_2$의 strong semantic을 가진 feature map에 head를 연결할 수 있다.
- 단일 스케일의 baseline과 비슷하게 모든 anchor를 $P_2$ feature map에 할당했다.
- 이 변종(Table 1(f))의 결과는 baseline보다 우세했지만 FPN에 비해 뒤쳐졌다.
- RPN은 고정된 window 크기를 가진 sliding window detector이므로, FPN이 pyramid level을 따라 스캔하면 스케일 분산에 대한 robustness를 향상시킬 수 있다.
- $P_2$만 사용하면 large resolution때문에 더 많은 anchor가 필요하며, 이는 많은 수의 anchor가 정확도 향상에 충분하지 않음을 의미한다.
- RPN은 고정된 window 크기를 가진 sliding window detector이므로, FPN이 pyramid level을 따라 스캔하면 스케일 분산에 대한 robustness를 향상시킬 수 있다.
5.2. Object Detection with Fast/Faster R-CNN
5.2.1 Fast R-CNN (on fixed proposals)

- Region-based detector에서 FPN의 영향을 더 잘 조사하기 위해 고정된 proposal 세트의 Fast R-CNN ablation을 수행했다.
- 단순함을 위해 특정한 경우를 제외하고 Fast R-CNN과 RPN 사이 feature를 공유하지 않았다.
- Table 2(c)의 FPN을 적용한 Fast R-CNN이 baseline (Table 2(a, b))와 비교했을 때 더 높은 AP 점수를 보여준다.
- 논문의 feature pyramid가 region-based object detector의 단일 스케일 feature에 우세함을 보여준다.
- $P_2$의 단일 feature map만을 사용한 결과(Table 2(f))는 모든 pyramid level을 사용한 결과에서 크게 나쁘지 않았다.
- 이는 RoI pooling이 region의 스케일에 덜 민감한 warping-like operation이기 때문이다.
- 이 성능은 ${P_k}$의 RPN proposal을 기반으로 하므로 pyramid representation의 이점을 이미 얻었다.
5.2.2 Faster R-CNN (on consistent proposals)

- Faster R-CNN 시스템에서는 feature의 공유를 위해 RPN과 Fast R-CNN이 같은 network backbone을 사용해야 한다. - Table 3는 RPN과 Fast R-CNN의 일관된 backbone 아키텍처를 사용한 FPN과 두 baseline을 비교한다.
Sharing features
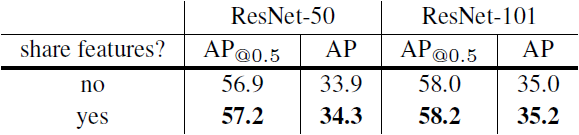
- 단순함을 위해 RPN과 Fast R-CNN 사이 feature를 공유하지 않았다.
- Feature sharing은 정확도를 조금 향상시키는 결과를 가져왔으며, 테스트 시간도 줄여주었다.
Running time
- FPN이 적용된 모델은 추가적인 레이어로 인한 적은 추가 비용이 들지만 더 가벼운 weight head를 가진다.
5.2.3 Comparing with COCO Competition Winners
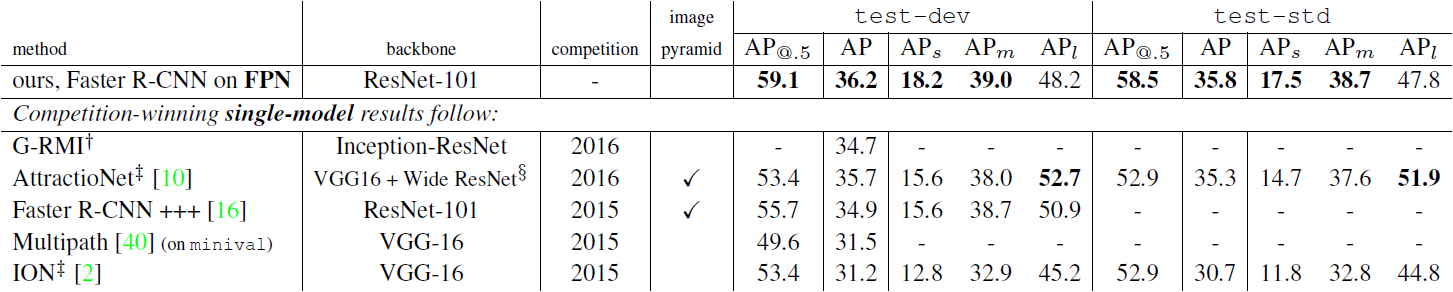
- 비교 결과, FPN 모델이 다른 경쟁 논문의 강력하고 고도로 설계된 모델들을 능가하는 모습을 보여주었다.
- 이 논문의 방법은 image pyramid 없이 오직 단일 스케일의 이미지 입력만을 사용하면서도 작은 스케일의 객체에 대해 뛰어난 AP를 가지는데, 이전의 방법들로는 high resolution의 이미지 입력이 있어야만 가능했다.
6. Extensions: Segmentation Proposals
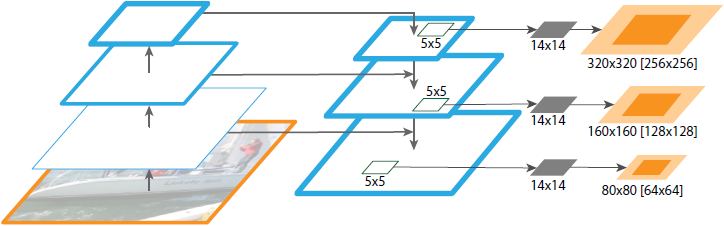
- FPN은 일반적인 pyramid representation이며 객체 탐지 이외의 응용 작업에도 사용이 가능하다.
- DeepMask/SharpMask 프레임워크는 크롭된 이미지에 대해 instance segment와 objectness score를 예측하도록 훈련된다.
- 테스트 시간에, 이 모델들은 convolution을 수행하여 이미지에 대한 dense proposal을 생성한다.
- 이 때 다중 스케일에 대한 segment를 생성하기 위해 image pyramid가 불가피하다.
6.1. Segmentation Proposal Results
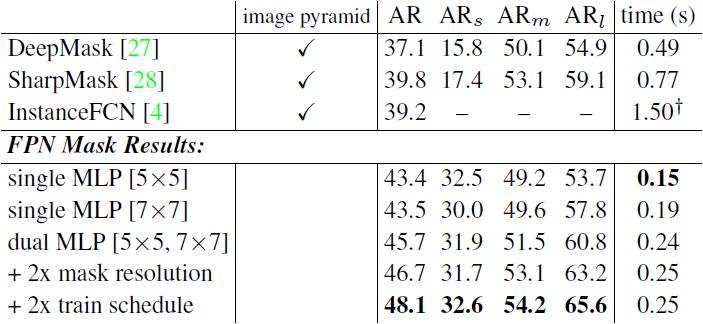
- 기존의 mask proposal 방법들은 조밀하게 샘플링된 image pyramid에 기반하여 계산 비용이 많이 들었다. - 논문의 FPN 기반 접근 방법은 근본적으로 빠르다. 이를 통해 논문의 모델이 일반적인 feature extractor이며 다른 다중 스케일 탐지 문제에서 image pyramid를 대체할 수 있음을 알 수 있다.
A. Implementation of Segmentation Proposals
- Object segment proposal을 효율적으로 만들기 위해 image-centric training strategy를 채택하여 FPN을 사용할 수 있다.
- FPN mask generation model은 DeepMask/SharkMask의 아이디어를 이용하지만, image pyramid가 아닌 feature pyramid에서 fully convolutional training을 수행한다.
- Feature map의 각 spatial position은 서로 다른 위치의 mask를 예측하는데 사용된다.
- 스케일 $P_k$에서 각 spatial position은 그 위치의 $2^k$ 픽셀 안에 중심이 있는 mask를 예측하는데 사용된다.
- 범위 안에 객체의 중심이 없다면 그 location은 음성으로 정의되고 (mask branch가 아닌) score branch에서 훈련된다.
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Mask R-CNN (0) | 2022.03.20 |
|---|---|
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3) (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (2) (0) | 2022.03.10 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (0) | 2022.03.02 |



