
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- YAI 10기
- nerf
- PytorchZeroToAll
- 컴퓨터비전
- GaN
- YAI 8기
- 강화학습
- CNN
- CS231n
- transformer
- cv
- YAI
- Googlenet
- RCNN
- YAI 11기
- rl
- Perception 강의
- cl
- 연세대학교 인공지능학회
- VIT
- 컴퓨터 비전
- CS224N
- 3D
- Fast RCNN
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- NLP
- Faster RCNN
- YAI 9기
- 자연어처리
- Today
- Total
목록컴퓨터비전 (21)
연세대 인공지능학회 YAI
U-Net: Convolutional Networks for Biomedical Image Segmentation ** YAI 10기 안정우님이 비전논문기초팀에서 작성한 글입니다. Abstact Present a network and training strategy that relies on the strong use of data augmentation Use available annotated samples more efficiently The architecture consists of a Contracting path and a symmetric Expanding path Contracting path Captures content Expanding path Enables precise local..
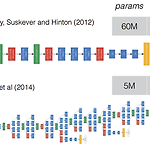 [논문 리뷰] GoogLeNet : Going deeper with convolutions
[논문 리뷰] GoogLeNet : Going deeper with convolutions
YAI 11기 최가윤님이 작성한 글입니다. [GoogLeNet] Going deeper with convolutions (2015 CVPR) Reference https://arxiv.org/pdf/1409.4842.pdf https://en.wikipedia.org/wiki/Gabor_filter [GoogLeNet (Going deeper with convolutions) 논문 리뷰]https://phil-baek.tistory.com/entry/3-GoogLeNet-Going-deeper-with-convolutions-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0 Abstract Improved utilization of the computing resources inside..
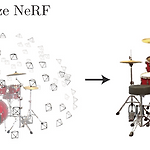 [논문 리뷰] NeRF : Representing scenes as Neural Radiance Fields for view synthesis
[논문 리뷰] NeRF : Representing scenes as Neural Radiance Fields for view synthesis
YAI 9기 박준영님이 나의야이아카데미아팀에서 작성한 글입니다. NeRF : Representing Scene as Neural Radiance Fields for View Synthesis [Mildenhall, Ben, et al. "Nerf: Representing scenes as neural radiance fields for view synthesis." Communications of the ACM 65.1 (2021): 99-106.](https://dl.acm.org/doi/abs/10.1145/3503250) Abstract 이 논문은 input으로 한정된 수의 3D scene을 획득, 이를 활용하여 continous volumetric scene function에 입각한 여러 방향에서..
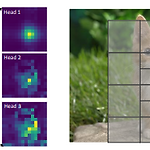 [논문 리뷰] Focal Self-attention for Local-Global Interactions in Vision Transformers
[논문 리뷰] Focal Self-attention for Local-Global Interactions in Vision Transformers
YAI 9기 김석님이 비전논문팀에서 작성한 글입니다. Focal Self-attention for Local-Global Interactions in Vision Transformers 0. Abstract 목적 Self attention을 통한 짧은 것에서부터 긴 단위까지 visual dependency를 모두 capture할 수 있도록 설계하면서도 quadratic computational overhead로 인한 resolution이 높은 task에 관해서 어려운 상황도 극복할 수 있어야 함 Method SoTA model의 경우 coarse-grain이나 fine-grained local attention을 적용하여 computational & memory cost와 성능을 개선하는 방식을 채택함 ..
 [논문 리뷰] Mask R-CNN
[논문 리뷰] Mask R-CNN
Mask R-CNN * YAI 9기 박찬혁님이 비전 논문 심화팀에서 작성한 글입니다. 논문 Mask R-CNN Instance Segmentation 이번 논문인 Mask RCNN은 Instance segmentation을 task로 한다. Deeplab이 목적으로 했던 semantic segmentation은 이미지 속의 객체들에 대한 segmentation과 classification은 진행하지만 서로 다른 객체가 같은 클래스에 속해있다면 구분하지 못했다. 하지만 Instance segmentation은 오른쪽의 사진과 같이 같은 클래스의 다른 객체들을 다 구분할 수 있다. R-CNN R-CNN은 CNN을 object detection에 최초로 적용시킨 모델이다. RCNN은 두가지 stage로 나누어..
 Instant Neural Graphics Primitives with Multiresolution Hash Encoding
Instant Neural Graphics Primitives with Multiresolution Hash Encoding
Instant Neural Graphics Primitives with Multiresolution Hash Encoding https://arxiv.org/abs/2201.05989 Instant Neural Graphics Primitives with a Multiresolution Hash Encoding Neural graphics primitives, parameterized by fully connected neural networks, can be costly to train and evaluate. We reduce this cost with a versatile new input encoding that permits the use of a smaller network without sa..
 [논문 리뷰] Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation
[논문 리뷰] Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation
Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation https://arxiv.org/abs/1809.07454 Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation Single-channel, speaker-independent speech separation methods have recently seen great progress. However, the accuracy, latency, and computational cost of such methods remain insufficient. The ma..
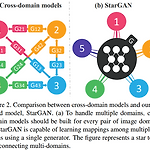 [논문 리뷰] StarGAN
[논문 리뷰] StarGAN
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation YAI 8기 안용준님이 GAN팀에서 리뷰하신 논문입니다. 0. Abstract 현재까지의 연구는 2개 도메인에서의 image2image translation이었다. 2개 이상의 도메인에서 scalability, robustness가 제한적이다. 왜냐하면 모든 도메인 pair마다 모델이 설계되어야 하기 때문이다. 이를 개선하고자, 모든 도메인 간 변환을 한 모델로 가능하게 하는 starGAN을 고안하였다. 이러한 통합 모델은 여러 개의 데이터셋들을 동시에 학습시킬 수 있다. 기존의 모델들보다 생성 이미지 퀄리티가 좋을 뿐만 아니라, 원하는 도..