
Notice
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- 강화학습
- Faster RCNN
- GaN
- YAI 8기
- nerf
- rl
- YAI 9기
- PytorchZeroToAll
- 컴퓨터 비전
- cl
- Fast RCNN
- CS231n
- NLP
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- CNN
- 3D
- Perception 강의
- 자연어처리
- RCNN
- YAI 10기
- Googlenet
- CS224N
- transformer
- YAI
- YAI 11기
- VIT
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- 컴퓨터비전
- cv
- 연세대학교 인공지능학회
Archives
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN 본문
R-CNN + Fast R-CNN + Faster R-CNN
** YAI 9기 조용기님이 비전 논문심화팀에서 작성한 글입니다.
R-CNN
Papers with Code - R-CNN Explained
1. Introduction
- 다양한 시각적 인식 작업에서 SIFT와 HOG가 많이 사용되었지만, 최근 2010 ~ 2012년 사이 큰 발전이 없었다.
- SIFT와 HOG보다 시각적 인식에 더 유능한 feature를 계산하는 hierarchical, multi-scale process가 존재하는데, 역전파와 확률적 경사하강법(SGD)을 사용한 LeCun et al.의 convolution neural network(CNN)가 그렇다.
- CNN은 1990년대에 활발하게 사용되다 support vector machine의 대두 이후 유행에서 멀어졌는데, 2012년 Krizhevsky et al.의 CNN이 ILSVRC의 이미지 분류에서 상당히 높은 정확도를 보여준 덕분에 CNN에 대한 관심이 다시 활발해졌다. 이 때의 중심 이슈는 다음과 같다:
- ImageNet에서의 CNN 분류 결과가 PASCAL VOC에서의 객체 탐지에 어느 정도로 일반화되는가?
- 이 논문은 간단한 HOG-like features 기반 시스템에 비교하여, CNN이 높은 객체 탐지 성능을 만들어 냄을 보인다. 이러한 결과를 위해 이 논문은 다음 두 문제에 집중한다.
- Localizing objects with a deep network
- 이미지 분류와 다르게 탐지 작업은 이미지 안의 객체들을 localize해야 한다.
- 접근 1 : frame localization as a regression problem ⇒ 좋은 성능이 나지 않는다.
- 접근 2 : build a sliding-window detector ⇒ 큰 reception field와 stride를 가진 논문의 네트워크에서는 정확한 localization이 문제가 된다.
- 이 논문에서는 “Recognition using regions” 패러다임을 사용한다. 시스템 흐름은 다음과 같다.
- 입력 이미지를 받는다.
- 약 2000개의 bottom-up category-independent region proposal을 추출한다.
- CNN을 사용하여 proposal에 대한 fixed-length feature vector를 계산한다.
- 각 region을 category-specific linear SVM으로 분류한다.
- Region proposal과 CNN을 결합하므로 R-CNN: Regions with CNN features라 부른다.
 Figure1: Object detection system overview
Figure1: Object detection system overview - 이미지 분류와 다르게 탐지 작업은 이미지 안의 객체들을 localize해야 한다.
- Training a high-capacity model with only a small quantity of annotated detection data
- 거대한 CNN을 훈련시킬 때, 사용 가능한 레이블된 데이터가 매우 부족하다.
- 이 논문에서는 large auxiliary dataset (ILSVRC)에서의 superviised pre-training과 small dataset (PASCAL)에서의 domain-specific fine-tuning이 이러한 문제에 대한 효율적인 패러다임임을 설명하고 있다.
- Localizing objects with a deep network
- 이 논문의 시스템은 매우 효율적이다. 시스템에 존재하는 클래스별 연산은 작은 행렬-벡터 곱과 탐욕적 비최대 억제(non-maximum suppression, NPM)밖에 없다. 이러한 계산적 속성은 feature가 모든 카테고리 사이에 공유되며 이전에 사용된 region feature보다 100배 적다는 점에서 비롯된다.
- 비최대 억제 참고 : https://deep-learning-study.tistory.com/403
- 또한 R-CNN은 region에서 기능하므로 Semantic Segmentation으로 확장될 수 있다.
2. Object detection with R-CNN
- 논문의 객체 탐지 시스템은 세 가지 모듈로 구성되어 있다.
1. Generating Category-independent region proposal
2. CNN that extracts a fixed-length feature vector from each region
3. Set of class-specific linear SVMs
2.1. Module design
Region proposals
- Region proposals : 주어진 이미지에서 물체가 있을 만한 영역을 찾는 알고리즘 (https://rubber-tree.tistory.com/133)
- 최근의 다양한 논문들에서 region proposal의 생성 방법을 설명하고 있다.
- Objectness, selective search, category-independent object proposals, constrained parametric min-cuts (CPMC), multi-scale combinatorial grouping, etc.
- Cireșan et al., detecting mitotic cells by applying a CNN to regularly-spaced square crops.
- R-CNN이 특정한 region proposal 방법을 가리지 않지만, 여기서는 이전의 논문들과의 비교를 위해 selective search를 사용한다.
Feature extraction
- Krizhevsky et al.의 CNN의 Caffe 구현을 사용하여 각 region proposal에서 4096 차원의 feature vector를 추출한다.
- Feature들은 5개의 컨볼루션 레이어와 2개의 FC 레이어에 평균을 뺀 227 × 227 RGB 이미지를 순방향 전파함으로 계산된다.
- Region proposal에서 feature를 계산하기 위해, 먼저 region의 이미지 데이터를 CNN에 맞는 형태로 변환해야 한다(227 × 227).
- 원래 region의 크기와 비율에 상관없이 이미지를 요구되는 크기에 warp한다.
- Warp 전에 bounding box를 확장하여 원래 box 주변 p 픽셀의 이미지 context가 남도록 한다 (p = 16).

Figure 2 : Warped training samples from VOC 2007 train.
2.2. Test-time detection
- 테스트 이미지에 selective search를 실행해 2000여개의 region proposal을 추출한다.
- Feature를 계산하기 위해 각 proposal을 warp하고 CNN에 순방향으로 전파시킨다.
- 각 클래스에 대해 훈련된 SVM으로 추출된 각 feature vector에 점수를 매긴다.
- 이미지에서 주어진 모든 scored region에 대해 (각 클래스에 대해 독립적으로) 탐욕적 비최대 억제를 적용하여, 더 높은 클래스 점수를 가진 region과의 intersection-over-union (IoU) overlap이 학습된 threshold보다 큰 region을 배제한다.
Run-time analysis
- 다음 두 가지 속성이 탐지 작업을 효율적으로 만든다.
- 모든 CNN 파라미터들이 모든 카테고리에서 공유된다.
- CNN으로 계산된 feature vector들은 (spatial pyramids with bag-of-visual-word encodings와 같은) 다른 일반적인 접근 방식과 비교했을 때 저차원이다.
- 위 속성에 의해 region proposal과 feature 계산에 드는 시간이 모든 클래스에 대해 상각된다.
- 유일한 클래스별 계산은 feature와 SVM 가중치 내적, 그리고 비최대 억제이다.
- 이러한 효율성의 분석은 R-CNN은 해싱과 같은 근사 기술에 의존하지 않고 수천 개의 객체 클래스로 확장될 수 있음을 보여준다.
- Dean et al.의 DPM과 해싱을 사용한 scalable detection이 VOC 2007에서 10000 클래스에 대해 이미지당 5분이 걸려서 약 16%의 mAP를 기록한 반면, 이 논문의 접근 방법은 CPU에서 약 1분이 걸리고 근사가 없어 약 59%의 mAP를 기록했다.
2.3. Training
Supervised pre-training
- CNN을 (bounding box level이 아닌) image-level annotation을 사용하여 large auxiliary dataset (ILSVRC2012 classification)에 사전훈련시켰다.
Domain-specific fine-tuning
- CNN을 새로운 작업인 탐지와 새로운 domain인 warped proposal windows에 적용하기 위해, warped region proposal만을 이용하여 SGD로 훈련을 진행했다.
- CNN의 ImageNet 1000 클래스 분류 레이어를 무작위 초기화된 N+1 클래스의 분류 레이어로 바꾸었다 (N은 객체 클래스의 수이며 background로 1을 더했다).
- Ground-truth box와 0.5 IoU overlap 이상으로 겹치는 모든 region proposal은 해당 box의 클래스에 양성으로, 나머지는 음성으로 처리했다.
- 0,001의 학습률(초기 사전훈련의 1/10)로 SGD 학습을 시작하여 초기화를 방해하지 않으면서 fine-tuning을 진행했다.
- 각 SGD 계산에서 32개의 positive window와 96개의 background window를 균일하게 샘플링하여 128 크기의 미니배치를 만들었다.
- 양성 샘플이 음성 샘플보다 매우 적기 때문에 샘플링을 양성으로 편향 시켰다.
Object category classifiers
- 이 논문에서는 IoU overlap threshold를 사용하여 특정 객체가 부분적으로 겹친 region에 대한 양성/음성 분류를 해결했다.
- Overlap threshold 0.3은 검증 세트에 대해 {0, 0.1, …, 0.5}에서의 그리드 서치로 선택했다.
- 클래스별로 하나의 linear SVM을 적용할 때 훈련 데이터가 메모리에 올리기에 너무 크므로 논문에서는 hard negative mining을 채택했다. (참고 : https://cool24151.tistory.com/37)
3. Visualization, ablation, and modes of error
3.1. Visualizing learned features
- 이 논문은 신경망이 학습한 feature를 직접적으로 시각화하는 비파라미터적 방법론을 소개한다.
- 아이디어는 신경망의 특정 unit(feature)을 선택하고 이를 하나의 object detector로 사용하는 것이다.
- Region proposal 세트에서 unit의 활성화 함수를 계산한다.
- 이 활성화 값이 큰 순서대로 proposal을 정렬한다.
- 비최대 억제를 수행하여 최고 점수의 region을 출력한다.
- 이를 통해 선택된 unit이 정확히 어떤 입력을 촉발(fire)하는지 보여준다.

Figure 3: Top regions for six pool5 units. Receptive fields and activation values are drawn in white. Some units are aligned to concepts, such as people (row 1) or text (4). Other units capture texture and material properties, such as dot arrays (2) and specular reflections (6).
- Figure 3는 VOC 2007 trainval로 fine-tuning을 진행한 CNN의 pool5 unit의 상위 16 활성화 값을 unit 별로 각 행에서 보여주고 있다. 이 unit들은 신경망이 어떠한 것을 학습하는지 보여준다.
- 신경망은 모양, 질감, 색 등의 특징과 함께 적은 수의 class-tuned feature를 결합하는 표현을 학습하는 것으로 보여진다.
3.2. Ablation studies
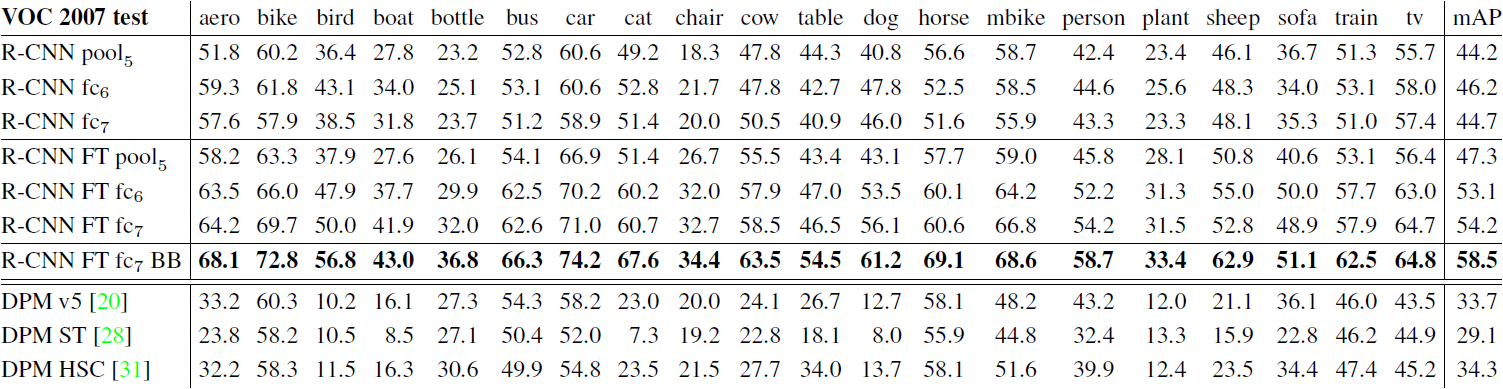
Table 2: Detection average precision (%) on VOC 2007 test. Rows 1-3 show R-CNN performance without fine-tuning. Rows 4-6 show results for the CNN pre-trained on ILSVRC 2012 and then fine-tuned (FT) on VOC 2007 trainval. Row 7 includes a simple bounding-box regression (BB) stage that reduces localization errors (Section C). Rows 8-10 present DPM methods as a strong baseline. The first uses only HOG, while the next two use different feature learning approaches to augment or replace HOG.
Performance layer-by-layer, without fine-tuning
- 저자들은 어떠한 레이어가 탐지 성능에 필수적인지를 이해하기 위해, VOC 2007 데이터셋에서 CNN의 마지막 3개 레이어 pool5,fc6,fc7의 결과를 분석했다. 여기에서는 모든 CNN 파라미터가 ILSVRC 2012에만 사전훈련되었다.
- (Table 2 rows 1-3) 레이어별로 성능을 분석한 결과 fc7의 feature가 fc6보다 잘 일반화되지 않는다. 이는 CNN의 파라미터를 줄여도 mAP 값에 영향을 주지 않는다는 것을 의미한다.
- 또한 레이어 fc6과 fc7 둘 다 제거하면 pool5가 오직 6%의 CNN 파라미터만 계산하더라도 꽤 좋은 결과를 만들어낸다. 이를 통해 CNN의 표현력은 densely connected layer보다 convolutional layer에서 나온다는 것을 알 수 있다.
Performance layer-by-layer, with fine-tuning
- 위 모델에 VOC 2007 tranval에서 fine-tuning을 진행한 후 결과를 분석헀다.
- (Table 2 rows 4-6) Fine-tuning을 통해 fc6과 fc7의 mAP가 pool5에 비해 대폭 상승했다.
- 이는 ImageNet을 통해 pool5은 일반적인 feature를 학습하고, 대부분의 성능 향상은 이 레이어 위에서 domain-specific non-linear classifier를 학습함으로 얻어진다는 것을 의미한다.
3.3. Network architectues

Table 3: Detection average precision (%) on VOC 2007 test for two different CNN architectures. The first two rows are results from Table 2 using Krizhevsky et al.’s architecture (T-Net, TorontoNet). Rows three and four use the recently proposed 16-layer architecture from Simonyan and Zisserman (O-Net, OxfordNet)
- 논문의 대부분에서는 Krizhevsky et al.의 신경망 아키텍처를 사용했다.
- 실제로는 아키텍처 선택이 R-CNN의 탐지 성능에 큰 영향을 미친다.
3.4. Detection error analysis

Figure 6: Sensitivity to object characteristics. Each plot shows the mean (over classes) normalized AP (see [23]) for the highest and lowest performing subsets within six different object characteristics (occlusion, truncation, bounding-box area, aspect ratio, viewpoint, part visibility). We show plots for our method (R-CNN) with and without fine-tuning (FT) and bounding-box regression (BB) as well as for DPM voc-release5. Overall, fine-tuning does not reduce sensitivity (the difference between max and min), but does substantially improve both the highest and lowest performing subsets for nearly all characteristics. This indicates that fine-tuning does more than simply improve the lowest performing subsets for aspect ratio and bounding-box area, as one might conjecture based on how we warp network inputs. Instead, fine-tuning improves robustness for all characteristics including occlusion, truncation, viewpoint, and part visibility.
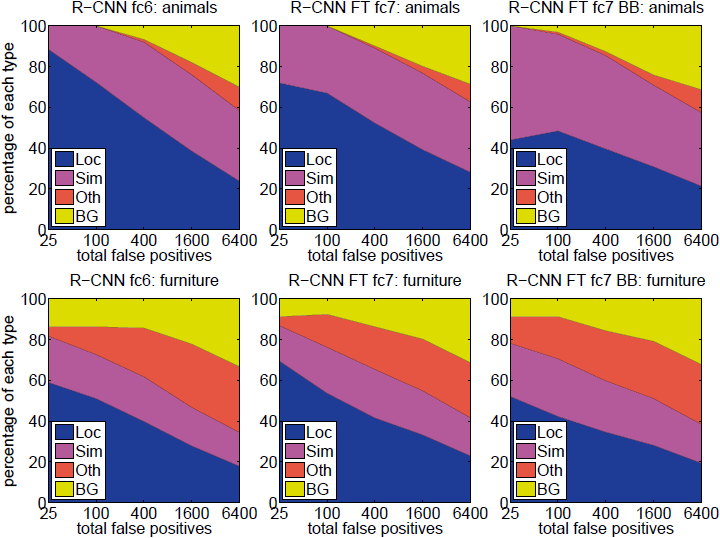
Figure 5: Distribution of top-ranked false positive (FP) types. Each plot shows the evolving distribution of FP types as more FPs are considered in order of decreasing score. Each FP is categorized into 1 of 4 types: Loc—poor localization (a detection with an IoU overlap with the correct class between 0.1 and 0.5, or a duplicate); Sim—confusion with a similar category; Oth—confusion with a dissimilar object category; BG—a FP that fired on background. Compared with DPM (see [23]), significantly more of our errors result from poor localization, rather than confusion with background or other object classes, indicating that the CNN features are much more discriminative than HOG. Loose localization likely results from our use of bottom-up region proposals and the positional invariance learned from pre-training the CNN for whole-image classification. Column three shows how our simple bounding-box regression method fixes many localization errors.
- Error analysis를 위해 Hoiem et al.의 detection analysis tool을 적용하여, error mode를 찾아내고 fine-tuning이 어떻게 이러한 mode를 바꾸는지를 이해하며 DPM과 error의 타입이 어떻게 다른지를 확인했다. - 분석의 전체적인 결과는 논문의 범위를 벗어나므로, Figure 5와 6만 첨부하겠다.
3.5. Bounding-box regression
- Error analysis에 기반하여 localization error를 줄이는 간단한 방법을 구현했다.
- DPM에서 사용된 bounding box regression을 참고하여, selective search region proposal의 pool5 feature를 이용해 새로운 detection window를 예측하기 위한 선형 회귀 모델을 훈련시킨다.
- 전체 세부 사항은 Appendix C에서 설명한다.
5. Semantic segmentation
- Region classification은 시멘틱 세그멘테이션의 표준 기술이다.
- 당시의 최고 시멘틱 세그멘테이션 시스템인 “second-order pooling” (O₂P) 와의 비교를 위해 O₂P 시스템의 오픈 소스 프레임워크에서 실험이 진행되었다.
- O₂P는 CPMC를 사용하여 이미지당 150개의 region proposal을 생성하고, 각 클래스별로 support vector regression (SVR) 을 사용하여 각 region의 quality를 예측한다.
- O₂P의 높은 성능은 CPMC region의 quality와 다중 feature 타입의 강력한 second order pooling으로 얻어졌다.
CNN features for segmentation
- CPMC region의 feature를 계산하기 위해 세 가지 전략을 측정했는데, 모두 직사각형의 window로 region을 감싸서 진행되었다.
- full : Region의 모양에 관계 없이 warped window로 CNN feature를 직접 계산한다. Region이 직사각형이 아닌 경우를 무시한다.
- fg : Region의 foreground mask에서만 CNN feature를 계산한다. Background를 평균 입력값으로 바꾸어, 평균값을 뺀 이후 background region이 0이 되도록 한다.
- full+fg : 단순히 위의 두 전략을 합친 전략이다.
Results on VOC 2011

Table 5: Segmentation mean accuracy (%) on VOC 2011 validation. Column 1 presents O2P; 2-7 use our CNN pre-trained on ILSVRC 2012. 모든 전략에 대해서 fc6의 값이 fc7보다 우세하다. fg 전략이 full 전략보다 조금 우세하며, 이는 masked region shape가 더 강한 신호를 만들었음을 암시한다. - full+fg 전략이 최상의 결과를 얻었으며, 이는 fg feature를 감안하더라도 full feature가 꽤 유익함을 암시한다.
Appendix
A. Object proposal transformations

Figure 7: Different object proposal transformations. (A) the original object proposal at its actual scale relative to the transformed CNN inputs; (B) tightest square with context; (C) tightest square without context; (D) warp. Within each column and example proposal, the top row corresponds to p = 0 pixels of context padding while the bottom row has p = 16 pixels of context padding.
이 논문에서 사용된 CNN은 고정된 227×227 픽셀의 입력을 필요로 한다. 탐지 작업을 위해 임의의 이미지 직사각형의 object proposal을 사용하며 object proposal을 유효한 CNN 입력으로 변환하는 접근 방법들을 소개했다.
- “Tightest square with context” : 각 object proposal을 딱 맞는 정사각형으로 둘러싼 다음 그 정사각형의 이미지를 CNN 입력의 크기로 확장한다.
- “Tightest square without context” : Object proposal을 둘러싸는 image content를 제외하고 tightest square를 만든다.
- “warp” : 각 object proposal을 CNN 입력 크기에 맞게 비등방적으로 확장한다.
- 이 변환들에서, 원래의 object proposal 주변에 추가적인 image context를 포함하는 것도 고려할 수 있다. Context padding의 크기 p는 변환된 입력 좌표 프레임에서 원 object proposal 주변의 경계 크기로 정의된다 (Figure 7의 각 예제 위 줄은 p=0, 아래 줄은 p=16 픽셀이다). 실험에서는 context padding이 있는 warping이 더 나은 성능을 보였다.
B. Positive vs. negative examples and softmax
- 두 가지 설계의 선택은 추가적인 논의를 필요로 한다.
- 왜 CNN의 fine-tuning과 객체 탐지 SVM 훈련 사이에서 양성과 음성 예제가 다르게 정의되는가?
- Fine-tuning : 각 object proposal을 최대 IoU overlap을 가진 ground-truth instance에 매핑하고, IoU가 0.5 이상일 때 매치된 ground-truth class에 양성으로 레이블링했다. 모든 다른 proposal은 “background”, 즉 음성으로 레이블링되었다.
- SVM 훈련 : 각 클래스에 대해 ground-truth box만을 양성 예제로 사용하고, 0.3 미만의 IoU overlap을 가진 proposal을 음성으로 레이블링했다. Grey zone (0.3보다 큰 IoU overlap을 가지지만 ground truth가 아닌 경우) 은 무시한다.
- 처음에는 SVM 훈련을 ImageNet에서 사전 훈련된 CNN의 feature에서 시작했기 때문에 fine-tuning을 고려할 필요가 없었으며, SVM 훈련에 대해 위의 정의가 최적이었다. Fine-tuning을 시작했을 때, SVM 훈련에서와 같은 정의를 사용했으나 지금의 정의에 비해 결과가 매우 좋지 않았다.
- 양성과 음성이 정의되는 방법보다는 fine-tuning 데이터가 부족하다는 사실 이 근본적으로 중요하다. 따라서 이 논문에서는 (0.5 ~ 1 사이의 overlap을 가진 proposal들에 대해) “jitter”를 통해 양성 예제를 증대시키는 방법을 도입했다.
- 왜 fine-tuning 이후에 SVM 훈련을 시키는가?
- Fine-tuning된 신경망의 마지막 softmax regression classifier 레이어를 object detector로 채택하는 것이 명료할 것이다. 하지만 이에 대한 VOC 2007 데이터셋 실험 결과, mAP가 54.2%에서 50.9%로 감소했다.
- 성능 저하는 몇 가지 요인의 조합으로 발생할 수 있는데, fine-tuning에서 양성 예제의 정의가 정확한 localization을 강조하지 않는다는 것과 softmax 분류기가 SVM 훈련의 “hard negatives”에 해당하는 부분집합보다는 무작위로 샘플링된 음성 예제에 더 훈련된다는 것 등이 있다.
- 한편 이러한 결과는 fine-tuning 이후에 SVM을 훈련하지 않고도 거의 같은 수준의 성능에 도달할 수 있다는 것을 보여준다. 논문에서는 fine-tuning에 대한 몇 가지 추가적인 변경을 통해 성능 격차를 좁힐 수 있다고 추측하고 있다. 이게 가능할 경우 탐지 성능의 손실 없이 R-CNN 훈련의 간소화와 속도 향상을 얻을 수 있다.
- 왜 CNN의 fine-tuning과 객체 탐지 SVM 훈련 사이에서 양성과 음성 예제가 다르게 정의되는가?
C. Bounding-box regression
- 이 논문에서는 Localization 성능 향상을 위해 bounding-box regression stage를 도입했다.
- Class-specific detection SVM을 사용하여 각 selective search proposal에 점수를 매긴 후, class-specifie bounding-box regressor 를 사용하여 새로운 bounding box를 예측한다.
- 이는 DPM에서 사용되는 bounding-box regression과 유사하다. 주된 차이점은 DPM에서는 추론된 DPM part location에서 계산되는 geometric feature와는 달리 CNN이 계산한 feature로 회귀 를 진행한다는 것이다.
- 훈련 알고리즘의 입력 : N개의 training pair (Pi,Gi)i=1,…,N (i는 필요한 경우가 아니면 생략)
- P=(Px,Py,Pw,Ph)는 proposal P의 bounding box 중심 좌표와 box의 너비 및 높이이다.
- G=(Gx,Gy,Gw,Gh)는 ground-truth G의 bounding box 중심 좌표와 box의 너비 및 높이이다.
- 훈련 알고리즘의 목표는 P에서 G로의 매핑 변환을 학습하는 것이다. 예측 ground-truth box ˆG로의 파라미터화된 변환은 다음과 같다:
- ˆGx=Pwdx(P)+Px
ˆGy=Phdy(P)+Py
ˆGw=Pwexp(dw(P))
ˆGh=Phexp(dh(P)) 
- 변환은 4개의 항 dx(P),dy(P),dw(P),dh(P)로 파라미터화되었다.
- dx(P),dy(P)는 P의 bounding box 중심의 scale-invariant translation을 지정한다.
- dw(P),dh(P)는 P의 bounding box 너비 및 높이의 log-space translation을 지정한다.
- 각 함수 d★(P) (★는 x,y,w,h) 는 proposal P의 pool5의 선형 함수 ϕ5(P)로 모델링되었다. 따라서 d★(P)=wT★ϕ5(P)이며, 이 때 w★는 학습가능한 모델 파라미터 벡터이다.
- w★는 regularized least squares 목적 함수 (ridge regression) 를 최적화하여 학습한다:

- Training pair (P,G)에 대한 regression target t★는 다음과 같이 정의된다:
- tx=(Gx−Px)/Pw
ty=(Gy−Py)/Ph
tw=log(Gw/Pw)
th=log(Gh/Ph) - 이 최적화는 tandard regularized least squares problem이기 때문에 closed form에서 효율적으로 해결할 수 있다.
- ˆGx=Pwdx(P)+Px
- Bonding-box regression을 구현하면서 두 가지 미묘한 문제를 발견했다.
- span style='background-color: #fff5b1'>규제가 중요하다 : 검증 세트에 기반하여 λ=1000로 지정했다.
- 사용할 span style='background-color: #fff5b1'> training pairs (P,G)를 고를 때 주의할 필요가 있다 : Proposal P가 최소 하나의 ground-truth box 근처에 있어야 학습이 가능하다. 논문에서는 P를 최대 IoU overlap을 가진 (그러면서도 threshold 이상의 IoU overlap을 가진) ground-truth box G에 할당하여 “nearness”를 구현했다. 할당되지 않은 모든 proposal은 무시했다.
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Mask R-CNN (0) | 2022.03.20 |
|---|---|
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] FPN : Feature Pyramid Network (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3) (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (2) (0) | 2022.03.10 |
'컴퓨터비전 : CV/CNN based' Related Articles
more



