
Notice
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- VIT
- cl
- transformer
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- YAI
- NLP
- nerf
- 연세대학교 인공지능학회
- rl
- CS224N
- Fast RCNN
- Googlenet
- cv
- YAI 9기
- 컴퓨터비전
- Perception 강의
- 자연어처리
- YAI 8기
- RCNN
- CS231n
- YAI 11기
- 3D
- GaN
- YAI 10기
- 강화학습
- 컴퓨터 비전
- CNN
- Faster RCNN
- PytorchZeroToAll
Archives
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3) 본문
R-CNN + Fast R-CNN + Faster R-CNN (3)
** YAI 9기 조용기님이 비전 논문심화팀에서 작성한 글입니다.
Faster R-CNN
Papers with Code - Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
1 Introduction
- 이 논문이 쓰인 시점에 탐지 신경망 시스템에 존재하는 병목은 region proposal이었다.
- Selective Search는 CPU에서 연산되어, Fast R-CNN의 탐지 신경망에 비해 매우 느리다.
- EdgeBoxes는 proposal의 품질과 속도 사이 최상의 균형을 이루었지만 여전히 탐지 신경망만큼의 실행 시간을 필요로 한다.
- CNN이 GPU를 사용하여 이득을 얻는 반면, region proposal은 CPU에서 실행되므로 단순히 CNN의 실행 시간과 비교할 수 없다. 즉, region proposal도 GPU에서 실행될 필요가 있다.
- 기존의 proposal 연산을 GPU에서 수행하도록 재구현하는 방법이 있지만 이러한 재구현은 탐지 신경망의 아랫부분을 무시하며 따라서 연산을 공유할 중요한 기회를 놓치게 된다.
- 따라서 이 논문은 proposal을 deep CNN에서 계산하도록 하여 탐지 신경망의 계산에서 비용이 거의 없는 proposal 연산을 만든다.
- 이 논문은 Region Proposal Networks (RPNs) 이라는 새로운 신경망을 도입한다. 이 신경망은 객체 탐지 신경망과 convolutional layer를 공유하는 것이 주된 특징이다. Fast R-CNN과 같은 region-based detector에 사용되는 convolutional feature map으로 region proposal을 생성해낼 수 있다는 것이 아이디어이며 여기서 RPN을 만든다.
- Convolutional feature 위에 몇 개의 convolutional layer를 추가해 RPN을 만들어내며, 이 layer들로 region bound regression과 objectness score computation을 동시에 수행한다.
- 따라서 RPN은 fully convolutional network (FCN) 이며, 특히 detection proposal 생성에서 end-to-end로 훈련될 수 있다.

Figure 1: Different schemes for addressing multiple scales and sizes. (a) Pyramids of images and feature maps are built, and the classifier is run at all scales. (b) Pyramids of filters with multiple scales/sizes are run on the feature map. (c) We use pyramids of reference boxes in the regression functions.
- 또한 RPN이 광범위한 스케일과 종횡비에서 region proposal을 효율적으로 예측하기 위해, 이 논문은 “anchor” box 를 도입했다.
- 이 박스는 regression references의 피라미드로 생각할 수 있는데, 이를 통해 광범위한 스케일과 종횡비에 대한 이미지나 필터를 열거하는 비용 낭비를 피할 수 있다.
- 이 모델은 하나의 스케일의 이미지에 잘 훈련되고 테스트될 수 있으며, 따라서 실행 속도에서 이득을 얻는다.
- 이 논문은 RPN과 Fast R-CNN의 객체 탐지 신경망을 합치기 위해 다음과 같은 training scheme을 제시한다.
- proposal을 고정한 채, region proposal을 위한 fine-tuning과 object detection을 위한 fine-tuning을 번갈아 수행한다. 이 scheme은 빠르게 수렴하며 두 작업 사이 공유되는 convolution feature를 가진 통합된 신경망을 만들어낸다.
- 이 논문의 접근 방법은 테스트 단계에서 selective search의 거의 모든 계산적 부담을 덜어준다. 이 방법은 단지 실용적인 측면에서 비용에 효율적인 해답일 뿐만 아니라, 객체 탐지 정확도를 향상하는 효과적인 방법이다.
2 Related Work
Object Proposal
- 광범위하게 사용되는 object proposal에는 두 가지 방법이 있다.
- Grouping super-pixels: Selective Search, CPMC, MCG
- Sliding windows: objectness in windows, EdgeBoxes
- 그동안 object proposal은 탐지 모듈과 독립적인 외부 모듈로 채택되었다.
Deep Networks for Object Detection
- R-CNN은 proposal region들을 특정 카테고리의 객체 또는 배경(background)으로 분류하기 위해 CNN을 end-to-end로 훈련시킨다. 주로 분류기로 작용되며, 따라서 분류의 정확도는 region proposal 모듈의 성능에 달려 있다.
- 몇 가지 논문(OverFeat, MultiBox)에서는 객체의 bounding box를 예측하는 깊은 신경망을 사용하는 방법을 제안했다.
- 효율적이며 정확한 시각적 인식을 위해 convolution의 공유 계산이 점점 주목받고 있다.
3 Faster R-CNN

Figure 2: Faster R-CNN is a single, unified network for object detection. The RPN module serves as the ‘attention’ of this unified network.
- Faster R-CNN은 두 가지 모듈로 구성되며 전체 시스템은 통합퇸 하나의 객체 탐지 신경망이다.
- Region proposal을 생성하는 deep fully convolutional network (RPN)
- Region proposal을 사용하는 Fast R-CNN detector
- 이 RPN 설계에 “attention” 매커니즘을 적용하여, RPN 모듈은 전체 신경망의 방향을 잡는다.
3.1 Region Proposal Networks

Figure 3: Left: Region Proposal Network (RPN). Right: Example detections using RPN proposals on PASCAL VOC 2007 test. Our method detects objects in a wide range of scales and aspect ratios.
- RPN은 임의 크기의 이미지를 입력으로 받고, 출력으로 각 objectness score를 포함한 object proposal의 집합을 생성한다.
- “Objectness”는 객체가 객체 클래스인지 배경(background)인지의 측정이다.
- 이 논문의 최종 목표는 Fast R-CNN 객체 탐지 신경망과 연산을 공유하는 것 이므로, 두 신경망은 공통의 convolutional layers sets를 공유한다고 가정한다.

RPN 구조의 이해를 위해 추가한 그림. 출처 : [https://yeomko.tistory.com/17?category=888201](https://yeomko.tistory.com/17?category=888201)
- Region proposal 생성을 위해, 공유된 마지막 convolutional layer의 convolutional feature map 출력 위를 작은 신경망으로 sliding시킨다. Sliding-window 방식으로 작동되므로 fully-connected layer들은 모든 공간적 위치에서 공유된다.
- 이 신경망은 입력받는 convolutional feature map의 $n × n$ window를 입력으로 사용한다 ($n=3$).
- 각 sliding window는 저차원 feature에 매핑되며, 이 feature는 다시 두 fully-connected layer의 입력으로 들어간다. 각각 box-regression layer ($reg$) 와 box-classification layer ($cls$) 이다.
- 이 신경망 구조는 $n × n$ convolutional layer 이후 두 개의 $1 × 1$ convolutional layer ($reg$와 $cls$) 로 만들어진다.
3.1.1 Anchors
- Sliding-window가 지나가는 각 위치에서 동시에 다수의 region proposal을 예측한다.
- 각 위치당 가능한 최대 proposal의 개수를 $k$라고 하자.
- $reg$ 레이어의 $4k$ 출력으로 $k$개 box의 좌표를 인코딩한다.
- $cls$ 레이어의 $2k$ 출력으로 (two-class softmax layer로 가정) 각 proposal이 객체일 확률을 추정한다.
- $k$ 개의 proposal은 $k$ reference box에 대하여 파라미터화되며 이 box를 anchor라고 부른다. Anchor는 sliding window의 중앙에 위치하며, 스케일과 종횡비를 다룬다 (Figure 3, left).
- 가령 3 가지 스케일과 3 가지 종횡비를 사용하면 각 sliding position마다 $k=9$ 개 anchor를 가지게 된다. 크기 $W × H$의 convolutional feature map은 $WHk$ 개의 anchor를 가진다.
Translation-Invariant Anchors
- Anchor의 접근 방식에서 가장 중요한 속성은 이 접근 방법이 anchor와 anchor와 관련된 proposal을 계산하는 함수에 있어 translation invariant하다는 것이다. 이미지의 객체 위치가 바뀌면 proposal 위치도 바뀌고 이때 함수는 위치에 상관없이 proposal을 예측할 수 있어야 한다.
- Anchor의 이 속성에 의해 모델의 크기가 줄어든다. Feature projection layer를 고려해도 다른 모델에 비해 훨씬 적은 매개변수를 가진다.
Multi-Scale Anchors as Regression References
- Anchor-based method 이전에 다중 스케일 예측에 사용되던 두 가지 방법이 있었다.
- Image/feature pyramid (DPM, CNN-based methods) : 이미지와 feature map의 크기를 여러 스케일 및 종횡비로 바꾸어 따로 계산한다. 실행 시간이 크다.
- Pyramid of filters : Feature map에서 다중 스케일 및 종횡비의 sliding window를 사용한다. 보통 첫 번쨰 방법과 함께 채택되었다.
- Anchor-based method는 위 방법에 비해 비용면에서 효율적인 pyramid of anchors로 구성 된다. 이 방법은 단일 스케일 및 종횡비의 이미지 및 feature map에서 단일 크기의 filter를 sliding하며 이 filter 위에서 다중 스케일 및 종횡비의 anchor box를 사용 하여 bounding box의 분류 및 회귀를 진행한다.
- 이 다중 스케일 anchor는 스케일 처리를 위한 추가 비용 없이 feature를 공유 하는 핵심 요소이다.
3.1.2 Loss Function
- RPN 훈련에서, 각 anchor별로 이진 클레스 레이블을 (객체인지 아닌지) 할당한다.
- 양성 레이블은 두 가지 조건으로 할당할 수 있다. 이 때 하나의 ground-truth box에 대해 여러 anchor들이 양성 레이블로 할당될 수 있다.
- Ground-truth box와 가장 큰 Intersection-over-Union (IoU) overlap을 가지는 anchor
- 임의의 ground-truth box와 0.7 보다 큰 IoU overlap을 가지는 anchor
- 일반적으로 조건 2로 양성 샘플을 결정짓기에 충분하지만, 일부 경우에 조건 2가 양성 샘플을 발견하지 못 하는 경우도 있으므로 논문에서는 조건 1을 채택했다.
- 음성 레이블은 모든 ground-truth box에 대해 IoU ratio가 0.3보다 적을 경우 할당된다.
- 양성도 음성도 아닌 anchor들은 훈련의 목적 함수 계산에 작용하지 않는다.
- 할당된 레이블들을 통해, Fast-RCNN의 multi-task loss로 목적 함수를 최소화한다. 하나의 이미지에 대한 손실 함수는 다음과 같이 정의된다:
- $i$는 미니배치의 anchor 인덱스이다.
- $p_i$는 $i$ 번째 anchor가 객체일 확률 예측이다.
- $p_i^{\star}$은 ground-truth 레이블로 1이 양성, 0이 음성이다.
- $t_i$는 예측된 bounding box의 파라미터화된 좌표 4개의 벡터 예측이다.
- $t_i^{\star}$는 양성 anchor와 관련된 ground-truth box의 파라미터화된 좌표 벡터이다.
- $L_{cls}$는 분류 손실로 두 클래스 (객체인지 아닌지) 사이의 로그 손실이다.
- $L_{reg}(t_i,t_i^{\star})=R(t_i-t_i^{\star})$은 회귀 손실로, $R$은 Fast R-CNN의 robust loss function $smooth_{L_1}(x)=\begin{cases} 0.5x^2 & if |x|<1 \ |x|-0.5 & otherwise\end{cases}$ 이다.
- $L_{reg}(t_i,t_i^{\star})$에 $p_i^{\star}$를 곱해 회귀 손실이 양성 anchor ($p_i^*=1$) 에서만 활성화되도록 한다.
- $N_{cls}$와 $N_{reg}$를 통해 두 손실항을 normalize하며 balancing parameter $\lambda$로 두 손실 항 사이 가중치를 둔다.
- 논문의 구현에서 $N_{cls}$는 미니배치 크기로 설정되고 $N_{reg}$는 anchor의 개수로 설정된다 (논문에서 각각 256과 2400이므로 동등하게 가중치를 부여하기 위해 $\lambda=10$으로 설정했다).
- 논문의 실험에서 결과는 넓은 범위에서 $\lambda$ 값에 큰 영향을 받지 않았으며, 이는 두 항에 normalization을 할 필요가 없음을 보여준다.
- $$ L({p_i}, {t_i}) = \frac{1}{N_{cls}} \sum_i L_{cls}(p_i, p_i^{\star}) + \lambda \frac{1}{N_{reg}} \sum_i p_i^{\star}L_{reg}(t_i, t_i^{\star})$$
- Bounding box regression에서 다음과 같이 4개 좌표를 파라미터화한다:
- $ t_x = (x-x_a) / w_a $, $t_y = (y-y_a) / h_a $
- $ t_w = log(w/w_a)$, $t_h = log(h/h_a)$
- $ t_x^* = (x^* - x_a)/w_a $, $t_y^* = (y^* - y_a) / h_a$
- $ t_w^* = log(w^* /w_a)$, $t_h^* = log(h^* / h_a)$
- $x,y,w,h$는 각각 box의 중심 좌표와 너비, 높이이다.
- 변수 $x, x_\text{a}, x^*$는 각각 predicted box, anchor box, 그리고 ground-truth box에 대한 값이다 ($y,w,h$에 대해서도 마찬가지로 정의된다).
- 이를 통해, bounding-box 회귀를 anchor box에서 근처 ground-truth box로의 회귀로 볼 수 있다.
- 모든 region 크기에 regression weight가 공유되는 이전의 RoI-based (Region of Interest) method와는 다르게, 회귀에 사용되는 feature가 고정된 크기이며 (3 × 3) 이 위의 $k$ 개의 bounding-box regressor가 학습된다. 이 regressor들은 각각 하나의 스케일과 종횡비에 대해서만 학습되며 따라서 가중치가 공유되지 않는다. 이러한 anchor 설계 덕분에 고정된 크기/스케일의 feature에서도 다양한 크기의 box를 예측할 수 있다.
3.1.3 Training RPNs
- RPN은 backpropagation과 stochastic gradient descent (SGD)를 사용하여 end-to-end로 훈련시킬 수 있다.
- 이 신경망을 훈련시키기 위해 “image-centric” sampling strategy를 따른다 (Fast R-CNN에서 사용됨).
- 각 미니배치는 많은 양성 및 음성 anchor를 가지고 있는 단일 이미지에서 생성한다.
- 모든 anchor를 통해 손실 함수를 최적화시킬 수 있지만, 보통 음성샘플이 많기 때문에 편향될 수 있다. 따라서 이미지에서 무작위로 256개의 anchor를 샘플링하여 미니배치의 손실 함수를 계산한다. 여기서 샘플링된 양성 및 음성 anchor의 비율은 최대 1:1이다. 이미지의 양성 샘플이 128개보다 적을 때 미니배치를 음성 샘플로 채운다.
- 각 미니배치는 많은 양성 및 음성 anchor를 가지고 있는 단일 이미지에서 생성한다.
3.2 Sharing Features for RPN and Fast R-CNN
- 이 section에서는 RPN과 Fast R-CNN으로 구성되어 convolutional layer를 공유하는 하나의 신경망을 학습시키는 알고리즘을 설명한다 (Figure 2).
- RPN과 Fast R-CNN은 독립적으로 훈련되며 내부의 convolutional layer를 서로 다른 방식으로 수정하므로, 두 신경망 사이에 convolutional layer를 공유하는 테크닉을 따로 사용했다. 이에 대해 논문에서는 feature가 공유되도록 신경망을 훈련시키는 3가지 방법을 제시했으며, 첫 번째인 alternating training이 채택되었다.
- Alternating training : 먼저 RPN을 훈련시키고, 그 후 proposal을 사용하여 Fast R-CNN을 훈련시킨다. Fast R-CNN으로 튜닝된 신경망은 다시 RPN을 초기화하는데 사용되며 이 과정을 반복한다. 논문의 모든 실험에 사용되었다.
- Approximate joint training : Figure 2의 모습처럼 훈련 단계에서 RPN과 Fast R-CNN 신경망이 하나로 병합된다. 각 SGD 반복에서 순방향 전파가 region proposal을 생성해내며 이 proposal이 Fast R-CNN detector를 훈련시킬 때 고정되고 미리 계산된 것처럼 사용된다. 역전파는 똑같이 진행되며 공유되는 레이어에서는 RPN 손실과 Fast R-CNN 손실이 합쳐져 진행된다. 구현은 쉬우나 proposal box의 좌표 (이는 신경망의 출력이기도 하다) 에 대한 도함수를 무시하므로 근사치를 만들어낸다. 실험 결과 이 방법이 근접한 결과를 만들어내지만 alternating training에 비해서 25~50%의 훈련 시간 단축이 있었다.
- Non-approximate joint training : 위에서 언급되었듯이 RPN이 예측한 bounding box 또한 입력의 함수이다. Fast R-CNN의 RoI pooling layer는 convolutional feature와 예측된 bounding box를 입력으로 받아들이며, 따라서 이론적으로 유효한 역전파 solver는 box 좌표에 관한 그래디언트도 포함해야 한다. 이 그래디언트는 위의 approximate joint training에서는 무시된다. 이 non-approximate joint training 방법에서는 box 좌표에 관해 미분이 가능한 RoI pooling layer가 필요하다. 이는 non-trivial하며 해답은 “RoI warping” layer에 의해 주어지는데 이 논문 범위를 벗어나는 내용이다.
4-Step Alternating Training
- RPN을 section 3.1.3에서 설명한 방식으로 훈련시킨다. 이 신경망은 region proposal을 위해 ImageNet에 사전훈련된 모델로 초기화되고 end-to-end로 fine-tune된다.
- 스텝 1의 RPN에 의해 생성된 proposal을 이용하여, 분리된 탐지 신경망을 Fast R-CNN으로 훈련시킨다. 이 detection network도 또한 ImageNet에 사전훈련된 모델로 초기화된다. 이 시점까지는 두 신경망이 convolution layer를 공유하지 않는다.
- RPN 훈련 초기화를 위해 detector network를 사용한다. 공유 convolutional layer를 고정하고 RPN 고유의 레이어만 fine-tuning시킨다. 이 때부터 두 신경망은 convolutional layer를 공유한다.
- 공유 convolutional layer를 고정한 채로, Fast-RCNN 고유 레이어들을 fine-tuning시킨다.
3.3 Implementation Details
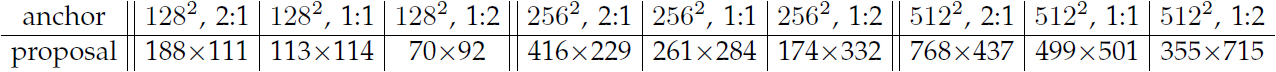
Table 1: the learned average proposal size for each anchor using the ZF net (numbers for s = 600).
- Anchor의 경우 $128^2, 256^2, 512^2$의 3가지 픽셀 수, 그리고 $1:1, 1:2,2:1$의 3가지 종횡비를 사용했다. 특정 데이터셋에 따라 다르게 선택되지 않으며, 그에 따른 영향은 다음 section의 ablation 실험에서 소개한다.
- 실험 결과 (Table 1) 객체의 중심이 보인다면 객체의 범위를 대략적으로 유추할 수 있었다.
- Anchor box가 이미지의 경계를 넘어갈 경우는 주의해서 처리해야 한다.
- 훈련 단계 : 이미지의 경계를 지나는 모든 anchor를 무시한다. 훈련에서 이상치를 무시하지 않으면 목적 함수에 크고 수정이 어려운 오류항이 들어가고 훈련이 수렴하지 않는다.
- 테스트 단계 : 전체 이미지에 fully convolutional RPN을 적용한다. 이렇게 하면 경계를 지나는 proposal box가 생성되어 이미지 경계에 클리핑할 수 있다.
- 때로는 RPN proposal이 서로 상당히 겹칠 수 있는데, 이러한 중복을 줄이기 위해 이 논문은 $cls$ 점수에 따른 비-최대 억제 (non-maximum suppression, NMS) 를 채택했다.
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Mask R-CNN (0) | 2022.03.20 |
|---|---|
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] FPN : Feature Pyramid Network (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (2) (0) | 2022.03.10 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (0) | 2022.03.02 |
'컴퓨터비전 : CV/CNN based' Related Articles
more




Comments