
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 컴퓨터비전
- transformer
- CS231n
- YAI 10기
- NLP
- CNN
- 연세대학교 인공지능학회
- 강화학습
- PytorchZeroToAll
- YAI
- 3D
- rl
- Googlenet
- 자연어처리
- Perception 강의
- Faster RCNN
- Fast RCNN
- nerf
- YAI 11기
- cl
- YAI 9기
- 컴퓨터 비전
- YAI 8기
- RCNN
- CS224N
- VIT
- GaN
- cv
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- Today
- Total
목록강화학습 (3)
연세대 인공지능학회 YAI
 [논문 리뷰] Playing Atari with Deep Reinforcement Learning
[논문 리뷰] Playing Atari with Deep Reinforcement Learning
YAI 9기 박찬혁님이 논문구현팀에서 작성한 글입니다. 논문 Playing Atari with Deep Reinforcement Learning Playing Atari with Deep Reinforcement Learning 이번 논문에서는 강화학습을 위한 첫번째 딥러닝 모델인 DQN을 소개한다. 기존의 강화학습과 DNN을 결합시키기에는 몇가지 문제점이 있었다. 보통의 딥러닝 지도학습 task들은 라벨링 된 데이터들이 있었지만 강화학습에서는 이런 데이터들이 거의 없으며 노이즈가 많고 딜레이가 있는 reward를 통해 학습을 진행시켜야한다. 또한, 기존 딥러닝은 데이터간의 연관 관계가 없는 독립 관계라고 가정하고 진행하지만 강화학습의 경우 각 state들이 큰 연관성이 있다. 이 어려움들을 해결하고 강..
 [논문 리뷰] Playing Atari with Deep Reinforcement Learning
[논문 리뷰] Playing Atari with Deep Reinforcement Learning
Playing Atari with Deep Reinforcement Learning https://arxiv.org/abs/1312.5602 *YAI 10기 최서연 님이 작성한 글입니다. 1. Introduction 기존의 RL algorithm들은 모두 직접 사람이 만든 linear value function이나 policy representation들을 사용했었다. 하지만 비전이나 자연어같은 분야들에서 neural network들을 사용한 알고리즘이 굉장히 성공을 거두며 RL에도 비슷한 종류의 net을 사용할 수 있는 지가 논의의 중심이 되었다. Reinforcement Learning에는 항상 풀지 못하는 숙제들이 있다. Sparse & Delayed Rewards input과 target값이 바로..
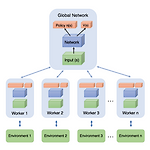 [논문 리뷰] Asynchronous Methods for Deep Reinforcement Learning
[논문 리뷰] Asynchronous Methods for Deep Reinforcement Learning
YAI 9기 이상민님이 강화학습 논문구현팀에서 작성한 글입니다 Asynchronous Methods for Deep Reinforcement Learning Asynchronous Methods for Deep Reinforcement Learning 🌎YAI 9기 이상민 논문소개 Asynchronous Methods for Deep Reinforcement Learning Simple and lightweight Deep Reinforcement Learning framework multi core CPU instead of GPU. Asynchronous gradient descent Parallel A3C Introduction Deep nueral networks가 Reinforcement Lea..