
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- NLP
- YAI 10기
- VIT
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- Googlenet
- rl
- 연세대학교 인공지능학회
- YAI
- CNN
- 컴퓨터 비전
- RCNN
- YAI 8기
- CS224N
- GaN
- cv
- PytorchZeroToAll
- 강화학습
- transformer
- nerf
- YAI 11기
- 자연어처리
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- Faster RCNN
- Perception 강의
- cl
- 컴퓨터비전
- 3D
- YAI 9기
- CS231n
- Fast RCNN
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] Mask R-CNN 본문
Mask R-CNN
** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다.
1. Introduction
- 비전 분야에서 객체 감지와 시멘틱 세그멘테이션은 단기간에 빠르게 성장했다.
- 이러한 발전은 대부분 Fast/Faster R-CNN과 FCN같은 강력한 기준 시스템에 의해 이루어졌다.
- 이 시스템들은 개념이 직관적이며, 유연성과 강건성(robustness)을 가질 뿐만 아니라 빠른 훈련 및 추론이 가능하다.
- 이 논문의 목표는 인스턴스 세그멘테이션에 대해 이와 비슷한 수준의 프레임워크를 개발하는 것이다.
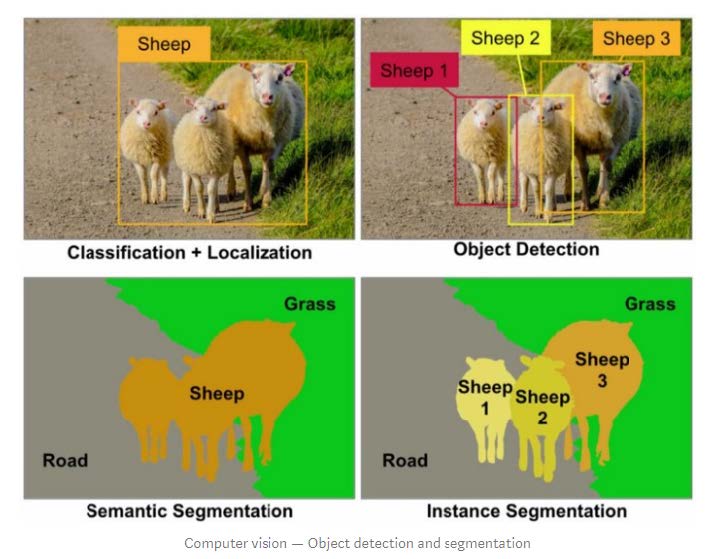
1-1. Instance Segmentation
- 인스턴스 세그멘테이션은 이미지 내 모든 객체의 올바른 탐지와 각 인스턴스에 대한 정확한 분할이 동시에 이루어져야 하는 도전적인 작업이다.
- 따라서 다음의 두 가지 컴퓨터 비전 작업이 결합된다.
- 객체 탐지: 각 객체를 분류하고 bounding box로 localize한다.
- 시멘틱 세그멘테이션: 객체 인스턴스를 구분하지 않고 각 픽셀을 고정된 범주의 집합으로 분류한다.
1-2. Overview

- 이 논문의 시스템인 Mask R-CNN은 Faster R-CNN의 각 RoI에서 기존 본류 및 bounding box 회귀를 위한 branch에 병렬적으로 세그멘테이션 마스크 예측을 위한 branch를 추가하여 Faster R-CNN을 확장한다.
- Mask branch는 각 RoI에 적용되는 작은 FCN으로 pixel-to-pixel 방식으로 세그멘테이션 마스크를 예측한다.
- Mask R-CNN은 넓은 범위의 아키텍쳐 설계가 용이한 Faster R-CNN을 사용하므로 구현과 훈련이 간단하며, mask branch가 작은 크기의 계산 오버헤드만 추가하므로 시스템의 속도가 빠르다.
- Mask R-CNN은 Faster R-CNN의 단순한 확장이지만, mask branch를 적절히 구현하는 것이 좋은 결과를 내는데 중요하다.
- 중요한 점은 Faster R-CNN이 신경망의 입출력 사이에서 pixel-to-pixel alignment를 위해 설계되지 않았다는 것이다.
- 이 사실은 인스턴스 처리의 핵심 연산인 RoIPoo이 feature extraction에서 quantization를 수행한다는 점에서 가장 분명하게 나타난다.
- 논문에서는 이 misalignment를 수정하기 위해 RoIAligh이라고 부르는, 공간 위치를 정확하게 보존하며 단순하고 양자화가 없는 레이어를 제안한다.
- RoIAlign은 더 엄격한 localization metric에서 마스크 정확도의 상당한 향상을 만들어낸다.
- 이 레이어에서는 마스크와 클래스 예측을 분리하는 것이 필수적이다. 클래스 간에 경쟁없이, 각 클래스에 대해 독립적으로 이진 마스크를 예측하고 신경망의 RoI 분류 branch에 의존하여 범주를 예측한다.
- FCN은 일반적으로 세그멘테이션과 분류가 결합된 픽셀당 다중 클래스 분류를 수행하는데, 이 논문의 실험 결과 인스턴스 세그멘테이션에서는 제대로 작동하지 않았다.
- 어떠한 추가 없이, Mask R-CNN은 COCO 인스턴스 세그멘테이션 작업에서 기존의 모든 SOTA 단일 모델 결과를 능가했다.
- 추가적으로 COCO 객체 탐지 작업에서도 탁월한 성능을 보여주었다.
- Ablation 실험에서는 다양한 기본 인스턴스화를 평가하며 이를 통해 강건성을 입증하고 핵심 요소의 효과를 분석한다.
- 이 논문의 모델은 GPU에서 200ms/frame (= 5 fps)로 실행되며, 하나의 8-GPU 시스템에서 COCO를 훈련시키는데 1~2일이 소요된다.
- 이 논문의 마지막에는 COCO keypoint 데이터셋에서 human pose estimation을 통해 프레임워크의 일반화 정도를 보여준다.
- 각 keypoint를 one-hot 이진 마스크로 생각하면, Mask R-CNN에 약간의 수정을 가하여 인스턴스별 pose를 탐지할 수 있다.
- 이 수정된 모델 또한 2016 COCO keypoint 우승 모델을 능가했으며, 또한 5 fps로 실행이 된다.
- 따라서 Mask R-CNN은 인스턴스 인식을 위한 유연한 프레임워크로 볼 수 있으며, 복잡한 작업에 손쉽게 확장이 가능하다.
2. Related Work
2-1. R-CNN
- Bounding box 객체 탐지에 대한 region-based CNN 접근 방법은 다룰 수 있는 수의 object region 후보들에 집중하고, 각 RoI에 대해 독립적으로 CNN을 평가한다.
- R-CNN은 RoIPool을 사용하여 feature map에서 RoI에 집중하며, 이를 통해 빠른 속도와 더 나은 정확도를 보여준다.
- Faster R-CNN은 Region Proposal Network (RPN)을 통해 attention 매커니즘을 학습하여 R-CNN의 시스템을 발전시켰다.
- Faster R-CNN은 많은 개선을 통해 유연하고 강건해졌으며, 현재 여러 벤치마크에서 최고의 프레임워크이다.
2-2. Instance Segmentation
- R-CNN의 효율성에 힘입어, 인스턴스 세그멘테이션에 대한 많은 접근 방식은 segment proposal을 기반으로 한다.
- DeepMask 등이 모델들은 segment 후보를 제안하도록 학습했으며, 제안된 후보들은 Fast R-CNN에 의해 분류되었다.
- 이러한 방법에서는 세그멘테이션이 인식 작업보다 우선하므로 느리고 부정확하다.
- 마찬가지로 Dai et al.은 bounding box proposal에서 segment proposal을 예측한 후 분류하는 다단계 cascade를 제안했다.
- Li et al.은 최근 "fully convolutional instance segmentation" (FCIS)를 위해 instance-sensitive FCN의 segment proposal 시스템과 R-FCN의 객체 탐지 시스템을 결합했다.
- 모델들의 일반적인 아이디어는 일련의 position-sensitive 출력 채널을 fully convolutional 방법으로 예측하는 것이다.
- 이 채널들을 객체의 클래스, box, 그리고 마스크를 동시에 처리하여 시스템을 빠르게 만든다.
- 하지만 FCIS는 중복되는 인스턴스에 대해 시스템적 오류를 만드며, 가상의 edge를 만들어내어 인스턴스 세그멘테이션의 근본적인 어려움에서 벗어나지 못했다 (Figure 6 참고).
- 시멘틱 세그멘테이션의 성공에 의존하여 만들어진 인스턴스 세그멘테이션 접근 방법들이 존재한다.
- 픽셀당 분류 결과 (e.g., FCN 출력)로 시작하여 같은 범주에 해당하는 픽셀들을 다른 인스턴스로 자른다.
- 이들의 segmentation-first 전략과 반대로 Mask R-CNN은 instance-first 전략에 기반한다.
3. Mask R-CNN
- Mask R-CNN의 개념은 간단하며 자연스럽고 직관적이다.
- Faster R-CNN은 각 후보 객체에 대해 클래스 레이블과 bounding-box offset 출력을 가진다.
- Mask R-CNN에서는 객체 마스크를 출력하는 세 번째 branch를 추가한다.
- 추가적인 마스크 출력은 클래스 및 box 출력과 구별되며 객체의 자세한 레이아웃 추출이 필요하다.
- 이 section에서는 pixel-to-pixel alignment와 같은 Mask R-CNN의 핵심 요소들을 소개한다.
3-1. Faster R-CNN

- Faster R-CNN은 두 단계를 포함한다.
- Region Proposal Network (RPN): 객체의 bounding box 후보를 제안한다.
- RoI Pooling Layer (RoIPool): 각 box 후보에서 feature를 추출하고 분류와 bounding box 회귀를 수행한다.
- 두 스테이지에서 사용하는 feature는 서로 공유되어 더 빠른 추론이 가능하게 한다.
3-2. Mask R-CNN
- Mask R-CNN은 Faster R-CNN의 두 단계를 채택하고, 첫번째 단계는 동일하게 사용한다.
- 두번째 단계에서는 클래스와 box offset 예측과 동시에 각 RoI에 대한 이진 마스크를 출력한다.
- 이는 분류가 마스크 예측에 의존하는 최근 시스템들과는 대조된다.
- 논문의 접근 방법은 bounding-box의 분류와 회귀를 병렬로 수행하는 Fast R-CNN의 기조를 따른다.
- 훈련에서는 각 샘플링된 RoI의 multi-task loss를 $L = L_{cls} + L_{box} + L_{mask}$로 정의한다.
- 분류 손실 $L_{cls}$와 bounding-box 손실 $L_{box}$는 Fast R-CNN의 손실과 동일하다.
- 마스크 branch는 각 RoI마다 $Km^2$ 차원의 출력을 만들어 이 출력은 $K$개 $m \times m$ 이진 마스크의 인코딩이다.
- 이에 대해 픽셀별 시그모이드를 적용하여, $L_{mask}$를 이진 크로스 엔트로피 손실의 평균으로 정의한다.
- Ground-truth 클래스 $k$와 관련된 RoI에 대해 $L_{mask}$는 $k$번째 마스크에만 정의된다.
- $L_{mask}$의 이러한 정의는 신경망이 클래스 간 경쟁 없이 모든 클래스에 대해 마스크를 생성할 수 있도록 한다.
- 이때, 출력 마스크를 선택하는데 사용되는 클래스 레이블 예측은 분류 branch에 의존한다.
- 이는 마스크 예측과 클래스 예측을 분리한다.
- 이는 FCN이 시멘틱 세그멘테이션에서 픽셀당 소프트맥스와 다항 크로스 엔트로피 손실을 사용하는 것과 다르다.
- 이 일반적인 관습에서는 마스크가 클래스 사이에서 경쟁한다.
- Mask R-CNN에서는 픽셀당 시그모이드와 이진 크로스 엔트로피 손실을 사용하므로 경쟁을 하지 않는다.
3-3. Mask Representation
- 마스크는 입력 객체의 공간적 레이아웃을 인코딩한다.
- 따라서 fc 레이어에 의해 불가피하게 짧은 출력 벡터로 축소되는 클래스 레이블이나 box offset과는 다르게, 마스크의 공간 구조를 추출하는 것은 컨볼루션에 의해 제공되는 pixel-to-pixel 유사성에 의해 자연스럽게 처리될 수 있다.
- 특히 FCN을 사용하여 각 RoI로부터 $m \times m$ 마스크를 예측한다.
- 이를 통해 마스크 branch의 각 레이어는 공간 차원이 없는 벡터 표현으로 축소되지 않고 명시적인 $m \times m$ 객체 공간 레이아웃을 유지할 수 있다.
- 마스크 예측을 위해 fc 레이어에 의존하는 이전의 방법들과 다르게, 논문의 fully convolutional representation은 더 적은 수의 파라미터를 요구하며 더 정확하다.
- 한편, 이 pixel-to-pixel 동작을 수행하려면 작은 feature map이 RoI feature가 픽셀에서 뚜렷한 공간 유사성을 유지하기 위해 적절한 alignment가 되어야 한다.
- 이를 위해 논문에서는 마스크 예측에서 핵심적인 역할을 하는 RoIAlign 레이어를 소개한다.
3-4. RoIAlign

- RoIPool은 각 RoI에서 feature map (e.g., 7 x 7)을 추출하는 표준 연산이다.
- 먼저 소수점 크기의 RoI를 이산적인 feature map 위로 양자화한다.
- 이 quantized RoI는 다시 자체적으로 양자화된 bin으로 나뉘게 된다.
- 이 각 bin의 feature 값은 마지막으로 일반적으로 최대 풀링을 사용하여 합쳐진다.
- 양자화는 예를 들어 연속 좌표 $x$를 $[x/16]$으로 (이때, 16은 feature map stride) 반올림하거나, bin으로 나누어 수행된다.
- 이러한 연산은 RoI와 추출된 feature 사이에 misalignment를 만들어낸다.
- 분류가 작은 변형에 강건성을 가지므로 영향을 받지 않을 수는 있지만, 픽셀에 정확한 마스크를 예측하는 데에 큰 부정적인 영향을 미친다.
- 이를 해결하기 위해, RoIPool의 양자화를 없애고 추출된 feature를 입력에 정렬하는 RoIAlign 레이어를 제안한다.
- RoI 경계나 bin의 양자화를 방지하는 것이 주된 변경사항이다. 예를 들어 $[x/16]$ 대신에 $x/16$을 사용한다.
- RoIAlign에서는 쌍선형 보간법을 사용하여 각 RoI bin의 4개의 regularly sampled location에서 입력 feature의 정확한 값을 계산하고 결과를 종합한다 (Figure 3 참고).
- 양자화가 수행되지 않으므로 계산 결과는 정확한 샘플링 위치나 샘플링된 좌표의 수에 강건하다.
- RoIAlign이 모델에 커다란 향상을 일으켰는데, 이는 section 4.2에서 설명한다.
- 또한 RoIWrap와도 비교를 진행했는데, RoIWrap는 정렬 문제를 간과하고 RoIPool처럼 RoI를 양자화한다.
- 따라서 RoIWrap가 쌍선형 리샘플링을 채택했음에도, 실험에서 볼 수 있듯이 RoIPool과 동등하게 수행하여 alignment의 중요성을 보여준다.
3-5. Network Architecture
- 논문에서는 접근 방법의 일반성을 입증하기 위해 다양한 아키텍처에 Mask R-CNN을 적용했다.
- 명료함을 위해 다음의 두 구조를 구분하여 설명한다.
- 전체 이미지에 대한 feature 추출에 사용되는 convolutional backbone 아키텍쳐
- 각 RoI에 적용되는 bounding-box 인식 (분류 및 회귀)과 마스크 예측을 위한 신경망 head
- 논문에서는 network-depth-feature의 명명법을 사용하여 backbone 아키텍처를 표기했다.
- 예를 들어, Faster R-CNN이 50 레이어의 ResNet 신경망을 사용할 때는 4번째 stage의 컨볼루션 레이어 C4에서 feature를 추출하는데, 이러한 신경망은 ResNet-50-C4로 표기한다.
- 이 논문에서는 ResNet과 더불어, Lin et al.의 효과적인 backbone인 Feature Pyramid Networks (FPN)도 확인한다.
- FPN은 lateral connection과 top-down 아키텍처를 사용하여 단일 스케일 입력으로부터 신경망 내부 feature pyramid를 생성한다.
- FPN backbone을 사용한 Faster R-CNN은 스케일에 따라 feature pyramid의 서로 다른 수준에서 RoI feature를 추출하며, 그 외 나머지 구조는 기본적인 ResNet과 유사하다.
- Feature 추출에 Mask R-CNN과 ResNet-FPN backbone을 사용하는 것은 정확도와 속도 측면에서 탁월한 이득을 얻을 수 있다.
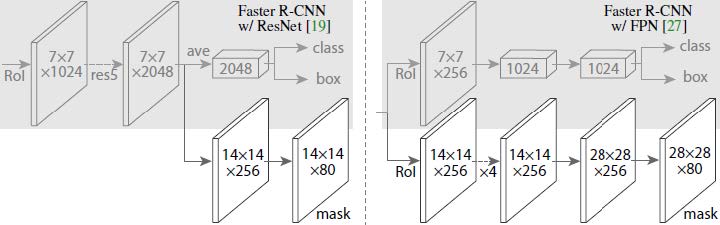
- 신경망 head의 경우 fully convolutional 마스크 예측 branch를 추가한 이전 작업에서 제시한 아키텍처를 따른다.
- ResNet과 FPN 논문에서 Faster R-CNN box head를 확장한다 (Figure 4 참고).
- ResNet-C4 backbone의 head는 ResNet의 계산 집약적인 5번째 stage (9개 레이어 'res5')를 포함한다.
- FPN에서는 backbone이 이미 res5을 포함하므로 filter를 적게 사용하는 보다 효율적인 head를 사용할 수 있다.
4. Implementation Details
- 하이퍼파라미터로는 기존의 Fast/Faster R-CNN을 따라서 사용했다.
- 객체 탐지를 위한 모델들이지만, Mask R-CNN은 이 하이퍼파라미터들에 강건하다.
4-1. Training
- RoI는 Fast R-CNN처럼 ground-truth box와 IoU overlap이 0.5 이상일 경우 양성, 그렇지 않을 경우 음성으로 적용했다.
- 마스크 손실 $L_{mask}$는 양성 RoI에만 정의된다.
- 마스크 타깃은 RoI와 관련된 ground-truth 마스크 사이의 교집합을 이루는 픽셀들이다.
- 논문에서는 image-centric training (hiarchical sampling)을 채택했다.
- 이미지는 스케일(짧은 면)이 800픽셀이 되도록 리사이징되었다.
- 각 미니배치는 GPU당 2 이미지를 사용했으며, 각 이미지는 양성 대 음성 비율이 $1:3$인 $N$개의 샘플링된 RoI를 가진다.
- $N$은 C4 backbone에서는 64, FPN에서는 512로 사용되었다.
- 8개의 GPU에서 16만회의 훈련을 진행했으며 (미니배치 크기가 16이 되는 효과), 0.02의 학습률을 사용했다.
- 가중치 감쇠를 0.0001에 모멘텀 0.9로 사용했다.
- ResNeXt에서는 GPU당 1 이미지를 학습률 0.01로 16만회 훈련시켰다.
- RPN anchor는 FPN처럼 5 스케일 3 종횡비로 사용된다.
- 편리한 ablation을 위해 RPN은 분리되어 훈련되었으며 Mask R-CNN과 feature를 공유하지 않는다.
- 모든 실험에서 RPN과 Mask R-CNN은 같은 backbone을 가지고 있으므로 feature를 공유할 수는 있다.
4-2. Inference
- 테스트 동안에는 proposal의 수를 C4 backbone에서 300, FPN에서 1000으로 사용했다.
- 이 proposal에서 box 예측 branch 이후에 비최대 억제(NMS)를 수행했다.
- 이후에 상위 100개의 탐지된 box에 대해 마스크 branch가 적용되었다.
- 이러한 과정이 훈련의 병렬 연산과는 다를 수 있지만, (더 적은 수의 정확한 RoI를 사용하므로) 추론을 빠르게 하며 정확도를 향상시킨다.
- 마스크 branch가 RoI별로 $K$ 마스크를 예측하지만 분류 branch에서 예측된 클래스 $k$에 해당하는 마스크만 사용한다.
- $m \times m$ 소수점 마스크 출력이 RoI 크기로 리사이징되며, threshold 0.5로 이진화한다.
- 시스템은 상위 100개의 탐지된 box만 사용하므로 Mask R-CNN은 Faster R-CNN에 (일반적인 모델의 ~20%) 작은 오버헤드를 추가한다.
5. Experiments: Instance Segmentation
- COCO 데이터셋에서 종합적인 ablation과 함께 SOTA와 Mask R-CNN을 비교했다.
- $AP, AP_{50}, AP_{75}, AP_{S}, AP_{M}, AP_{L}$ 등의 COCO metric을 기록했다.
- 기본적으로 $AP$는 mask IoU로 측정되었다.
- FPN처럼 80k 훈련 이미지와 35k 검증 데이터 부분집합 (trainval35k)을 합쳐 훈련시켰으며, 남은 5k의 검증 데이터 이미지(minival)에 대해 ablation을 기록했다. Test-dev에 대해서도 결과를 기록했다.
5-1. Main Results


- Table 1은 인스턴스 세그멘테이션에서 Mask R-CNN과 SOTA 방법들을 비교하고 있다.
- Mask R-CNN의 모든 구현이 SOTA의 baseline을 능가한다.
- Mask R-CNN의 출력은 Figure 2와 5에 시각화되어 있다.

- Figure 6에서는 FCIS+++와 Mask R-CNN을 비교한다.
- FCIS+++에서는 중복되는 인스턴스에서 상당한 아티팩트를 만들어내어 인스턴스 세그멘테이션의 근본적인 어려움을 보여준다. Mask R-CNN에서는 이러한 아티팩트를 보여주지 않는다.
5-2. Ablation Experiments

5-2-1. Architecture
- 신경망이 깊고, FPN과 ResNeXt를 포함한 발전된 디자인에서 효과가 있었다.
- 모든 프레임워크가 깊고 발전된 신경망에서 자동적으로 이득을 보는 것은 아니다.
5-2-2. Multinomial vs. Independent Masks


- 앞에서 설명하듯이, Mask R-CNN은 마스크 예측과 클래스 예측을 분리한다.
- Box branch가 클래스 레이블을 예측하면, 마스크 branch에서는 클래스간 경쟁 없이 각 클래스별 마스크를 생성한다.
- 여기에서는 픽셀당 소프트맥스와 다항 손실을 사용하여 모델의 픽셀당 시그모이드와의 이진 손실을 비교한다.
- 이 비교 모델은 마스크와 클래스 예측을 결합한다.
- 그 결과 시그모이드를 사용한 모델이 우세했으며, 이는 인스턴스가 일단 분류된다면 범주에 상관 없이 이진 마스크를 예측하는 것이 충분하므로 모델을 더 쉽게 훈련할 수 있다는 것을 의미한다.
5-2-3. Class-specific vs. Class-agnostic Masks
- Mask R-CNN의 일반적인 인스턴스화는 class-specific 마스크를 예측한다.
- 흥미롭게도, class-agnostic 마스크를 예측하는 경우에도 기본 모델과 비슷한 효과를 보여주었다.
- ResNet-50-C4에서 class-specific과 class-agnostic 각각 30.3과 29.7의 마스크 AP를 얻었다.
- 이는 Mask R-CNN에서 분류와 세그멘테이션을 분류하기 때문으로 볼 수 있다.
5-2-4. RoIAlign

- 제안된 RoIAlign 레이어의 평가는 Table 2c에서 볼 수 있다. 이 실험은 stride 16의 ResNet-50-C4 backbone을 사용했다.
- RoIAlign은 RolPool에 비해 3 AP 정도의 향상이 있었으며, 높은 IoU overlap의 경우 더 많은 향상이 있었다.
- RoIAlign은 max pool과 average pool 사이 큰 차이가 없었으며, 나머지 실험에서는 average pool을 사용했다.
- 추가적으로 MNC에서 제안한 RoIWarp 또한 비교했다.
- Section 3에서 설명했듯이 RoIWarp도 쌍선형 샘플링을 사용하지만 RoI를 양자화하여 alignment를 유지하지 못한다.
- RoIWarp는 RoIPool과 비슷하고 RoIAlign보다 좋지 못한 성능을 보여주며 적절한 alignment가 필요함을 보여준다.

- 논문에서는 또한 stride 32의 ResNet-50-C5-backbone에서의 RoIAlign도 평가했으며, 이는 Table 2d에서 확인할 수 있다.
- 이 backbone의 경우 res5 head를 사용할 수 없으므로 Figure 4 우측의 head를 사용했다.
- RoIAlign은 마스크 AP를 7.3, $AP_{75}$를 10.5나 향상시켰다.
- 또한, 이 backbone에서의 RoIAlign은 stride-16 C4 feature보다도 높은 $AP$를 기록했다.
- RoIAlign은 객체 탐지와 세그멘테이션에서 큰 stride의 feature를 사용하는 것의 문제를 해결했다.
- RoIAlign은 더 미세한 다수준 stride를 갖는 FPN과 함께 사용될 때 1.5 마스크 $AP$ 및 0.5 box $AP$를 보여주었다.
- 더 미세한 alignment를 필요로 하는 keypoint detection에서 RoIAlign은 FPN과 같이 사용할 경우 높은 성능 향상을 보여준다.
5-2-5. Mask Branch

- 세그멘테이션은 pixel-to-pixel 작업이므로 FCN을 사용하여 공간 레이아웃을 활용했다.
- Table 2e에서는 ResNet-50-FPN backbone을 사용하여 MLP와 FCN을 비교했다.
- FCN이 MLP보다 우세한 AP를 얻었다.
- 공정한 비교를 위해 FCN head의 컨볼루션 레이어가 사전훈련되지 않도록 이 backbone을 사용했다.
5-3. Bounding Box Detection Results

- Table 3에서는 COCO bounding box 탐지의 SOTA와 Mask R-CNN을 비교했다.
- 여기에서는 Mask R-CNN 전체가 훈련되지만, 추론시에는 분류와 box의 출력만 사용되었다.
- ResNet-101-FPN을 사용한 Mask R-CNN이 기존의 모든 SOTA 모델의 기본 변형들의 성능을 능가한다.
- ResNeXt를 사용할 경우 더 높은 성능을 보여준다.
- 추가 비교를 위해 마스크 branch 없는 Mask R-CNN을 훈련했으며, Table 3의 "Faster R-CNN, RoIAlign"에서 확인할 수 있다.
- 이 모델은 RoIAlign을 사용하므로 다른 모델보다는 성능이 좋다.
- 하지만 Mask R-CNN보다는 box AP가 낮은데, 이는 Mask R-CNN이 multi-task 훈련으로 이득을 보았기 때문이다.
- 마지막으로, Mask R-CNN은 실험에서 마스크와 box 사이에 작은 AP 차이만 보여주는데, 이는 논문의 접근 방식이 객체 감지와 (더 까다로운) 인스턴스 세그멘테이션 작업 사이의 격차를 크게 줄여줌을 의미한다.
5-4. Timing
5-4-1. Inference
- RPN과 Mask R-CNN stage에서 feature를 공유하는 ResNet-101-FPN을 Faster R-CNN의 4단계 alternative training으로 훈련시켰다.
- 당시 기준으로 빠른 추론 속도를 보였으나, 이 디자인은 속도에 최적화되지 않았다.
- 더 나은 속도/정확도 트레이드오프를 만들 수 있으나, 이 논문 범위 밖의 내용이다.
5-4-2. Training
- Mask R-CNN은 훈련 또한 빠르며, 이는 인스턴스 세그멘테이션 분야에서 주요한 장애물을 제거하는 계기가 되었다.
6. Mask R-CNN for Human Pose Estimation
- 논문의 프레임워크는 human pose estimation으로 쉽게 확장될 수 있다.
- Keypoint 위치를 one-hot 마스크로 모델링하고, Mask R-CNN이 $K$ 개의 keypoint 타입에 대한 마스크를 예측한다.
- 이 실험은 Mask R-CNN 프레임워크의 일반성을 입증하기 위해 진행되었으므로, human pose에 대한 최소한의 도메인 지식으로 진행되었다.
6-1. Implementation Details
- Keypoint 탐지에 세그멘테이션 시스템을 약간의 수정을 거쳐서 사용했다.
- 인스턴스의 각 $K$ keypoint에 대한 훈련 타깃은 오직 하나의 픽셀이 foreground로 레이블된 one-hot $m \times m$ 이진 마스크이다.
- 훈련 동안, 이미지에서 보이는 각 ground-truth keypoint에 대해 (단일 지점이 탐지되도록) $m^2$ -way 소프트맥스 출력에 대한 크로스 엔트로피 손실을 최소화한다.
- 인스턴스 세그멘테이션 작업이므로, $K$개의 keypoint는 독립적으로 처리된다.
- 논문에서는 ResNet-FPN backbone을 채택했으며, keypoint의 head 아키텍쳐는 Figure 4의 우측과 비슷하게 구현되었다.
- Keypoint headsms 8개의 3 x 3 x 512 conv layer 스택과 뒤이은 deconv layer와 2 x bilinear upscailing으로 이루어진다.
- Head를 통과하여 만들어지는 출력 해상도는 56 x 56이다.
- Keypoint-level localization의 정확성을 위하 keypoint head는 마스크 head에 비해 높은 해상도를 만들어야 한다.
- 모델은 keypoint가 존재하는 모든 COCO trainval35k 이미지에 훈련되었다.
- 훈련 세트가 작으므로 과대적합을 방지하기 위해 [640, 800] 픽셀에서 무작위로 샘플링된 이미지로 훈련되었다. 추론은 800 픽셀의 단일 스케일에서 이루어졌다.
- 훈련은 90k로 반복되었고, 0.02의 학습률을 60k와 80k 반복에서 0.1배로 줄어들도록 진행되었다.
- Bounding-box에 대해 threshold 0.5의 NMS를 사용했다.
- 나머지 세부 사항은 section 3.1의 설정과 동일하다.
6-2. Main Results and Ablation



- ResNet-50-FPN backbone으로 person keypoint AP ($AP^{kp}$)를 측정했으며, 부록에서 더 많은 backbone을 연구했따.
- Table 4에서 보듯이 Mask R-CNN을 사용한 모델의 결과가 multi-stage processing pipepline을 사용한 COCO의 SOTA보다 우세하다.
- 더 중요한 점은 논문의 모델이 box, segment, 그리고 keypoint를 빠른 속도로 동시에 예측하는 통합된 모델이라는 것이다.
- Person 범주에 대해 segment branch를 추가하는 것이 $AP^{kp}$를 63.1로 더 상승시킨다.
- 다른 ablation은 Table 5에서 보여주고 있다.
- 마스크 branch를 box-only (Faster R-CNN)나 keypoint-only 버전에 추가했을 때 성능이 향상되었다.
- 하지만 keypoint branch를 추가하는 것이 box/mask AP를 약간 낮추었는데, 이는 keypoint 탐지 작업이 멀티태스크 훈련에서 도움을 받을 수는 있지만, 다른 작업에 도움을 주지는 않음을 의미한다.
- 그럼에도 불구하고 이 세 가지 작업을 모두 학습하는 것은 통합된 시스템이 모든 출력을 동시에 효율적으로 예측하게 한다는 점에서 이점이 있다.

- 논문에서는 또한 keypoint 탐지에서 RolAlign의 효과를 탐구했다.
- ResNet-50-FPN backbone이 작은 stride를 가지고 있지만, RolAlign은 RolPool에 비해 상당한 성능 향상을 이끌었다.
- 이는 keypoint 탐지 작업이 localization의 정확도보다 민감하기 때문이며, 픽셀 수준 localization에서 alignment의 중요성을 보여준다.
- 객체의 bounding box, 마스크, 그리고 keypoint를 추출하는 면에서 Mask R-CNN의 효율성을 통해, 다른 인스턴스 수준의 작업에서도 이 시스템은 효과적인 프레임워크가 될 것이라고 기대할 수 있다.
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Going Deeper with Convolutions (0) | 2022.08.13 |
|---|---|
| [논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks (0) | 2022.05.08 |
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] FPN : Feature Pyramid Network (0) | 2022.03.12 |
| [논문 리뷰] R-CNN / Fast R-CNN / Faster R-CNN (3) (0) | 2022.03.12 |



