
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- cl
- CS224N
- nerf
- 컴퓨터비전
- YAI 10기
- CNN
- Fast RCNN
- 강화학습
- 컴퓨터 비전
- Faster RCNN
- YAI 11기
- 3D
- CS231n
- VIT
- RCNN
- transformer
- 자연어처리
- Perception 강의
- YAI 9기
- cv
- PytorchZeroToAll
- Googlenet
- YAI
- GaN
- 연세대학교 인공지능학회
- YAI 8기
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- rl
- NLP
- Today
- Total
목록cv (25)
연세대 인공지능학회 YAI
 [논문 리뷰] Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation
[논문 리뷰] Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation
Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation https://arxiv.org/abs/1809.07454 Conv-TasNet: Surpassing Ideal Time-Frequency Magnitude Masking for Speech Separation Single-channel, speaker-independent speech separation methods have recently seen great progress. However, the accuracy, latency, and computational cost of such methods remain insufficient. The ma..
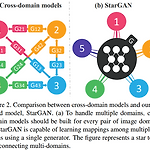 [논문 리뷰] StarGAN
[논문 리뷰] StarGAN
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation YAI 8기 안용준님이 GAN팀에서 리뷰하신 논문입니다. 0. Abstract 현재까지의 연구는 2개 도메인에서의 image2image translation이었다. 2개 이상의 도메인에서 scalability, robustness가 제한적이다. 왜냐하면 모든 도메인 pair마다 모델이 설계되어야 하기 때문이다. 이를 개선하고자, 모든 도메인 간 변환을 한 모델로 가능하게 하는 starGAN을 고안하였다. 이러한 통합 모델은 여러 개의 데이터셋들을 동시에 학습시킬 수 있다. 기존의 모델들보다 생성 이미지 퀄리티가 좋을 뿐만 아니라, 원하는 도..
 [Deep Learning for Computer Vision] Training Neural Network / Recurrent Network / Attention
[Deep Learning for Computer Vision] Training Neural Network / Recurrent Network / Attention
** YAI 10기 김성준님이 기초심화팀에서 작성한 글입니다. 1. Lecture 11: Training Neural Networks II Learning Rate Schedules Learning rate 를 너무 큰 값으로 설정하면 밖으로 튀어나가 버리고(explosion), 너무 작은 값으로 설정하면 학습 속도가 매우 느려지므로 적절한 값으로 설정하는 것이 중요하다. 하지만 이게 쉽지는 않은데... 이를 해결하기 위해 learning rate 를 특정 epoch 마다 규칙 적으로 감소시키는 방법이 있다. 위의 사진으로부터 learning rate 가 감소하는 지점마다 loss 도 계단 모양으로 감소함을 확인할 수 있다. 하지만 이 방식은 learning rate 를 얼마마다 감소시켜야 하는지 등을 ..
 [논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ** YAI 9기 박찬혁님이 비전논문팀에서 작성한 글입니다. Introduction 현재 Transformer와 같은 Self-attention-based 구조들이 NLP에서 주된 방식이다. 이 방법들은 주로 큰 모델에서 사전학습을 진행 후에 작은 데이터셋으로 Fine tuning하여 사용하는 방식으로 쓰인다. 이 Transformer 방식을 이미지에 바로 적용시키는 것이 이 논문의 목적이다. 이미지를 patch라는 작은 단위로 나누어서 NLP의 token과 같은 방식으로 간단한 imbedding 후에 Transformer에 집어넣는다. 이 방식은 기존 CNN이 이미지에 ..
 [논문 리뷰] Going Deeper with Convolutions
[논문 리뷰] Going Deeper with Convolutions
Going Deeper with Convolutions YAI 9기 김석님이 비전논문기초팀에서 작성한 글입니다. 0. Abstract 목적 → Network 내에서 compute가 진행될 시 소모되는 자원의 효율성을 높이기 위함 Method Compute 할 양을 늘어나지 않는 상태에서 depth와 width를 늘릴 수 있는 디자인 (codenamed Inception) Optimization 방법 → Hebbian principle에 근거한 multi-scale processing 사용 GoogLeNet Proposal Classification과 detection 목적으로 설계된 22 layer deep network 1. Backgrounds Object detection에서 사용한 방법 → Mod..
 [강의 리뷰] The Background of Perception (2)
[강의 리뷰] The Background of Perception (2)
[Perception 강의 리뷰] 1주차: The Background (2) * YAI 9기 김동하, 박준영님이 Perception 강의팀에서 작성한 글입니다. 2. Visual Stimuli 2-1. Visual Stimuli 위와 같은 전자기파의 스펙트럼 중에서, 인간은 380-750 nm의 wavelength에 해당하는 가시광선(light) 만을 인식할 수 있도록 진화해왔다. 다른 스펙트럼의 전자기파는 볼 수 없는 대신 측정으로 존재를 알 수 있다. 사실, 다른 동물들도 볼 수 있는 영역은 동물마다 차이가 있겠지만 대부분 이 영역과 비등비등하다. 이는 다음과 같은 이유가 있겠다. Ultra Violet 영역 이전 자외선 및 그보다 frequency가 높은 electromagnetic wave는 에너..
 [논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
[논문 리뷰] NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis **YAI 8기 김현진님이 비전 논문 심화팀에서 작성한 글입니다. European Conference on Computer Vision (ECCV), 2020 (Best Paper Honorable Mention) https://arxiv.org/pdf/2003.08934.pdf 3. Neural Radiance Field Scene Representation 이 논문에서는 연속적인 장면들을 5D 벡터 함수의 형태 (Radiance Field)로 나타낸다. Input은 위치 (x, y, z), 방향 (θ, ϕ) 이고, Radiance와 Radiance의 양을 조절하는 volume..
 [논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
[논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++ ** YAI 9기 조용기님이 비디오논문팀에서 작성한 글입니다. Paper: https://openaccess.thecvf.com/content_CVPR_2019/papers/Li_SiamRPN_Evolution_of_Siamese_Visual_Tracking_With_Very_Deep_Networks_CVPR_2019_paper.pdf 1. Introduction Visual Object Tracking (VOT) 은 최근 수십 년 동안 점점 더 많은 관심을 받아왔으며 현재 매우 활발한 연구가 진행되고 있는 분야이다. Visual surveillanve, Human-Computer Interaction (HCI), 그리고 Augmented Reality (AR)과 같이 다양한 분야에서 ..