
Notice
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |
Tags
- RCNN
- 3D
- 컴퓨터비전
- GaN
- rl
- PytorchZeroToAll
- cl
- YAI
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- NLP
- YAI 8기
- CS231n
- YAI 11기
- cv
- Googlenet
- Faster RCNN
- YAI 10기
- YAI 9기
- Fast RCNN
- 연세대학교 인공지능학회
- VIT
- 강화학습
- CS224N
- transformer
- 컴퓨터 비전
- nerf
- CNN
- Perception 강의
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- 자연어처리
Archives
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks 본문
컴퓨터비전 : CV/CNN based
[논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
_YAI_ 2022. 5. 8. 23:40SiamRPN++
** YAI 9기 조용기님이 비디오논문팀에서 작성한 글입니다.
1. Introduction
- Visual Object Tracking (VOT) 은 최근 수십 년 동안 점점 더 많은 관심을 받아왔으며 현재 매우 활발한 연구가 진행되고 있는 분야이다.
- Visual surveillanve, Human-Computer Interaction (HCI), 그리고 Augmented Reality (AR)과 같이 다양한 분야에서 광범위하게 응용되고 있다.
- 최근 많은 발전이 있었지만, illumination variation, occulusion, background clutter와 같은 수 많은 문제들로 인해 여전히 어려운 작업으로 인식되고 있다.
- 최근에는 Siamese network (샴 신경망) 기반의 트래커가 많은 주목을 받고 있다.
- 이 샴 트래커는 VOT 문제를 타겟 템플릿에 학습된 특성 표현과 탐색 영역 사이의 cross-correlation을 통해 일반적인 유사도 맵을 학습하는 것으로 formulate 된다.
- convolution과 cross-correlation 참고 자료: https://tensorflow.blog/2017/12/21/convolution-vs-cross-correlation/
- 이 샴 트래커는 VOT 문제를 타겟 템플릿에 학습된 특성 표현과 탐색 영역 사이의 cross-correlation을 통해 일반적인 유사도 맵을 학습하는 것으로 formulate 된다.
Convolution vs Cross-correlation
합성곱convolution 혹은 콘볼루션 신경망은 주로 시각 분야 애플리케이션에 널리 사용됩니다. 위키피디아의 합성곱 정의를 보면 “하나의 함수와 또 다른 함수를 반전 이동한 값을 곱한 다음, 구간
tensorflow.blog
-
- 트래킹의 효율성을 위해, 기존의 오프라인 학습으로 만들어진 샴 유사도 함수는 종종 실행 시에 수정이 가해졌다.
- CFNet 트래커와 DSiam 트래커는 각각 running average template, fast transformation module을 통해 트래킹 모델을 업데이트했다.
- SiamRPN 트래커는 샴 신경망 후에 Region Proposal Network (RPN)을 도입하고 트래킹 classification, regression을 동시에 수행한다.
- DaSiamRPN 트래커는 distractore-aware 모듈을 도입하고 모델의 discrimination power를 향상시켰다.
- 이러한 샴 트래커들이 정확도 및 속도 측면에서는 뛰어난 트래킹 성능을 보였지만, 여전히 SOTA 들에 비해 현저히 낮은 정확도를 보인다.
- 논문의 저자들은 이 모델들의 신경망이 AlexNet과 비슷한 아키텍처를 기반으로 만들어졌으며, ResNet과 같이 더 복잡한 아키텍쳐로 샴 트래커를 훈련시키려 했지만 성능 향상이 없다는 것을 관찰했다.
- 그리고 여기서 영감을 얻어 기존의 샴 트래커를 분석한 결과, 핵심적인 원인이 strict translation invariance가 없는 데에서 비롯됨을 찾아냈다.
- 타겟이 탐색 영역의 임의의 위치에서 나타날 수 있으므로, 타겟 템플릿에 대해 학습된 특성 표현이 spatial invariance를 유지해야 한다.
- 심층 신경망 아키텍쳐 사이에서 AlexNet의 zero-padding 변형만이 이 spatial invariance를 만족했다.
- 본 논문에서는 샴 트래커가 더 강력한 심층 신경망이 되기 위해 spatial invariance 제한을 극복하는 간단하면서도 효과적인 샘플링 전략을 소개한다.
- 이를 통해, ResNet을 backbone 신경망으로 이용하는 SiamRPN을 성공적으로 훈련시키고 상당한 성능 향상을 얻을 수 있다.
- ResNet 아키텍쳐의 이점을 활용해, cross-correlation 연산을 위한 layer-wise feature aggregation 구조를 제안했다.
- 이 구조는 트래커가 여러 수준에서 학습한 특성들로부터 유사도 맵을 예측하도록 돕는다.
- Cross-correlation에 대한 샴 신경망 구조를 분석해, 신경망의 두 branch가 불균형한 파라미터 수를 갖고 있다는 것을 발견했으며, 이를 개선하기 위해 depth-wise separable correlation 구조를 제안했다.
- 이 구조는 타겟 템플릿 branch에서 파라미터 수를 줄일 뿐만 아니라 전체 모델의 훈련 과정을 안정화한다.
- 또한 같은 범주의 객체는 같은 채널에서 높은 response를 가지고, 나머지 채널의 response는 억제되는 현상이 괸찰되었는데, 이 orthogonal property 또한 트래킹 성능을 향상 시킬 수 있다고 저자들은 주장한다.
- 논문의 주된 contribution은 다음과 같다.
- 샴 트래커에 대한 심도있는 분석을 진행했으며, 심층 신경망을 사용할 때 정확도 감소는 strict translation invariance의 파괴에서 비롯됨을 보였다.
- 단순하지만 효과적인 샘플링 전략을 제안해 spatial invariance 제한을 극복하고 ResNet 아키텍쳐 기반의 샴 트래커를 성공적으로 학습시켰다.
- Cross-correlation을 위한 Layer-wise feature aggregation 구조를 제안해 트래커가 다양한 수준에서 학습된 특성으로부터 유사도 맵을 예측하도록 했다.
- Depth-wise separable correlation 구조를 제안해 cross-correlation이 서로 다른 semantic meaning과 관련된 다중 유사도 맵을 만들게끔 했다.
- 최종적으로 35 FPS로 실행되면 트래킹 정확도에서 새로운 SOTA 모델을 개발했다.
- OTB2015, VOT2018, UAV123, LaSOT, TrackingNet 에서 최고 성능을 보여줬다.
- 또한, MobileNet backbone을 사용해 70 FPS와 경쟁력있는 트래킹 성능을 보여주는 형태도 제안했다.
2. Related Work
- Visual Tracking (시각적 트래킹)은 최근 수십 년간 새로운 벤치마크 데이터셋 구축과 방법론 개선을 통해 급격한 성장을 했다.
- 표준회된 벤치마크는 다양한 알고리즘의 비교를 위한 시험대가 되었으며, 매년 열리는 트래킹 챌린지는 트래킹 성능을 지속적으로 끌어올리고 있다.
- 이러한 발전에서 많은 유망한 트래킹 알고리즘이 제안되어 왔다.
- Bomie et al. 의 연구는 신호처리 분야의 Convolution Theorem을 시각적 트래킹 분야에 도입해 객체 템플릿 매칭 문제를 주파수 영역에서의 correlation 연산으로 변환했다.
- 이 변환을 통해 correlation 필터 기반의 트래커는 효과적인 실행 속도뿐만 아니라 적절한 특성을 사용할 경우 정확도 또한 우수했다.
- 시각적 트래킹에서 딥러닝 모델이 광범위하게 사용됨에 따라, correlation 필터와 심층 특성 표현에 기반한 트래킹 알고리즘은 트래킹 벤치마크와 챌린지에서 SOTA의 정확도를 차지했다.

- 최근에는 샴 신경망 기반의 트래커들이 균형 잡힌 정확도와 효율성으로 상당한 주목을 받고 있다.
- 이 트래커들은 시각적 트래킹을 cross-correlation 문제로 formulate하여, end-to-end 심층 신경망의 이점을 활용한다.
- 두 branch의 cross-correlation으로부터 유사도 맵을 만들어내기 위해, 두 신경망 branch를 잇는 Y자 형태의 신경망을 훈련시킨다. 여기서 하나는 객체 템플릿을 위한 것이고, 다른 하나는 탐색 영역을 위한 것이다.
- 이 두 branch는 트래킹 동안 고정되어 있거나 (오프라인), 타겟의 외형 변화에 따라 온라인으로 업데이트 될 수 있다.
- 현재 SOTA인 샴 트래커는 샴 신경망 이후에 RPN을 두어 뛰어난 트래킹 성능을 보여준다.
- 하지만, OTB 벤치마크에서는 트래킹 정확도가 ECO나 MDNet과 같은 SOTA 트래커에 비해 꽤 큰 차이로 떨어진다.
- 2012년 Alex et al. 의 AlexNet의 등장으로, 신경망 아키텍처 연구가 빠르게 증가해, VGGNet, GoogLeNet, ResNet, MobileNet과 같은 구조들이 제안되었다.
- 이러한 아키텍처는 신경망 디자인에 대한 깊은 이해뿐만 아니라, Object Detection, Image Segmentation, Human Pose Estimation과 같은 많은 컴퓨터 비전 문제들의 SOTA 성능을 발전시켰다.
- 트래킹 분야에서는 일반적으로 AlexNet 또는 VGGNet과 같은 5개 이하의 CNN 레이어를 가지고 있다.
- 이는 객체의 accurate localization에 얕은 특성들 (shallow features)가 주된 역할을 한다는 것으로 해석할 수 있다.
3. Siamese Tracking with Very Deep Networks
- 이 논문의 가장 중요한 발견은 샴 트래킹 알고리즘이 더 깊은 신경망을 사용할 경우 성능이 크게 향상될 수 있다는 것이다.
- 기존의 방식으로는 ResNet과 같은 심층 신경망으로 직접 샴 트래커를 학습시키는 것이 예상만큼의 성능 향상을 얻어내지 못했으며, 그 이유는 샴 트래커의 본질적인 제한 사항과 관련이 있다.
- 따라서, 먼저 트래킹을 위한 샴 신경망에 대해 심층적인 분석을 진행한다.
3.1. Analysis on Siamese Networks for Tracking
- 샴 신경망 기반의 트래킹 알고리즘은 시각적 트래킹을 cross correlation 문제로 formulate 하고, 샴 신경망 구조를 가진 모델로부터 트래킹 유사도 맵을 학습한다. 이 때, 샴 신경망 branch 하나는 타겟에 대한 특성 표현이며, 다른 하나는 탐색 영역이다.
- 타겟 패치는 보통 시퀀스의 첫 번째 프레임 $z$에 주어진다.
- 목표는 시멘틱 임베딩 공간 $\phi(\cdot)$ 에서 이어지는 프레임 $x$에 가장 비슷한 패치 (인스턴스)를 찾는 것이다.
- $$f(z,x)=\phi(z)*\phi(x)+b$$
- 이 때, $b$ 는 유사도 값의 오프셋을 모델링하는데 사용된다.
- 이 간단한 매칭 함수는 샴 트래커 설계에서의 두 가지 본질적인 한계점을 가지고 있다.
- 샴 트래커에서 사용된 contractign part와 feature extractor는 효율적인 훈련 및 추론을 가능케하는 strict translation invariance $f(z, x[\Delta\tau_j])=f(z,x)[\Delta\tau_j]$에 대한 본질적인 한계를 가진다.
- 여기서, $[\Delta\tau_j]$는 transition shift sub window operator 이다.
- Contracting part는 유사성 학습에 적합한 structure symmetry $f(z,x')=f(x',z)$에 본질적인 제한을 가진다.
- 샴 트래커에서 사용된 contractign part와 feature extractor는 효율적인 훈련 및 추론을 가능케하는 strict translation invariance $f(z, x[\Delta\tau_j])=f(z,x)[\Delta\tau_j]$에 대한 본질적인 한계를 가진다.
- 저자들은 분석을 통해, 샴 트래커가 심층신경망을 사용하지 못하는 이유가 이 두 가지 측면에서 기인함을 알아냈다.
- 하나는 심층 신경망에서 Padding이 strict translation invariance를 없앤다는 것이고, 다른 하나는 RPN이 분류와 회귀를 위한 비대칭적인 (asymmetirc) 특성을 요구한다는 점이다.
- 논문에서는 첫 번째 문제를 spatial aware sampling 전략으로 극복하고, 두 번째 문제는 Section 3.4에서 제안하는 방법 (depth-wise cross-correlation)에서 다루고 있다.
- Strict translation invariance는 AlexNet과 같이 padding이 없는 경우에만 존재한다.
- 기존의 샴 기반 신경망들은 이러한 제한을 충족시키기 위해 심층으로 구성할 수 없었다.
- 더 높은 성능을 위해 backbone을 ResNet 이나 MobileNet과 같은 더 깊은 신경망들로 대체하려면, 더 깊게 만들기위해 padding이 필수적이며, 이러한 padding은 strict translation invariance를 무너뜨리는 결과를 초래한다.
- 논문에서는 이러한 제한을 무시할 경우 아래 그림과 같은 spatial bias가 발생한다고 가정했다.

- 이러한 가설을 padding이 존재하는 신경망으로 시뮬레이션했다.
- Shift는 데이터 증강에서 균일 분포로 생성된 translation의 최대 범위로 정의된다.
- 실험은 다음과 같이 진행했다.
- 세 가지 실험에서 타겟들은 서로 다른 범위의 shift (0, 16, 32)를 가지고 중앙에 배치된다.
- 모델이 수렴된 이후, 테스트 데이터셋에서 생성된 heatmap을 모아서 Figure 1.의 결과로 시각화했다.
- Shift 0에서 경계 영역의 확률은 0으로 저하되며, 테스트 타겟의 외형에 상관없이 강력한 중심 편향이 학습도니다.
- 다른 두 가지 실험의 경우 shift 범위가 커질수록 모델이 trivial solution으로 붕괴되는 것을 방지함을 보여준다.
- 정량적인 결과는 집계된 heatmap이 테스트 객체의 위치 분포에 더 가깝다는 것을 보여준다.
- 이러한 결과들은 논문의 spatial aware sampling 전략이 padding이 있는 신경망이 일으키는 strict translation invariance 파괴를 효과적으로 완화함을 보여준다.
- 객체에 대한 강력한 중심 편향을 방지하기 위해, ResNet 기반의 SiamRPN을 spatial aware sampling 전략으로 훈련시키다.
- 아래 그림에서 볼 수 있듯이, VOT 2018에서 적절히 가한 shift ($\pm$ 64 픽셀)에 비해 zero shift의 성능은 0.14로 줄어들었다.

3.2. ResNet-driven Siamese Tracking
- 위 분석에 기반해, spatially aware sampling을 사용해 중심 편향의 영향을 없앨 수 있다는 것을 알았다.
- 중신 위치로의 편향을 제거하면, ResNet, MobileNet을 사용해 시각적 트래킹을 수행할 수 있다.
- 또한 신경망의 topology를 adaptive하게 구성하고 심층 신경망의 성능을 향상시킬 수 있다.
- ResNet-50을 트래킹 알고리즘으로 옮기는 방법에 대해 설명한다.
- 원래의 ResNet은 큰 stride (32 픽셀)을 가지므로 심층 샴 신경망에 적합하지 않다.
- Figure 3. 에서 보여지듯이, 논문에서는 conv4와 conv5 블록이 unit spatial stride를 가지도록 수정하여, 마지막 두 블록의 유효 stride를 16, 32 픽셀에서 8 픽셀로 줄였으며, dilated convolution을 통해 receptive field를 확장시켰다.
- 그리고 $1\times1$ convolution 레이어가 각 블록 출력에 추가되어 채널을 256으로 줄여주었다.

- 모든 레이터가 padding을 유지하므로, 템플릿 특성의 공간 크기가 15로 커져 correlation 모듈에 많은 계산 부담을 지운다. 따라서 특성 셀이 전체 타겟 영역을 캡쳐할 수 있는 중심 $7\times7$ 영역을 crop 했다.
- 기존의 SiamRPN을 따라서, cross-correlation 레이어와 full convolution 레이어를 조합해 분류 점수 ($\mathcal{S}$) 와 bounding box 회귀 ($\mathcal{B}$) 를 계산하기 위한 head 모듈을 만든다. Siamese RPN 블록은 $\mathcal{P}$ 로 표시한다.
- 또한 ResNet을 미세조정 (fine-tuning)하면 성능 향상이 이루어진다는 것을 알았다.
- ResNet extractor의 학습률을 RPN 부분에 비해 10배 적게 설정하면 특성 표현이 트래킹 작업에 좀 더 적합해진다.
- 기존의 샴 기반 접근법과는 다르게, 심층 신경망의 파라미터들은 end-to-end 방식으로 (최초로) 동시에 학습된다.
3.3. Layer-wise Aggregation
- ResNet-50과 같은 심층 신경망을 활용하면 다양한 수준의 레이어들을 결합하는 것이 가능해진다.
- 직관적으로, 시각적 트래킹은 저수준에서 고수준까지, 작은 스케일에서 큰 스케일깢, 그리고 저해상도에서 고해상도까지의 다양한 표현을 필요로한다.
- CNN에서 특성이 깊이가 있더라도 단독 레이어로는 충분하지 않으며, 이 표현들을 합성 및 결합하는 것이 인식 (recognition) 및 지역화 (localization) 추론을 향상시킨다.
- AlexNet과 같인 얕은 신경망을 사용하는 기존의 연구들에서는 여러 수준의 특성 (multi-level features)들이 다양한 표현 (representation) 을 제공하지 못한다.
- 이에 비해, ResNet의 다양한 레이어는 receptive field가 많이 변하므로 이런 측면에서 훨씬 의미있는 표현을 제공한다.
- 초기 레이어들은 주로 색상, 모양과 같은 지역화를 위한 저수준 정보에 집중하지만, 시멘틱 정보는 부족하다.
- 후기 레이어들은 모션 블러나 변형과 같은 상황에 유용한, 풍푸한 시멘틱 정보를 가지고 있다.
- 논문의 신경망에서는 다중 branch 특성들이 추출되어 타겟의 지역화를 공동으로 추론한다.
- ResNet-50은, layer-wise aggregation을 위해 마지막 세 잔차 블록 (residual block)에서 추출된 여러수준의 특성을 탐색한다.
- 이 세 가지 출력을 각각 $\mathcal{F}_3(z), \mathcal{F}_4(z), \mathcal{F}_5(z)$ 라고 표기하며, 이 conv3, conv4, conv5 각각의 출력이 Figure 3.에서 볼 수 있듯이 세 Siamese RPN 모듈로 각각 입력된다.
- 세 RPN 모듈의 출력 크기가 같은 공간 해상도를 가지므로, RPN 출력으로 직접 가중치 합을 만든다.
- 따라서 weighted-fusion layer는 모든 출력을 결합한다.
- $$\mathcal{S}_{all}=\sum_{l=3}^5 \alpha_i * \mathcal{S}_l, \quad \mathcal{B}_{all}=\sum_{l=3}^5 \alpha_i * \mathcal{B}_l$$
- 조합된 가중치는 영역이 다르므로 분류와 회귀 문제에 따라 분리된다.
- 그 후, 신경망과 함께 오프라인에서 end-to-end로 최적화된다.
- 논문의 접근은 기존 연구와는 다르게 convolution 특성을 명시적으로 결합하지 않으며, 분류와 회귀를 개별적으로 학습한다.
- Backbone 신경망의 깊이가 증가함에 따라 시멘틱 계층의 다양성이 충분히 생겨 상당한 이점을 얻을 수 있다.
3.4. Depthwise Cross Correlation

- Cross correlation 모듈은 두 branch의 정보를 임베딩하기 위한 핵심 연산이다.
- SiamFC는 Cross-Correlation (XCorr, (a)) 레이어를 이용하여 타겟 지역화를 위한 단일 채널 응답 맵을 얻어낸다.
- SiamRPN 에서는 Cross-Correlation에 거대한 컨볼루션 레이어를 추가해 (Up-XCorr, (b)) 채널을 확장함으로써, anchor와 같이 더 고수준의 정보를 임베딩한다.
- 이 무거운 up-channel 모뷸은 파라미터 분포의 심각한 불균형을 초래하여 (RPN 모듈은 20M 파라미터를 가지는데 특성 추출기 단독으로만 4M의 파라미터를 차지한다.) SiamRPN의 훈련 최적화를 어렵게 만든다.
- 본 논문에서는 Depth-wise Cross Correlation (DW-XCorr, (c)) 이라는, 정보의 효율적인 association을 만들어내는 경량 cross correlation 레이어를 제안한다.
- DW-XCorr는 SiamRPN의 UP-XCorr에 비해 동일한 성능을 유지하면서 파라미터 개수를 10배 적게 가진다.
- 이를 위해, conv-bn 블록을 사용하여 각 잔차 블록의 특성을 트래킹 작업에 맞게 조정한다.
- SiamFC와 다르게, 여기에서는 bounding box 예측과 anchor 기반의 분류 보두 비대칭이다.
- 차이를 인코딩하기 위해, 템플릿 branch와 탐색 branch는 두 개의 공유되지 않는 컨볼루션 레이어를 통과시키다.
- 그런 다음 동일한 수의 채널을 가진 두 개의 특성 맵이 채널별로 correlation 연산을 수행한다.
- 그 후, 또 다른 conv-bn-relu 블록을 추가하여 다른 채널 출력들을 융합한다.
- Cross-correlation을 depth-wise correlation으로 대체하면, 계산 비용과 메모리 사용을 상당히 줄일 수 있다.
- 이러한 방식을 통해 템플릿과 탐색 branch에서의 파라미터 수가 더 균형적이며, 학습과정이 더 안정적이게 된다.
- 아래의 Figure 5.에서 흥미로운 현상이 발견되었는데, 동일 범주의 객체가 동일 채널에서 높은 반응을 보이는 반면, 나머지 채널의 반응은 억제되는 모습을 보여주었다.
- 이러한 속성은 depth-wise cross correlation으로 생성된 channel-wise 특성들이 서로 거의 orthogonal 하며 각 채널들이 일부 시멘틱 정보를 표현하기 때문으로 이해할 수 있다.
- 한편, up-channel cross correlation에 대해서도 heatmap을 분석했지만, 반응 맵을 해석하기 어려웠다.
4. Experimental Results
4.1. Training Dataset and Evaluation
Training
- 아키텍처의 backbone 신경망은 이미지 레이블링을 위해 ImageNet에 사전훈련되었으며, 이는 다른 작업을 위한 좋은 초기화 작업으로 입증되어 있다.
- 신경망을 COCO, ImageNet DET, ImageNet VID, 그리고 Youtube-BoundingBoxes Dataset에 대해 학습시켰으며, 시각적 트래킹에 있어 일반적인 객체 사이의 유사도를 측정하는 방법에 대한 일반적 개념을 학습시켰다.
- 훈련과 테스트에서, 템플릿 패치에 127 픽셀, 그리고 탐색 영역에 255 픽셀의 단일 스케일 이미지를 사용했다.
Evaluation
- OTB2015, VOT2018, UAV123 에서 단기 단일 객체 트래킹을 측정했으며, VOT2018-LT로 장기 설정을 평가했다.
- 장기 트래킹은 객체가 field of view를 벗어나거나 완전히 가려져서 단기 트래킹보다 어려운 작업이다.
- 또한 단일 객체 트래킹에 대한 가장 큰 벤치마크인 LaSOT와 TrackingNet에 대해서도 논문 방법의 일반화 성능을 분석했다.
4.2. Implementation Details
Network Architecture
- DaSiamRPN의 훈련 및 추론 설정을 따랐다.
- 두 개의 sibling 컨볼루션 레이어를 stride를 줄인 ResNet-50에 연결해 5 anchor로 proposal의 분류와 bounding box 회귀를 수행한다.
- 무작위로 초기화된 3개의 $1\times1$ 컨볼루션 레이터가 conv3, conv4, conv5에 부착되어 특성 차원을 256으로 줄였다.
Optimization
- optimizer: 미니배치당 128쌍으로 8개의 GPU를 통해 synchronized SGD 사용 (수렴에 12시가 소요)
- learning rate: 초반 5 epoch 0.001 (RPN branch), 후반 15 epoch 0.005에서 0.0005로 exponential decay (전체 네트워크를 end-to-end로)
- training loss: 분류 손실과 회귀 smooth $L_1$ loss의 합
4.3. Ablation Experiments
Backbone Architecture
- 특성 추출기 선택은 그 파라미터 수와 레이어 타입이 트래커의 메모리, 속도, 성능에 직접적인 영향을 미치므로 중요하다.

- Figure 6. 에서는 AlexNet, ResNet-18, ResNet-34, ResNet-50, 그리고 MobileNet-v2 backbone에서의 성능을 보여준다.
- ImageNet의 top-1 정확도와 OTB2015의 success plot의 AUC를 보여준다.
- 논문의 SiamRPN++ 가 더 깊은 CNN에서 이득을 얻을 수 있음을 관찰할 수 있었다.
- Table 1.에서는 또한 AlexNet을 ResNet-50으로 대체했을 때, VOT2018 에서 성능이 크게 향상되었음을 보여준다.
- 또한 논문의 실험을 통해 backbone 부분에서의 미세조정이 트래킹 성능에 있어 중요하다는 것을 알 수 있었다.

Layer-wise Feature Aggregation
- Layer-wise feature aggregation의 영향을 조사하기 위해, ResNet-50 기반 단일 RPN의 세 가지 변형에 대해 실험을 진행했다.
- 경험적으로, conv4 단독으로 EAO에서 0.374로 경쟁력있는 성능을 달성한 반면, 더 깊거나 얕은 레이어는 성능이 4% 정도 하락하는 결과를 보였다.
- 두 branch의 결합에서도, conv4와 conv5 조합에서는 성능 향상이 있었지만 다른 두 가지 조합에서는 관찰되지 않았다.
- 하지만 논문의 모델의 주요 취약점인 강건성은 10% 증가했다.
- 세 레이어 모두 결합할 경우, VOT와 OTB에서 각각 3.1%, 1.3%로 정확도와 강건성 모두 향상되었다.
- 전체적으로, layer-wise feature aggregation은 VOT2018에서 단일 레이어에 비해 4.0% 더 높은, 0.414 EAO를 보여주었다.
Depthwise Correlation
- 원래의 up-channel cross correlation 레이어와 제안된 depth-wise cross correlation 레이어를 비교했다.
- Table 1. 에서 depth-wise correlation은 VOT2018에서 2.3%, OTB2015에서 0.8% 향상되어 그 중요성을 보여주고 있다.
- 이는 두 branch의 균형잡힌 파라미터 분포가 학습 과정을 더 안정적으로 만들고 잘 수렴하도록 만들기 때문이다.
4.4. Comparison with the state-of-the-art
OTB-2015 Dataset
- 표준 OTB 벤치마크는 강건성에 대한 공정한 시험을 제공한다.
- 샴 트래커는 어떠한 온라인 업데이트 없이 트래킹을 one-shot 탐지 작업으로 formulate하므로, 이 재설정 없는 벤치마크에서 성능이 저하되었다.
- Figure 7에서 볼 수 있듯이, SiamRPN++ 트래커가 overlap success에서 최고 성능을 보여주었으며, 이는 샴 트래커가 OTB2015에서 처음으로 SOTA와 비슷한 수준의 성능을 보여준 것이다.

VOT2018 Dataset

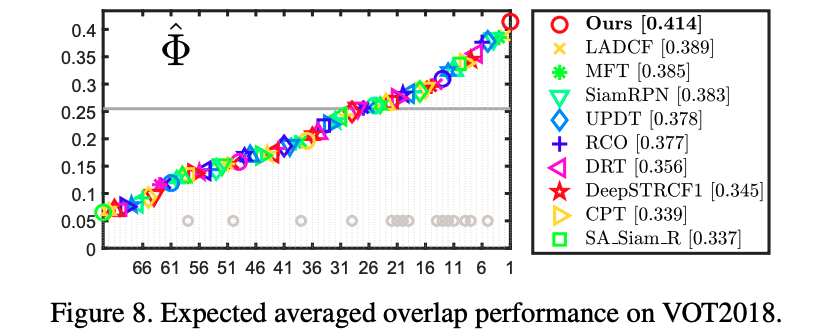
- 이 실험에서는 VOT2018에서 10가지 SOTA 트래커들과 SiamRPN++ 트래커를 비교하고 있다.
- VOT2018은 온라인 model-free 단일 객체 트래커를 측정하는 가장 최근의 데이터셋이며, 다양한 도전적 요소를 포함한 60개의 공개 시퀀스를 포함한다.
- VOT2018의 평가 프로토콜에 따라, 서로 다른 트래커들을 비교하기 위해 Expected Average Overlap (EAO), Accuracy (A), Robustness (R), no-reset-baset Average Overlap (AO)를 지표로 채택했다.
- Table 2. 에서 SimpleRPN++는 EAO, A,AO 에서 최상의 성능을 보였으며, VOT2018에서 기존의 모든 트래커의 성능을 능가했다.
- Baseline인 DaSiamRPN에 대해 논문의 방법이 강건성에서 10.3%의 상당한 성능 향상을 보여줬다. 강건성은 correlation 필터 기법들에 비해 샴 신경망 기반 트래커들의 일반적인 취약점이었다.
- 하지만 템플릿에 대한 적응 부족으로, 여전히 온라인 SOTA correlation 필터 기법들에 비행 강건성 격차는 존재한다.
- 트래커 평가에 One Pass Evaluation (OPE) 또한 사용되었으며, AO 값을 기록해 성능 입증에 사용했다.
- Table 2.의 마지막 행에서, 논문에서 제안한 방법이 DLSTpp와 비슷한 성능을 보여주었고, DaSiamRPN 방법에 비해서는 10.0% 향상된 성능을 보여줬다.
Accuracy vs. Speed
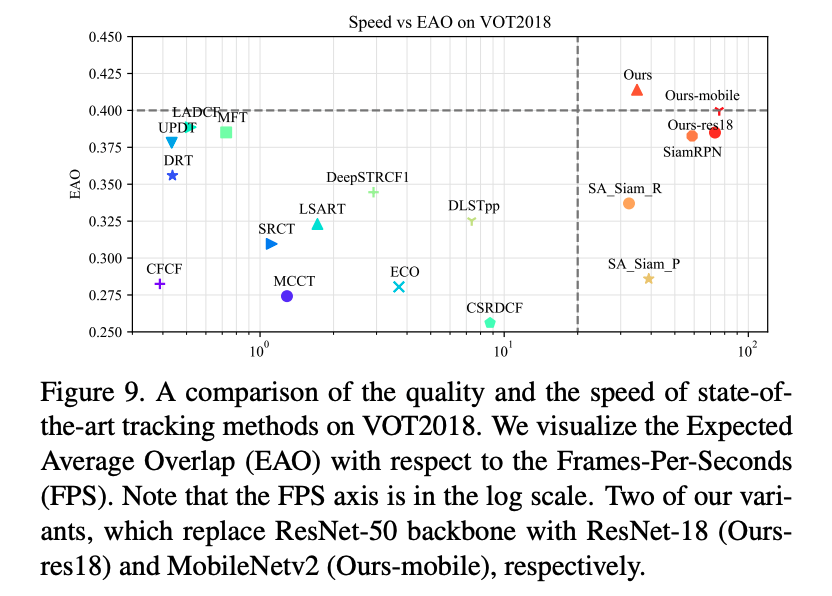
- Figure 9.은 VOT2018 에서의 FPS와 EAO 성능을 시각화하고 있다.
- NVIDIA Tital Xp GPU 에서 측정되었으며, 다른 결과는 VOT2018의 공식 결과를 사용했다.
- SiamRPN++가 최고의 성능과 실행 속도를 보여준다.
- 또한 두 가지 변형 모델 (MobileNetv2, ResNet-18) 의 성능이 SiamRPN++와 비슷하며, 70FPS 이상의 빠른 속도를 보여주어 매우 경쟁력있는 결과를 보여주었다는 점을 주목할 필요가 있다.
VOT2018 Long-term Dataset
- 최근의 VOT2018 챌린지에서는 장기 실험이 새롭게 도입됐다.
- 이 실험으 35개의 긴 시퀀스로 이루어져 있으며, 타겟이 오랫동안 field of view를 벗어나거나 완전히 가려질 수 있다.
- 성능 측정은 Precision, Recall, combined F-score로 수행됐다.
- Figure 10. 에서 볼 수 있듯이, SiamRPN++ 가 F-score에서 최고 점수를 얻었다.
- 또한 VOT2018-LT의 우승 모델인 MBMD에 비해 8배 빠른 21 FPS로 실행되었다.

UAV123 Dataset

- UAV123 데이터셋은 평균 시퀀스 길이가 915 프레임인 123개 시퀀스로 이루어져 있다.
- Figure 11. 에서 SiamRPN++가 기존의 DaSiamRPN과 ECO를 큰 폭으로 능가하는 것을 확인할 수 있다.
LaSOT Datatset

- 제안된 프레임워크를 더 크고 도전적인 데이터셋에서 검증하기 위해 LaSOT dataset에서 실험했다.
- LaSOT 데이터셋은 대규모의 고품질 고밀도 annotation을 전체 1400, 테스트 280개의 비디오에 대해 제공한다.
- Figure 12.에서 볼 수 있듯이, 어떠한 추가사항 없이 SiamRPN++ 모델이 SOTA 성능을 달성했다.
TrackingNet Dataset

- SiamRPN++ 를 511개 비디오의 테스트셋에 대해 평가했다.
- 평가에 AUC, Precision, Normalized Precition을 사용했다.
5. Conclusions
- SiamRPN++ 라고 하는 visual tracking을 위한 deep Siamese network를 end-to-end로 학습할 수 있는 통합 framework를 제안했다.
- 그리고 이 과정에 대한 이론적 실험적 분석을 진행했다.
- 제안한 네트워크는 multi-layer aggregation module과 depth-wise correlation layer로 구성되어 있다.
- 제안한 방법은 여러 데이터셋에서 SOTA의 성능이 검증됐다.
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation (0) | 2022.09.26 |
|---|---|
| [논문 리뷰] Going Deeper with Convolutions (0) | 2022.08.13 |
| [논문 리뷰] Mask R-CNN (0) | 2022.03.20 |
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] FPN : Feature Pyramid Network (0) | 2022.03.12 |
'컴퓨터비전 : CV/CNN based' Related Articles
more




Comments