
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- YAI
- YAI 11기
- Googlenet
- 강화학습
- CS231n
- 3D
- nerf
- RCNN
- 자연어처리
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- GaN
- YAI 10기
- 연세대학교 인공지능학회
- YAI 8기
- CNN
- CS224N
- Fast RCNN
- VIT
- 컴퓨터 비전
- rl
- NLP
- Faster RCNN
- 컴퓨터비전
- transformer
- PytorchZeroToAll
- YAI 9기
- cv
- Perception 강의
- cl
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] StarGAN 본문
StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation
- YAI 8기 안용준님이 GAN팀에서 리뷰하신 논문입니다.
0. Abstract
- 현재까지의 연구는 2개 도메인에서의 image2image translation이었다.
- 2개 이상의 도메인에서 scalability, robustness가 제한적이다. 왜냐하면 모든 도메인 pair마다 모델이 설계되어야 하기 때문이다.
- 이를 개선하고자, 모든 도메인 간 변환을 한 모델로 가능하게 하는 starGAN을 고안하였다.
- 이러한 통합 모델은 여러 개의 데이터셋들을 동시에 학습시킬 수 있다.
- 기존의 모델들보다 생성 이미지 퀄리티가 좋을 뿐만 아니라, 원하는 도메인으로 유연하게 translating하는 데 좋은 성능을 가지고 있다.
- 이 모델은 얼굴 특성 transfer에 효과적이라는 것을 알아내었다.
1. Introduction
- Image2image translation task는 GAN으로 많은 진전을 이루어내었다(CycleGAN, pix2pix).
- 이러한 모델들은 두 개의 도메인이 주어졌을 때에 하나의 도메인에서 다른 하나의 도메인으로 translate할 수 있게 한다.
- Attribute: 이미지에 내재된 의미 있는 feature(머리 색깔, 성별, 나이 등)
- Attrubute value: 해당 attribute의 값(머리 색깔이라면 검정, 금발, 갈색 등)
- Domain: 같은 attribute value를 가지는 이미지들의 모음(여성 사진 모음이 하나의 도메인이라면, 남성 사진 모음이 또다른 도메인일 수 있다)
- 여러 이미지 데이터셋들은 많은 숫자의 labeled attributes가 있다. 예를 들어 CelebA는 40개의 라벨(머리 색깔, 성별, 나이 등), RaFD는 8개의 라벨(행복, 화남, 슬픔 등)이다.
- 이러한 세팅은 multi-domain image-to-image translation 태스크를 가능하게 해준다. 여러 개의 도메인에서 attribute를 바탕으로 이미지를 translate하는 태스크이다.

위 그림은 CelebA데이터가 한 인풋에 대해 4가지 attribute로 변환이 가능하다는 것을 보여준다. 그에 더하여 CelebA와 RaFD 데이터셋을 jointly training시켜서 데이터셋 간에 image translation도 가능하게 한다. 오른쪽 그림은 CelebA의 이미지를 RaFD의 attribute 기반으로 변환한 사진이다.
- 하지만 현재까지 연구된 기법으로 multi-domain task를 수행하기 위해서는 k개의 도메인에 대하여 k(k-1)의 generator가 필요하다(Figure 2 참조).
- 이러한 기법에서는 학습되어야 할 global feature가 많음에도 불구하고, 각 G가 두 개의 도메인의 feature만 학습하기 때문에 fully utillized되지 못한다.
4개의 도메인에 12개의 G가 필요하다는 것을 보여주는 그림이다. 이 각각의 G는 두 도메인에 대해서만 학습하기 때문에, global한 feature를 학습하기 어렵다. 오른쪽 그림은 StarGAN의 아키텍쳐로, 모든 도메인을 하나의 G가 학습하고 각각의 도메인으로 translate도 가능하다.
- 도메인을 정해놓고 translation을 하는 것이 아니라, 도메인 정보 또한 input으로 사용하여 어떤 도메인의 image이든 input으로 사용할 수 있게 한다.
- 또한 target 도메인도 random generate하여, input에 어떠한 도메인으로든 유연하게 translation할 수 있다.
- 또한 mask vector를 고안함으로써 여러 데이터셋을 handling할 수 있는데, 이는 모르는 라벨은 가려버려서 무시하고, 연산하고자 하는 데이터셋의 라벨에 focus하는 방식이다.
- 이러한 mask vector로 인해 CelebA에서 RaFD로 변환이 가능한 것이라고 설명한다.
<main contribution>
- Multiple domain에 대한 translation 태스크를 단 하나의 G와 D를 사용하여 효과적으로 모든 도메인에 학습시킴
- Multiple datasets 사이의 multi-domain image-translation을 mask vector를 고안해서 가능하게 하였다
- Facial attribute transfer, facial expression synthesis 태스크에서 기존의 모델에 비해 더 퀄리티 높은 결과를 만들어내었다.
2. Star Generative Adversarial Networks
일단 하나의 데이터셋에서 multi-domain image2imae translation을 하는 starGAN의 framework을 소개하고, 그 이후 StarGAN이 어떻게 multiple dataset을 다룰 수 있는지 알아본다
2.1 Multi-Domain Image-to-Image Translation
- starGAN의 목적은 어떠한 이미지가 들어갈 때에 모든 도메인으로의 변환이 가능하게 만드는 것이므로, input image에 추가적으로 target domain label이 condition으로 들어간다. (G(x, c) -> y 와 같은 형식)
- 이러한 c를 무작위로 생성함으로써, G는 input image를 유연하게 변환시킬 수 있다.
- 여기에 추가적으로 보조 분류기(auxiliary classifier)를 소개하는데, 이는 하나의 D가 multiple domain을 컨트롤할 수 있게 해준다.
- 이 보조 분류기는 input image의 domain이 어디인지 분류하여, real/fake output에 추가하여 나오는 값이다.(x -> (real/fake, domain label))
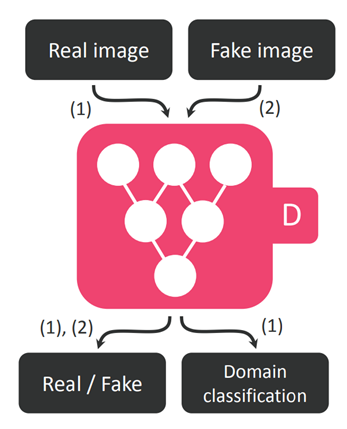
그림에서 확인할 수 있듯이 image input에 대해 binary classification, domain classification을 동시에 하는 모습이다.
<Loss>
이 아키텍쳐에서는 loss를 크게 3가지로 나눌 수 있다. Adversarial, Domain Classification, Reconstruction이다.
1. Adversarial loss
Ladv=Ex[logDsrc(x)]+Ex,c[log(1−Dsrc(G(x,c)))],
Dsrc는 real/fake를 가리는 부분, 나중에 나오는 Dcls는 domain을 classify하는 부분
- 흔히 봤던 GAN의 adversarial loss와 같은 모습이다.
2. Domain Classificaiton loss
Lrcls=Ex,c′[−logDcls(c′|x)],
Lfcls=Ex,c[−logDcls(c|G(x,c))],
- StarGAN의 목적은 input image x와 target domain label c를 가지고 output image y를 만들어내는 것인데, 이 y가 c로 분류가 되어야 한다.
- 따라서 보조 분류기 Dcls를 두는데, 이 Dcls는 G를 위한 loss와 D를 위한 loss가 따로 있다.
- 일단 step 1으로 real image만으로 D를 학습시키는데, 이 때 D를 위한 loss를 사용하고(위의 식), step 2에서 실제 adv loss와 함께 G를 학습시킬 때에 G를 위한 loss가 사용된다(아래 식).
3. Reconstruction loss
Lrec=Ex,c,c′[||x−G(G(x,c),c′)||1],
- G는 input image를 target domain c로 변환하도록 학습되는데, adv loss와 cls loss만 가지고는 target domain으로의 변환을 위한 ‘최소한의 변화’가 보장되지 않는다. -> 변환 도중에 다른 특성도 변화할 가능성이 있다는 뜻. 노인으로 변환하고 싶은데 노인으로 변환된과 동시에 머리색깔도 바뀌는 등..
- 따라서 여기에 cycle consistency loss를 추가한다.(CycleGAN에서 본거) 즉 target domain c로 변환 후에, 그 변환한 이미지를 다시 source domain c’으로 변환하여 L1 loss를 사용한다.
Full Objective
LD=−Ladv+λclsLrcls,
LG=Ladv+λclsLfcls+λrecLrec,
- 최종 loss는 위와 같다. 람다값들은 어떤 loss를 더욱 중요하게 생각할지에 대한 하이퍼파라미터이다. Λcls에는 1, Λrec에는 10의 값을 주었다고 한다.
StarGAN
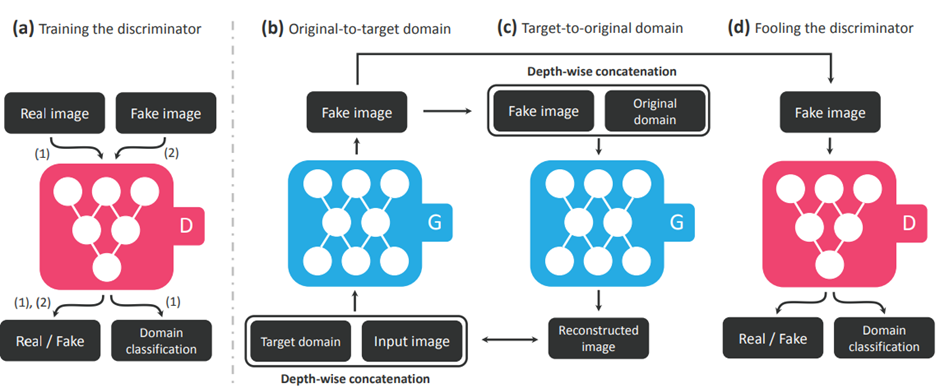
StarGAN의 학습 개요이다. 하나하나 살펴보자.
(a) D는 Real image와 Fake image를 분류하는 기존의 GAN에서의 D와 같은 학습을 하고, 이에 더하여 Real image에 대해서 domain을 classify하는 학습을 동시에 진행한다.(D를 위한 classification loss)
(b) G에 input image와 target domain을 넣어서 fake image를 생성한다.
(c) Target domain으로 변환된 fake image를 다시 source domain과 함께 G에 넣어서 reconstruct image를 생성한다. (Reconstruction loss)
(d) Fake image가 D에 들어가서 real/fake를 판별하고, domain도 판별한다.(G를 위한 classification loss, adv loss)
2.2 Training with Multiple Datasets
- Multiple dataset을 다루기 위해 고려해야할 이슈는, 각 데이터셋의 라벨 정보가 부분적으로만 알고있다는 사실이다. 예를 들어, CelebA에는 머리색깔, 나이, 성별 등의 라벨 정보가 있지만 RaFD에 있는 행복, 화남 등의 라벨 정보가 없고, 반대도 마찬가지이다.
- 훈련시킬 때에 input으로 c vector가 complete해야한다는 제약이 있는데, 이는 reconstruct할 때에 벡터값이 다르면 학습이 불가능하기 때문이다.
- Mask Vector: n차원의 one-hot vector m과, 각 데이터셋의 라벨 정보가 들어있는 c1, c2, …, cn을 concatenate하여 하나의 벡터로 만든 것. [c1,…,cn,m]
- 하나의 데이터셋이 학습될 때에 나머지 n-1개의 모르는 라벨은 0으로 할당된다
- 이러한 c vector의 모양 이외에 single dataset을 다루는 G의 아키텍처에서 바뀐 것은 없지만, D에서는 보조 분류기에게 모든 데이터셋의 라벨에 대한 확률분포를 출력하도록 수정하였다.
- 이 분류기도 주어진 데이터셋에 대한 라벨에만 집중하여 학습한다. 예를 들어, CelebA 데이터셋을 학습할 때에는 성별, 나이, 머리색 등을 분류하도록 학습하지만, 화남, 슬픔 등의 타 데이터셋 라벨은 분류하지 않는다.
- 이러한 mask vector c 틸다를 사용함으로써, G는 모르는 라벨을 무시하는 법을 학습하고, 주어진 라벨에만 집중한다.
3. Implementation
- Adv loss에 WGAN(Wasserstein GAN)의 objective function을 사용하였다.(참고: https://ahjeong.tistory.com/7 )
Ladv=Ex[Dsrc(x)]−Ex,c[Dsrc(G(x,c))]−λgpEˆx[(||▽ˆxDsrc(ˆx)||2−1)2],
- CycleGAN의 network를 적용하였다(down sampling, up sampling). Appendix(7.2)에 자세하게 나와있음
4. Experiment

다른 baseline model들에 비해 의도한 도메인 이외에 특성을 건드리지 않고 있고, 두 특성을 한번에 변환해도 좋은 성능을 보여준다.

다른 모델들에 비해 월등한 성능을 보여준다. 이 결과는 Facial dataset에 대한 다른 모델들 대비 고퀄리티임을 보여준다.

위의 행은 하나의 데이터셋만으로 돌아가도록 구현한 것이고, 아래 행은 여러 데이터셋으로 돌아가도록 구현한 것이다(mask vector 사용유무인듯). 아래 행이 더 좋은 성능을 보인다.
CelebA image -> RaFD 도메인으로 변환

Mask vector를 잘못 구현했을 때에 나타나는 결과이다.
'컴퓨터비전 : CV > GAN' 카테고리의 다른 글
| [논문 리뷰] StyleGAN-NADA: CLIP-Guided Domain Adaptation of Image Generators (1) | 2023.03.04 |
|---|---|
| [논문 리뷰] StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery (0) | 2023.03.04 |
| [논문 리뷰] Diffusion Models Beat GANs on Image Synthesis (0) | 2023.01.14 |
| [논문 리뷰] Unsupervised Pixel-level Domain Adaptation with GAN (0) | 2022.04.11 |

