
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- CNN
- VIT
- 강화학습
- Googlenet
- cl
- GaN
- CS224N
- RCNN
- CS231n
- 컴퓨터비전
- YAI 10기
- 3D
- NLP
- YAI 9기
- Perception 강의
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- 자연어처리
- transformer
- cv
- Faster RCNN
- YAI 11기
- PytorchZeroToAll
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- rl
- Fast RCNN
- nerf
- 연세대학교 인공지능학회
- YAI 8기
- 컴퓨터 비전
- YAI
- Today
- Total
연세대 인공지능학회 YAI
[Deep Learning for Computer Vision] Training Neural Network / Recurrent Network / Attention 본문
[Deep Learning for Computer Vision] Training Neural Network / Recurrent Network / Attention
_YAI_ 2022. 8. 27. 15:51** YAI 10기 김성준님이 기초심화팀에서 작성한 글입니다.
1. Lecture 11: Training Neural Networks II
- Learning Rate Schedules
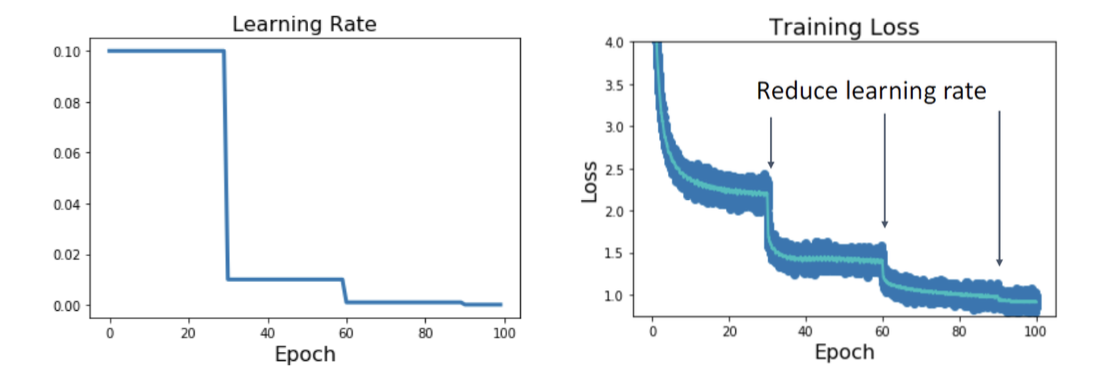
Learning rate 를 너무 큰 값으로 설정하면 밖으로 튀어나가 버리고(explosion), 너무 작은 값으로 설정하면 학습 속도가 매우 느려지므로 적절한 값으로 설정하는 것이 중요하다. 하지만 이게 쉽지는 않은데... 이를 해결하기 위해 learning rate 를 특정 epoch 마다 규칙 적으로 감소시키는 방법이 있다. 위의 사진으로부터 learning rate 가 감소하는 지점마다 loss 도 계단 모양으로 감소함을 확인할 수 있다.
하지만 이 방식은 learning rate 를 얼마마다 감소시켜야 하는지 등을 결정해야 하는 번거 로움이 있는데, 이 방법 대신 learning rate 를 epoch 가 증가할수록 코사인 함수처럼 감 소하도록 설정할 수도 있다.
그런데... 보통은 그냥 learning rate 를 상수로 설정해두는 것으로도 충분하다. 모델의 성 능에 큰 영향을 주지는 않기 때문이다. 성능을 미세하게나마 더 끌어올리고 싶다면 고려 해볼 만한 방법.
- Early Stopping
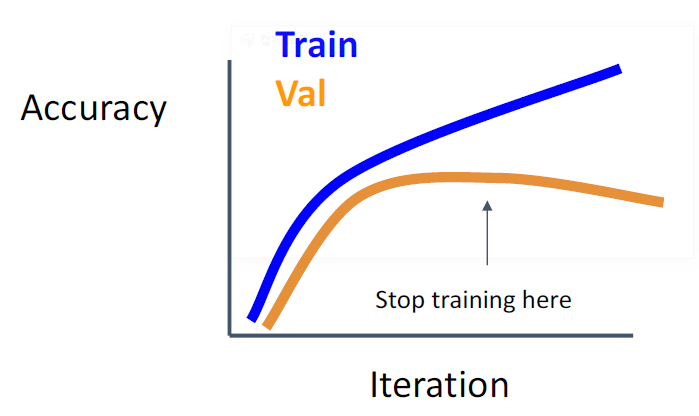
- Choosing Hyperparameters
학습을 계속 하면서, 검증 데이터에 대한 정확 도가 어느 순간부터 떨어질 수도 있다. 그렇다 면 거기서 학습을 멈추는 것이 좋은 방법이다.
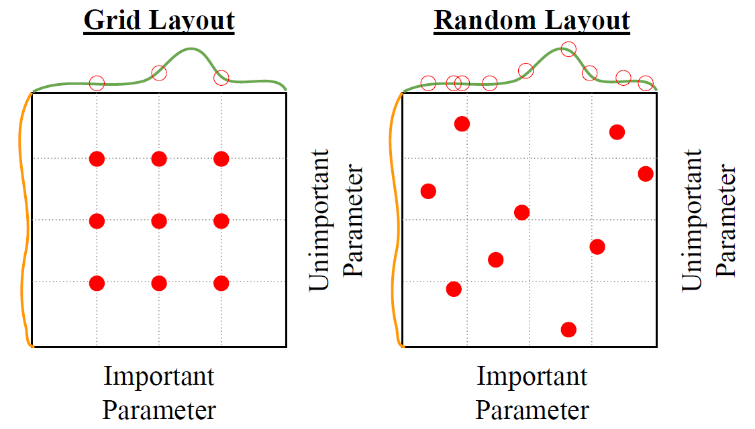
왼쪽의 그림은 두 가지 하이퍼파 라미터의 값을 고르는 방법 두 가 지를 보여준다. 세로축에 해당하는 파라미터는 모델의 성능에 미치는 영향이 비교적 작다. Grid 보다는 random layout 을 택하는 편이 성 능이 최고점에 가깝게 하는 파라 미터 값을 찾기 더 쉬울 것이다.
하이퍼파라미터의 값을 정할 때는 다음과 같이 하는 것이 좋다. 우선 training set 에서 데 이터를 조금 가져오고, 그 작은 dataset 에 대해 학습시킨다. 이 과정에서 learning rate 를 여러가지로 바꿔보면서 loss 가 줄어들도록 하는 값을 찾는 것이다.
- Model Ensembles
그냥 단순하다. 동시에 여러 모델을 학습시킨 뒤, 나중에 테스트할 때 각 모델들의 출력 의 평균으로 정답을 가려내는 것이다. 이것도 마찬가지로 미세하게나마 정확도를 올리고 싶다면 해볼 만하다.
- Transfer Learning
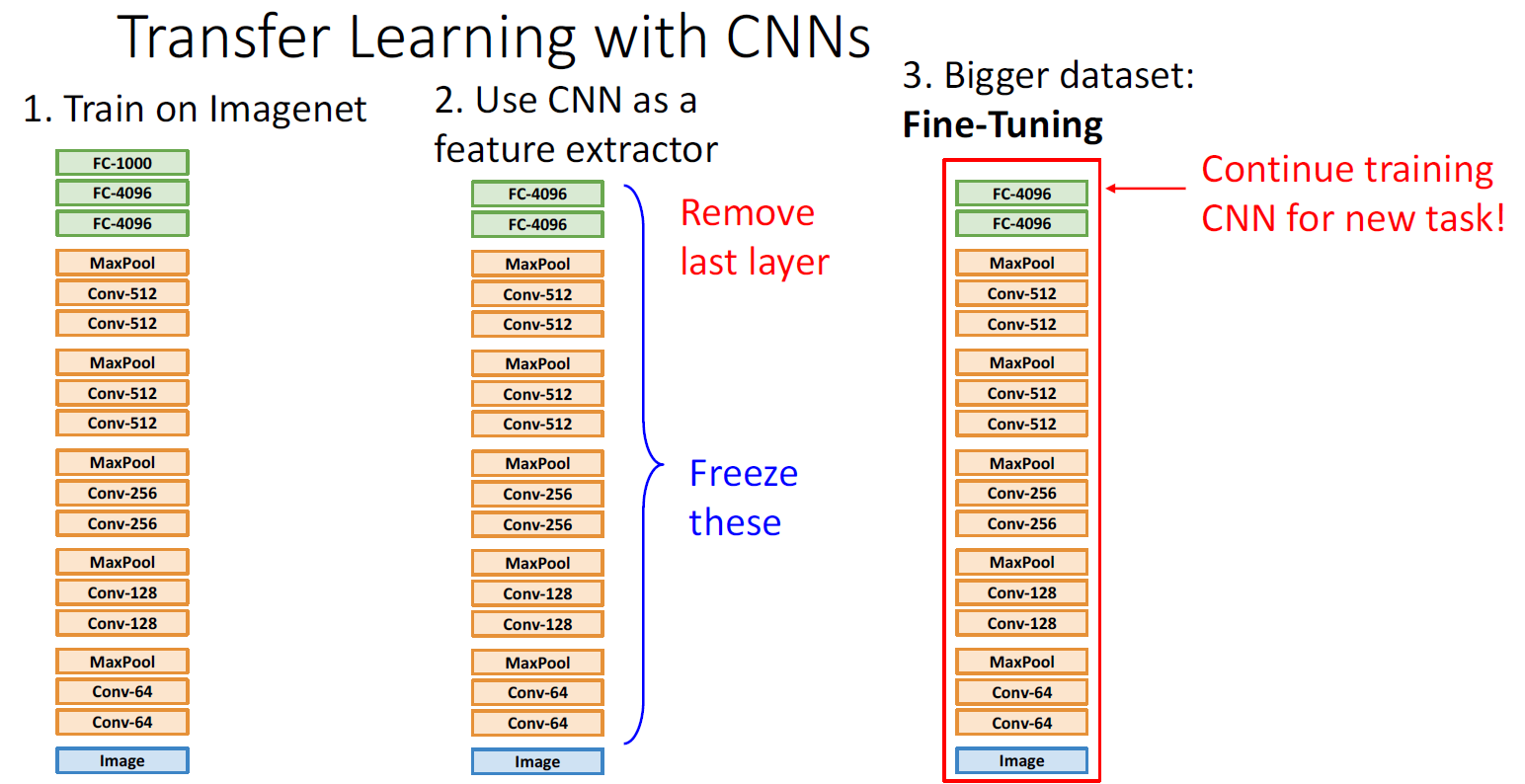
쉽게 말하면, 이미 학습된 모델을 갖다 쓰는거다. 이렇게 하면 학습 데이터의 양이 적어 도 잘 학습하는게 가능해진다. 위의 사진은 AlexNet 에서 맨 끝의 classifier 부분만 떼어 낸 것을 활용한 것이다. 이렇게 하면 입력 이미지로부터 4096 종류의 feature 정보를 뽑 아내는게 가능하다. 이걸 이용하면 사용 가능한 학습 데이터가 적어도 feature 데이터로 부터 group 을 결정하는 부분만 학습하면 되므로 학습이 가능해진다. Transfer learning 은 많이 사용되고 있는 학습법이다.
2. Lecture 12: Recurrent Networks
- Examples of Recurrent Neural Networks (RNN)
- One to one: Image classification (image --> label)
- One to many: Image captioning (image --> sequence)
- Many to one: Video classification (sequence of image --> label)
- Many to many: Language translation (English sequence --> French sequence)
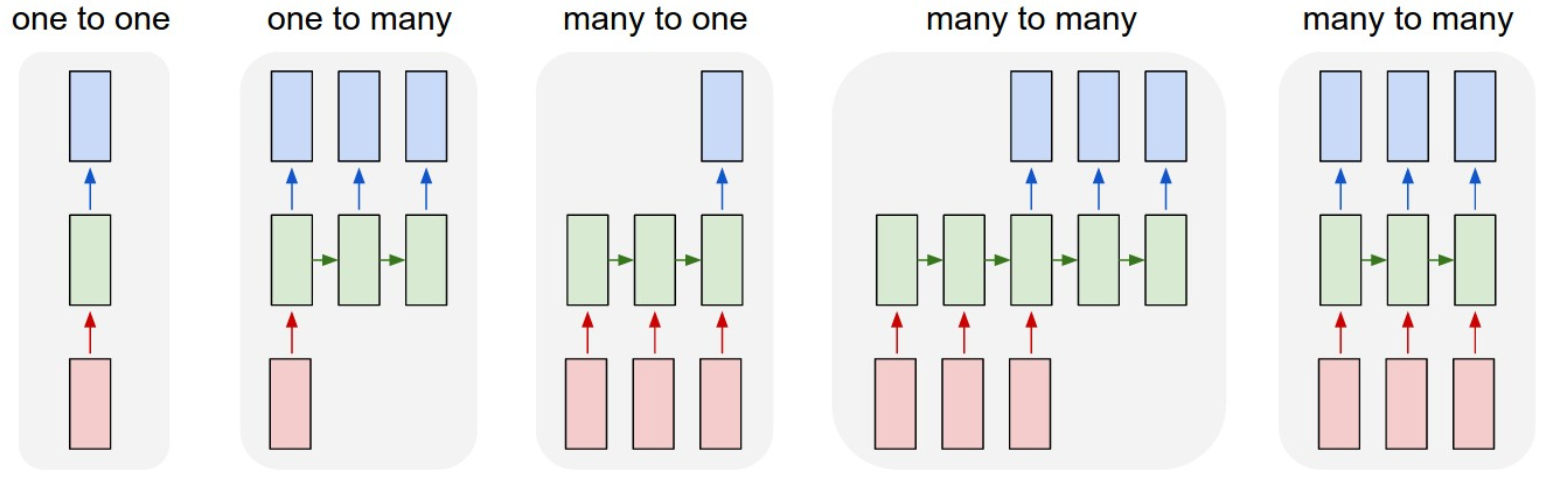
- RNN의 특징
- Hidden state 의 초기 값은 보통 0으로 설정한다. 아니면 대신 학습을 통해 값을 결 정할 수도 있다.
- Hidden state 의 사이클이 계속 돌아가는 동안에는, 같은 W를 계속 재사용한다.
- seq2seq 모델은 (many to one) + (one to many) 의 방식으로 설계된다. 여기서 이 둘은 서로 다른 W를 갖고 있다.
- Embedding Layer
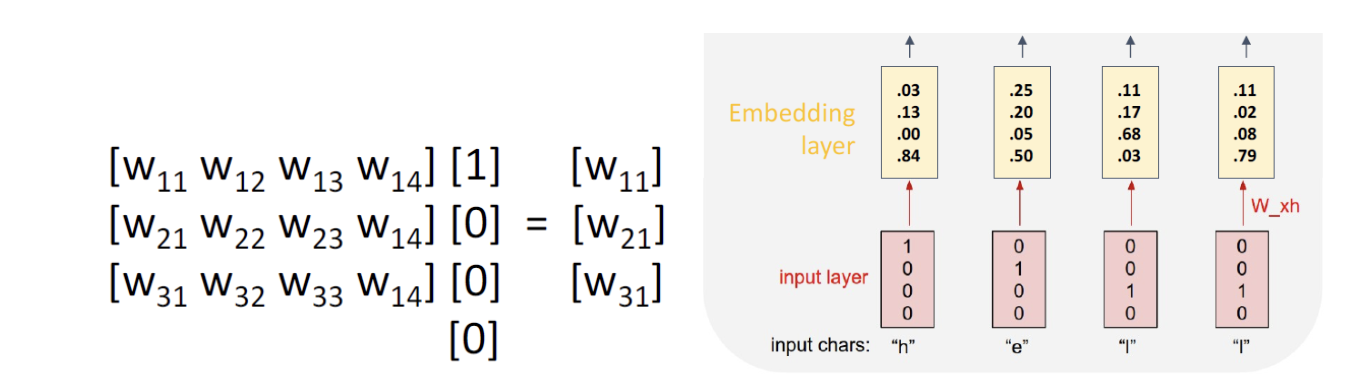
Input 으로 입력되는 알파벳은 one-hot 벡터의 형태로 되어 있다. 왼쪽의 사진에서, one- hot 벡터가 [1 0 0 0] 이라면, 연산 결과는 단순히 W 행렬에서 첫 번째 열을 추출한 것과 똑같다. 이러한 성질을 이용해 각 알파벳의 one-hot 벡터를 어떤 다른 벡터로 바꾸어 주 는 embedding matrix 를 생각할 수 있다.
- Truncated Backpropagation Through Time
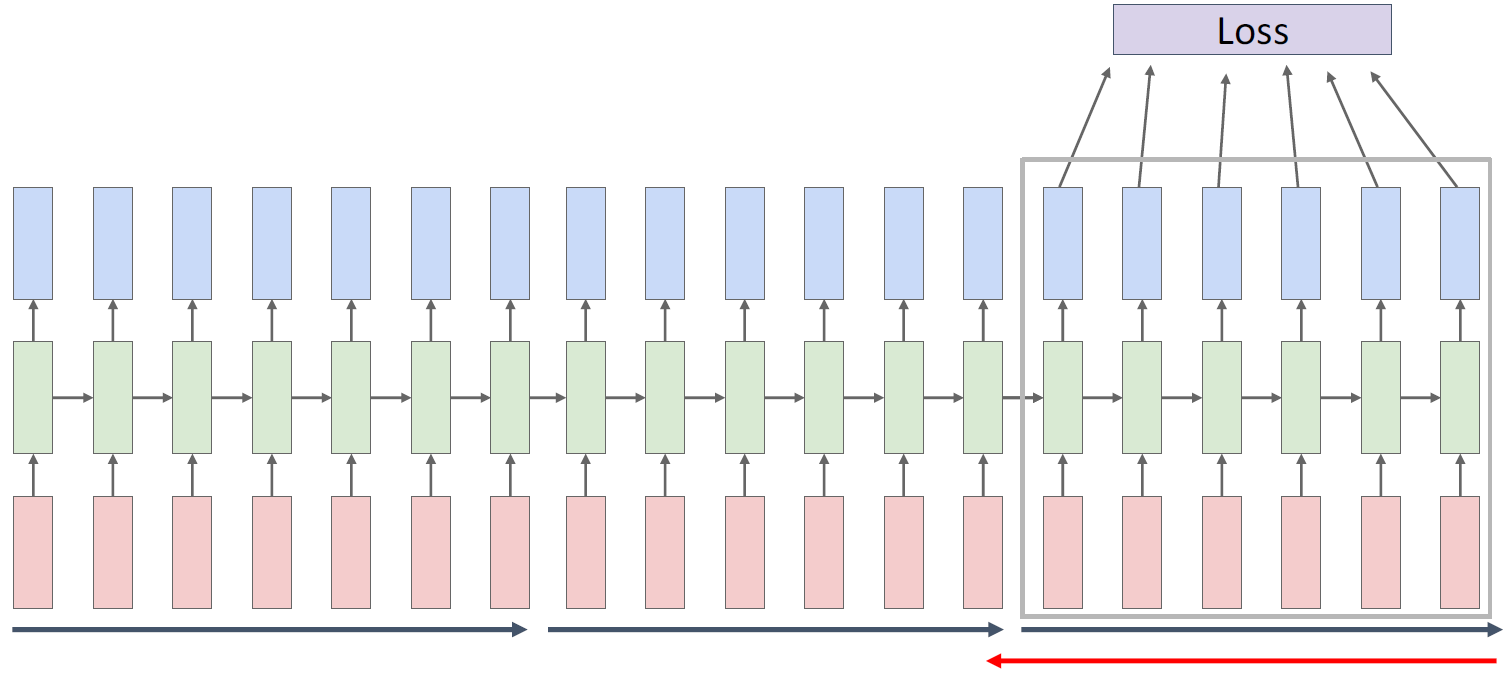
모델을 학습하려면 모든 시간대에서의 loss 를 구해야 하는데, 이 과정은 매우 많은 양의 메모리를 요구한다. 그 대신, 모델에서의 time sequence 를 일정 간격으로 쪼갠 뒤, 각각 의 조각들 내에서만 학습을 진행하고, 이를 다른 조각들에 대해서도 반복한다.
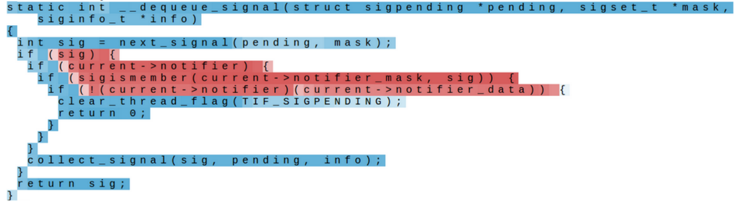
- Visualization of Hidden Units

위 사진은 quote detection cell 을 나타낸 것이다. Hidden unit 은 파란색에 가까울수록 1, 빨간색에 가까울수록 -1의 값을 갖는데, 사진을 보면 인용문에 들어있는 알파벳에 대해서 는 1에 가까운 값을 나타냄을 확인할 수 있다.
비슷하게, 이것은 if statement 를 탐지하는 cell 이다
- Image Captioning
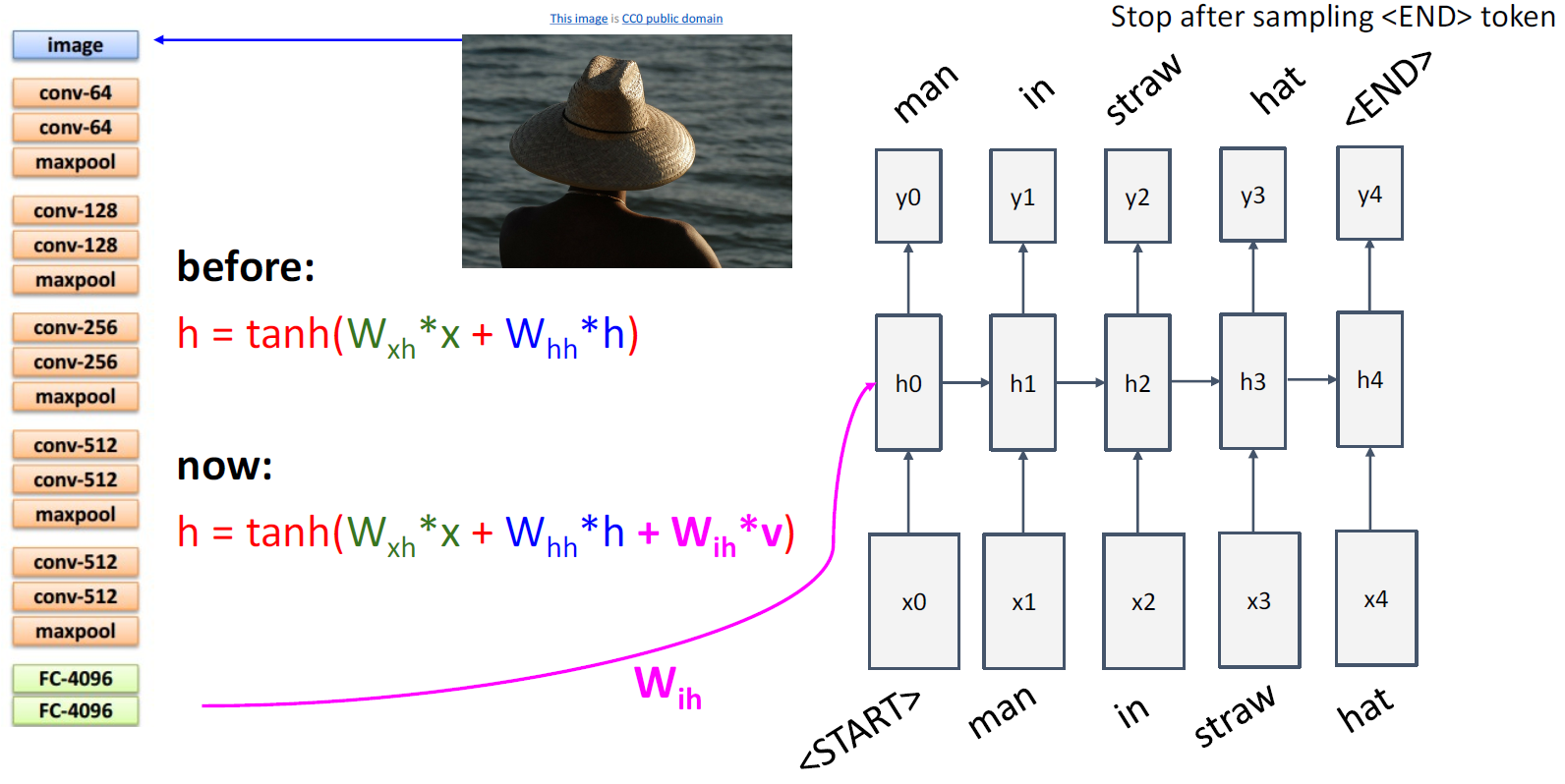
Hidden state 의 입력으로는 단어 (x), 이전 state (h) 뿐만 아니라 feature data 도 포함된 다. 맨 처음에는 START 가 입력되고, 출력값이 END 가 되면 모델의 사이클이 멈춘다.
- Vanilla RNN Gradient Flow

Backpropagation 방향을 보면, 같은 W 가 반복해서 곱해짐을 알 수 있다. 이 때문에 W 의 값이 크면 exploding gradient 가 발생할 수 있고, W의 값이 작으면 vanishing gradient 가 발생할 수 있다. 이를 해결하기 위해 gradient 의 norm 으로 나누어 scaling 하는 방 법을 생각해볼 수 있는데, 이는 gradient 를 인위적으로 조작하는 것이기 때문에 그다지 좋은 방법은 아니라고 한다.
- Long Short Term Memory (LSTM)
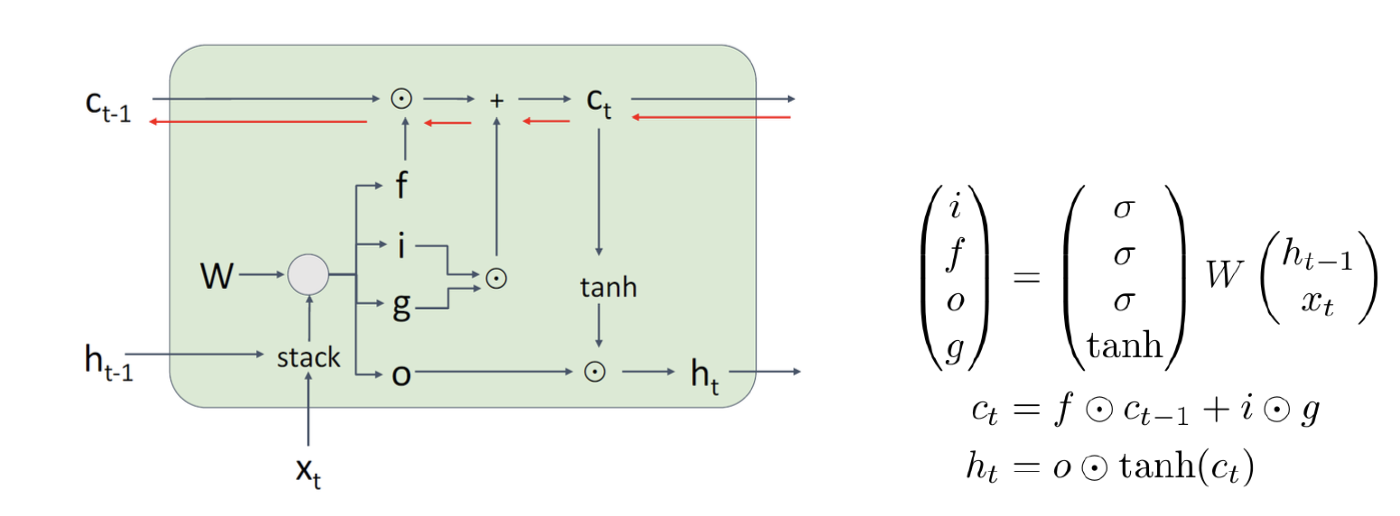
각각의 time step 마다 hidden state 뿐만 아니라 cell state 라는 것도 계산한다. f, i, g, o 는 각각 forget gate, input gate, gate gate, output gate 를 의미한다.

여기서 cell state 의 gradient flow 는 직선으로 곧게 진행한다. 마치 ResNet 에서 output 이 cell 을 건너뛰고 바로 input 으로 도착하듯이.
- Mutilayer RNNs
상황에 따라, hiddenstate 를 두 개 이상 쌓는 것이 필요할 수 있다. 하지만,RNN 에서는 층을 매우 깊게 쌓는 것은 권장되지 않는다.
3. Lecture 13: Attention
- 기존 seq2seq 의 문제점
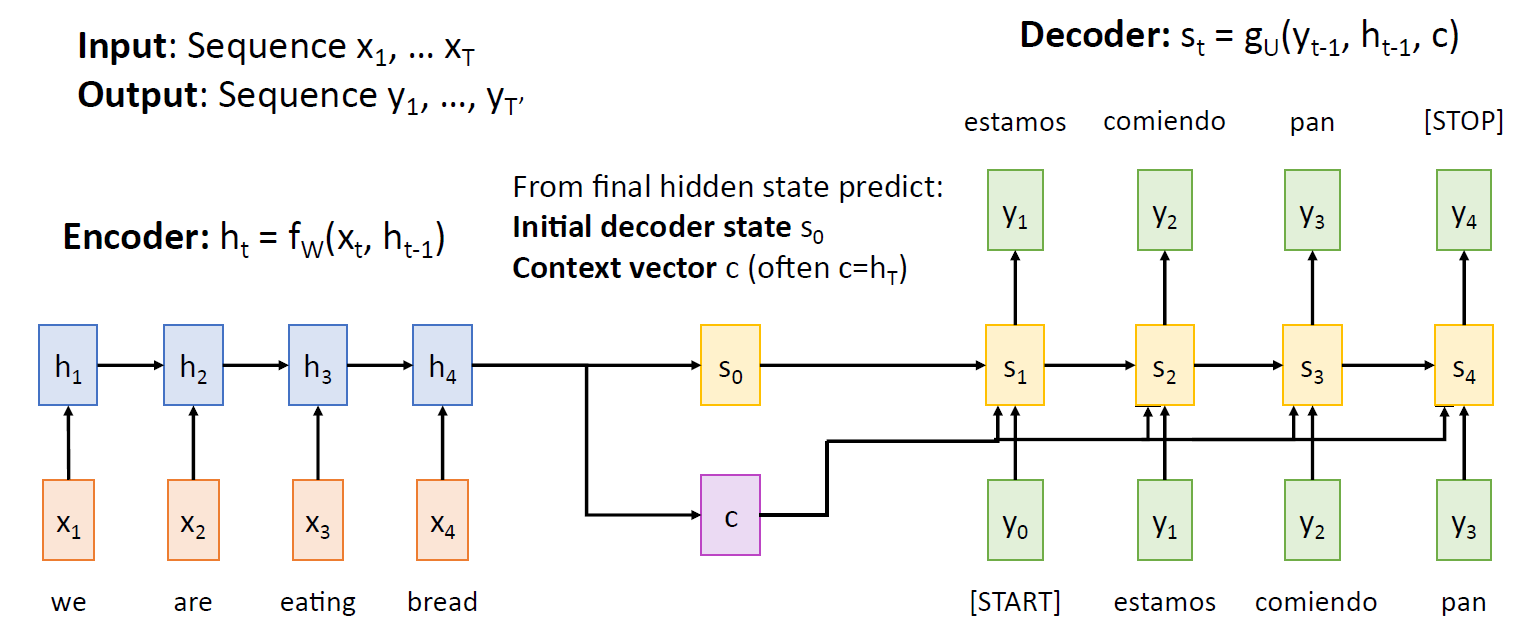
인코더와 디코더 사이에 context vector 가 존재하는데, 이 벡터는 크기가 고정되어 있다. 입력으로 받은 문장의 문맥을 크기가 정해진 벡터에 모두 담아야 하는데, 입력이 매우 길 다면 정보를 온전히 복원하기 힘들 것이다(bottleneck).
- Attention
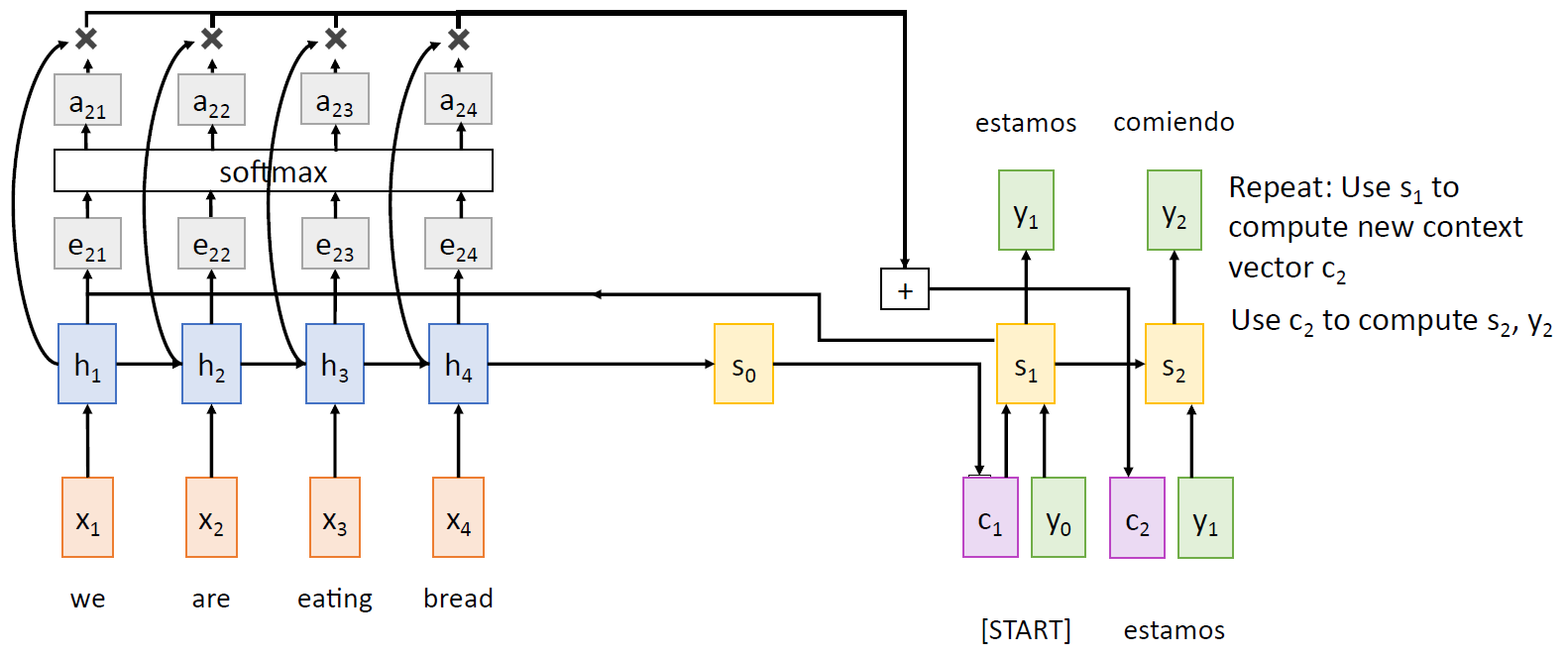
위에서 언급한 단점을 해결하기 위해, 디코더의 모든 단계에서 매번 새로운 context vector 를 참고하는 방법을 생각할 수 있다.e 는 alignmentscore 로, 네 단어 중 어떤 단 어에 얼마큼 주목할지의 정도를 결정한다.
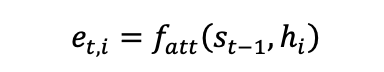
a 는 e 끼리 softmax 를 한 결과이다. 각각의 h 의 값을 이에 상응하는 a 의 비율만큼 곱한 후, 이들을 다 합하면 c 가 된다. a 의 값이 높을수록, 그 단어에 좀 더 주목한다는 뜻.
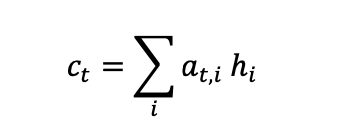
여기서 c 의 값이 각 타임에서의 context vector 이다. 이제 이 값을 이용해서 디코더의 다음 hidden state 를 계산한다.
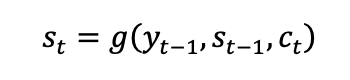
- Using Attention for Image Captioning
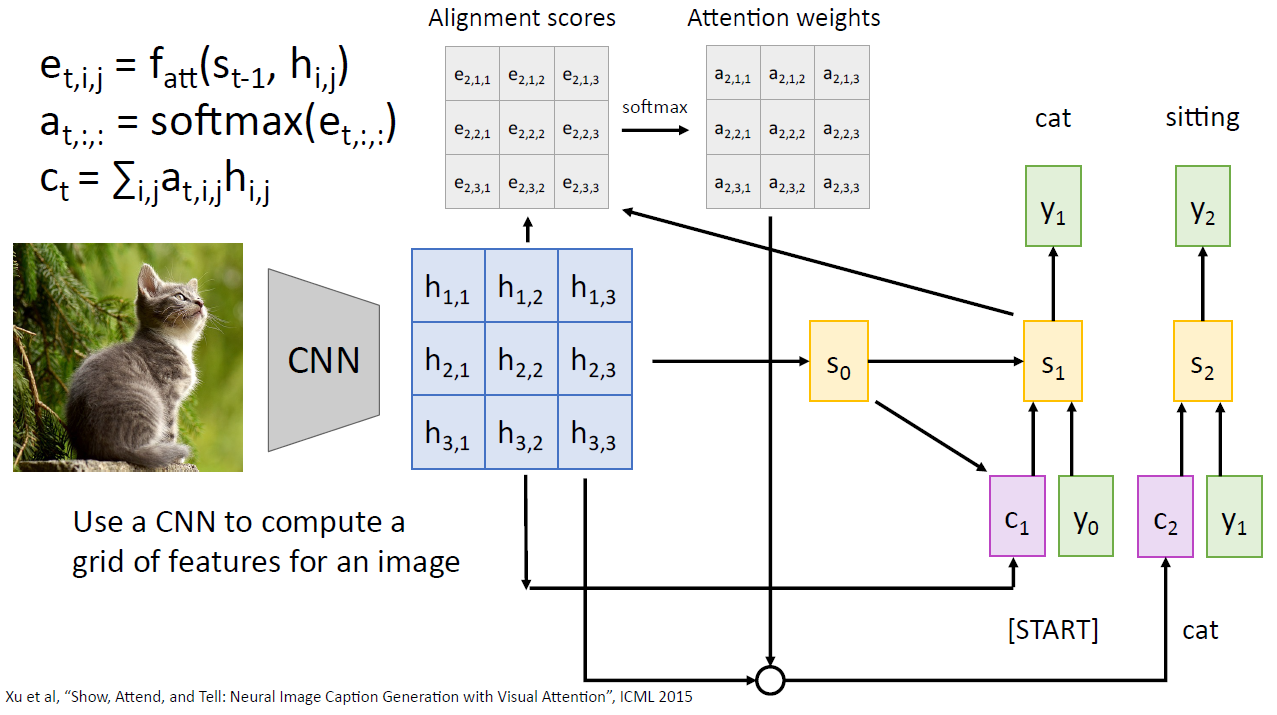

CNN 에서도 attention 의 활용이 가능하다. 아래의 사진은 디코더에서 단어가 바뀔 때마 다 관심이 집중되는 영역이 바뀜을 보여준다.
- Self-Attention
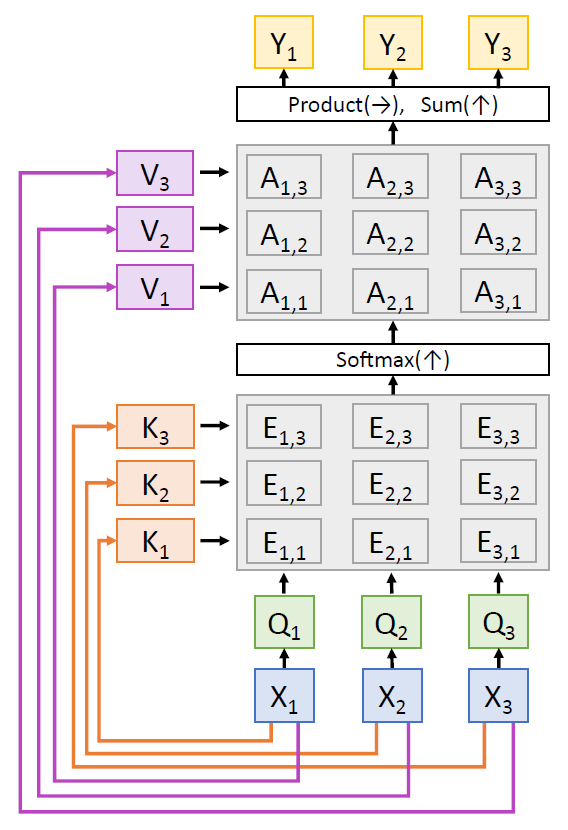
Q 는 query, K 는 key, V 는 value 를 의미한다. 예를 들어, Q1, Q2, Q3 은 각각 “I”, “love”, “you” 에 대응한다 고 하자. K1, K2, K3 도 마찬가지다. 그렇다면 Q1 과 K2 가 만나서 E12 가 생성되는데, 이는 “I” 의 “love” 와의 연관성을 의미한다. 그 다음 E 들을 softmax 하 고, 각각의 비율만큼 각 단어에 배정된 value 를 더하 는 방식이다.
- Masked Self-Attention Layer
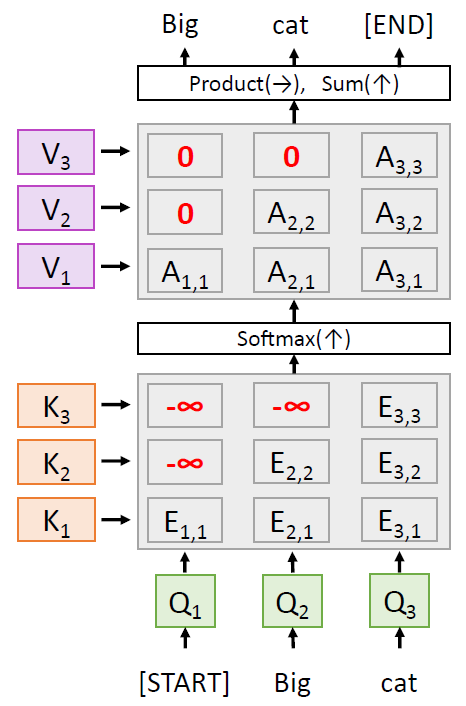
각 단어들끼리의 연관성을 구할 때, 무시하고 싶은 단어 가 있을 수도 있다. 이럴 때는 E 의 값을 -inf 로 설정하 면 된다. 이렇게 하면 softmax 후의 값이 0이 되므로 반 영이 안 되기 때문.
- Multihead Self-Attention Layer
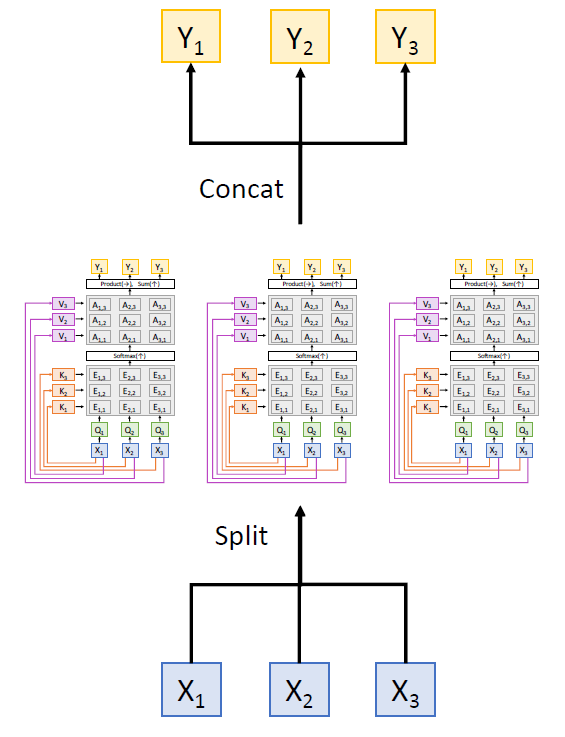
그냥 위에서 언급한 attention layer 를 여러 개 붙인거. Ensemble 과 비슷한 원리인 듯하다.
- Transformer
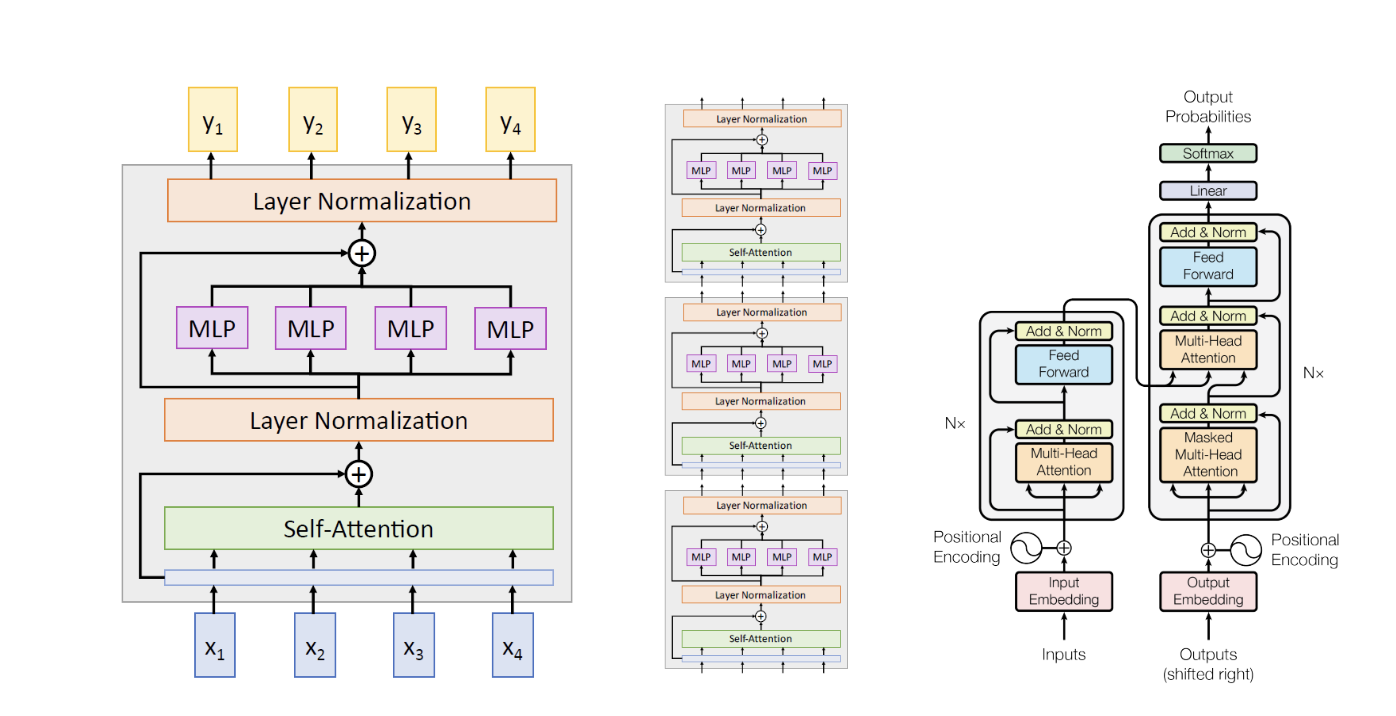
“Attention is all you need” 라는 논문에 소개된 모델이다. 실제로도 말 그대로 attention 만 사용하고, RNN 등은 사용하지 않는다. Residual connection 이 사용되었다.
4. Comment
- Attention 의 경우, 내용이 잘 이해가 안 돼서 나동빈 씨의 유튜브 동영상을 참고했다.
https://youtu.be/AA621UofTUA
'강의 & 책' 카테고리의 다른 글
| [강의 리뷰] The Background of Perception (2) (0) | 2022.05.31 |
|---|---|
| [Linear Algebra] Singular Value Decomposition (SVD), Eckart-Young: The Closest Rank k Matrix to A (0) | 2022.05.01 |
| [강의 리뷰] The Background of Perception (1) (0) | 2022.04.22 |


