
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- PytorchZeroToAll
- CS231n
- VIT
- 연세대학교 인공지능학회
- CNN
- YAI
- YAI 9기
- Googlenet
- rl
- Fast RCNN
- 자연어처리
- transformer
- nerf
- 강화학습
- cl
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- RCNN
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- Perception 강의
- NLP
- YAI 10기
- 컴퓨터 비전
- YAI 11기
- 3D
- cv
- CS224N
- 컴퓨터비전
- YAI 8기
- GaN
- Faster RCNN
- Today
- Total
목록컴퓨터비전 (21)
연세대 인공지능학회 YAI
 [Deep Learning for Computer Vision] Training Neural Network / Recurrent Network / Attention
[Deep Learning for Computer Vision] Training Neural Network / Recurrent Network / Attention
** YAI 10기 김성준님이 기초심화팀에서 작성한 글입니다. 1. Lecture 11: Training Neural Networks II Learning Rate Schedules Learning rate 를 너무 큰 값으로 설정하면 밖으로 튀어나가 버리고(explosion), 너무 작은 값으로 설정하면 학습 속도가 매우 느려지므로 적절한 값으로 설정하는 것이 중요하다. 하지만 이게 쉽지는 않은데... 이를 해결하기 위해 learning rate 를 특정 epoch 마다 규칙 적으로 감소시키는 방법이 있다. 위의 사진으로부터 learning rate 가 감소하는 지점마다 loss 도 계단 모양으로 감소함을 확인할 수 있다. 하지만 이 방식은 learning rate 를 얼마마다 감소시켜야 하는지 등을 ..
 [논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ** YAI 9기 박찬혁님이 비전논문팀에서 작성한 글입니다. Introduction 현재 Transformer와 같은 Self-attention-based 구조들이 NLP에서 주된 방식이다. 이 방법들은 주로 큰 모델에서 사전학습을 진행 후에 작은 데이터셋으로 Fine tuning하여 사용하는 방식으로 쓰인다. 이 Transformer 방식을 이미지에 바로 적용시키는 것이 이 논문의 목적이다. 이미지를 patch라는 작은 단위로 나누어서 NLP의 token과 같은 방식으로 간단한 imbedding 후에 Transformer에 집어넣는다. 이 방식은 기존 CNN이 이미지에 ..
 [논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
[논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks
SiamRPN++ ** YAI 9기 조용기님이 비디오논문팀에서 작성한 글입니다. Paper: https://openaccess.thecvf.com/content_CVPR_2019/papers/Li_SiamRPN_Evolution_of_Siamese_Visual_Tracking_With_Very_Deep_Networks_CVPR_2019_paper.pdf 1. Introduction Visual Object Tracking (VOT) 은 최근 수십 년 동안 점점 더 많은 관심을 받아왔으며 현재 매우 활발한 연구가 진행되고 있는 분야이다. Visual surveillanve, Human-Computer Interaction (HCI), 그리고 Augmented Reality (AR)과 같이 다양한 분야에서 ..
 [강의 리뷰] The Background of Perception (1)
[강의 리뷰] The Background of Perception (1)
[Perception 강의 리뷰] 1주차: The Background (1) * YAI 9기 김동하, 박준영님이 Perception 강의팀에서 작성한 글입니다. About the Course Visual Perception and the Brain 강의의 가장 주요한 목적은 “우리가 보는 것을 과연 시각 시스템은 어떻게 만들어낼까?”라는 의문에 대해 이해하고자 하는 것이다. 1960년대 이래로 사람들은 ‘주요 시각 경로에서의 뉴런의 전기생리학적 및 해부학적 특성에 대한 정보’로부터 ‘뇌가 어떻게 망막 자극을 인식하고 시각에 기반한 (visually-guided) 적절한 행동을 이끌어내는지’ 알 수 있게 될 것이라고 생각했지만, 50년 동안 이는 충족되지 않았다. 이 두 가지 개념 사이에서, ‘물리적 속성..
 [프로젝트 : CV] 다이아몬드 가격 예측
[프로젝트 : CV] 다이아몬드 가격 예측
다이아몬드 가격 예측 ** YAI 9기 석진혁님이 토이 프로젝트 진행 후 작성한 글입니다. Project Review 토이 프로젝트를 진행하며 느낀점과 시도한 것, 추가로 시도해 볼만한 다른 기법에 대해 적어보려합니다. 1) 프로젝트를 시작하기 전에, 해야 할 task를 명확하게 선정하자. 저희 조는 다이아몬드의 가격을 예측하는 프로젝트를 진행했습니다. 캐글에서 보석에 해당하는 ID와 weight, cut, shape 등 다양한 feature와 price(정답)를 담은 csv파일과 각 id에 해당하는 다이아몬드의 이미지를 받았습니다. 프로젝트를 시작할 때, 저희 조는 price에 대한 distribution이나 feature간의 상관관계 등의 데이터 분석을 하지 않고 무작정 모델을 만들고 선정한 metr..
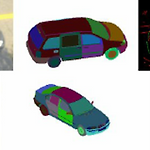 [논문 리뷰] Unsupervised Pixel-level Domain Adaptation with GAN
[논문 리뷰] Unsupervised Pixel-level Domain Adaptation with GAN
PixelDA ** YAI 9기 김기현님이 GAN 팀에서 작성한 글입니다. - 원글 링크 : https://aistudy9314.tistory.com/m/66 GAN을 사용하여 unsupervised domain adaption을 한 논문이다. 조금 오래 전 논문임에도 불구하고 foreground에 대한 높은 reconstruction performance를 보여준다. 이제 자세하게 살펴보도록 하자!! https://arxiv.org/abs/1612.05424 Unsupervised Pixel-Level Domain Adaptation with Generative Adversarial Networks Collecting well-annotated image datasets to train modern m..
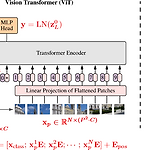 [논문 리뷰] Vision Transformer(ViT)
[논문 리뷰] Vision Transformer(ViT)
Vision Transformer(ViT) ** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다. 논문 소개 Papers with Code - Vision Transformer Explained Papers with Code - Vision Transformer Explained The Vision Transformer, or ViT, is a model for image classification that employs a Transformer-like architecture over patches of the image. An image is split into fixed-size patches, each of them are then linearly embedded, position emb..
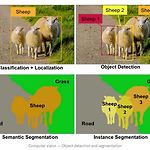 [논문 리뷰] Mask R-CNN
[논문 리뷰] Mask R-CNN
Mask R-CNN ** YAI 9기 조용기님이 비전논문심화팀에서 작성한 글입니다. 1. Introduction 비전 분야에서 객체 감지와 시멘틱 세그멘테이션은 단기간에 빠르게 성장했다. 이러한 발전은 대부분 Fast/Faster R-CNN과 FCN같은 강력한 기준 시스템에 의해 이루어졌다. 이 시스템들은 개념이 직관적이며, 유연성과 강건성(robustness)을 가질 뿐만 아니라 빠른 훈련 및 추론이 가능하다. 이 논문의 목표는 인스턴스 세그멘테이션에 대해 이와 비슷한 수준의 프레임워크를 개발하는 것이다. 1-1. Instance Segmentation 인스턴스 세그멘테이션은 이미지 내 모든 객체의 올바른 탐지와 각 인스턴스에 대한 정확한 분할이 동시에 이루어져야 하는 도전적인 작업이다. 따라서 다음의..