
Notice
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- PytorchZeroToAll
- YAI 9기
- YAI 11기
- 컴퓨터비전
- CS231n
- GaN
- Fast RCNN
- cl
- 3D
- YAI 10기
- Perception 강의
- cv
- RCNN
- YAI
- 자연어처리
- nerf
- NLP
- Googlenet
- VIT
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- transformer
- rl
- Faster RCNN
- CS224N
- 컴퓨터 비전
- CNN
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- 연세대학교 인공지능학회
- 강화학습
- YAI 8기
Archives
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] Going Deeper with Convolutions 본문
Going Deeper with Convolutions
- YAI 9기 김석님이 비전논문기초팀에서 작성한 글입니다.
0. Abstract
- 목적
→ Network 내에서 compute가 진행될 시 소모되는 자원의 효율성을 높이기 위함 - Method
- Compute 할 양을 늘어나지 않는 상태에서 depth와 width를 늘릴 수 있는 디자인 (codenamed Inception)
- Optimization 방법
→ Hebbian principle에 근거한 multi-scale processing 사용
- GoogLeNet Proposal
- Classification과 detection 목적으로 설계된 22 layer deep network
1. Backgrounds
- Object detection에서 사용한 방법
→ Model을 단일화하기 보다는 R-CNN과 같은 전통적인 CV model과 deep architecture를 병합한 형태로 설계 - “Deep”라는 phrase의 주안점
- “Inception module”의 new-level organization
- Network depth의 증가(깊어짐)
2. Referred Information
LeNet-5
- Convolutional Layer로 쌓아놓은 후 fully-connected layer로 이어 붙이는 전형적인 CNN 구조
- GoogleNet의 경우 MNIST나 CIFAR에 비해 큰 단위의 dataset인 ImageNet을 다룬다는 점에서 LeNet-5에서 layer의 개수와 layer의 각 size를 키우며 dropout을 사용하여 overfitting을 방지하는 방향으로 착안을 함

Network-in-Network
- Neural network의 representational power을 증대하기 위해 제안
- CNN의 1x1 convolution 과정을 생각하면 됨
→ Network size를 제한하는 bottleneck 없애기 위해 dimension 축소하기 위해 사용

- 이러한 1x1 convolution을 사용함으로써 주요한 performance penalty 없이 목표하였던 depth와 width를 모두 늘릴 수 있음
3. Approach
Backgrounds
- Deep Neural Network의 성능을 개선하기 위해서는 아래와 같이 size를 키워야 함
- Level의 개수를 늘려 depth를 깊게 함
- 각 level의 unit 개수를 늘려 width를 넓힘
- Drawbacks
- Size를 키우게 되면 parameter 개수가 급증하게 되므로 overfitting에 취약하게 됨
→ ImageNet의 경우 high-quality training set을 사용한다는 점에서 아래와 같이 매우 유사한 특징을 가지는 dataset 내에서도 구분을 하기 위해서는 computational cost가 상당히 많이 들게 됨 - Network의 규모가 커짐에 따라 computational resource가 급증하게 됨
→ Convolutional layer가 추가됨에 따라 computational cost가 추가된 convolutional filter 개수만큼 곱해지기 때문에 quadric하게 computational cost가 급증함
- Size를 키우게 되면 parameter 개수가 급증하게 되므로 overfitting에 취약하게 됨

- Solution
- 앞서 제시한 두 drawback의 경우, 가장 기본적으로 생각할 수 있는 방법은 기존의 fully-connected 구조를 sparsely-connected로 바꾸어 Arora에서 언급한 이론적인 underpinning들도 제거할 수 있음
- 하지만 non-uniform sparse 환경은 오늘날의 computing infrastructure에 입각하면 매우 비효율적이라는 한계를 가짐
- 또한 parallel computing에 optimal하게 적용하기 위해 sparse 보다는 fully-connected 구조를 선호하게 되고 filter 개수, batch size 등을 최대화하려는 방향으로 나아가려고 함
- 이런 점에서 filter level로 sparse하고 효율적인 dense computation이 진행되는 방안을 마련해야 함
Evaluation of Inception architecture
- Sparse matrices를 clustering하여 dense한 submatrices로 생성하는 방법이 성능에 있어서 매우 효율적이라는 선례가 존재함
- GoogLeNet의 inception architecture은 위의 sparse structure에 대한 hypothetical output을 case study하기 위해 사용하기 시작함
- Hyperparameter들을 여러 번 tuning한 결과 “Inception architecture”이 object detection과 localization에서 특히 유용함을 알 수 있었음
4. Details of the Inception architecture
- Main approach
→ Convolutional vision network의 optimal local sparse structure로의 approximation을 통하여 dense component로 변환하는 방법 - Structure
- 각 cluster는 layer의 unit을 구성하고 이는 이전 layer과 이후 layer와 모두 연결
- 이때 각 layer의 unit은 input image의 특정 region과 대응되고 이러한 unit들을 filter bank로 grouping 진행
- 이는 특정 지역에 밀집되어 있는 cluster들을 다음 인접한 layer로 1x1 convolution으로 처리할 수 있음
- Patch alignment
- Larger patch의 convolution으로 spatially spread 가능한 cluster들이 줄어들 수 있는 문제가 발생할 수 있음
- 이러한 문제를 해결하기 위해 “Inception architecture”은 filter size를 1x1, 3x3, 5x5로 제한해 둠
- 이때, 3x3 , 5x5의 비율을 증가하면 spatial concentration이 감소하게 됨
- Problem
- 5x5 convolution을 진행할 경우에도 computational cost가 늘어나게 되는데 이는 output과 convolutional layer의 개수가 늘어날 경우에도 computational cost가 급증하게 됨
- 이를 해결하기 위해 1x1 convolution을 이용하여 dimension reduction을 진행하여 computational requirements를 줄일 수 있음
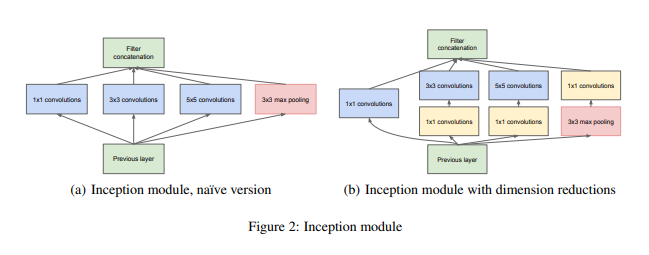
- For reproducibility and efficiency
→ 효율성 증대를 위해 “Inception modules”를 higher layer에서만 사용하고 lower layer에서는 기존의 convolutional model을 사용하면 아래와 같은 이점이 있음- 통제가 불가능할 정도의 computational complexity 없이 각 stage마다 unit의 개수를 늘릴 수 있게 됨
- 시각 정보가 다양한 scale을 통해 process하게 되어 다음 stage에서 동시에 다른 scale의 feature를 abstract
→ 이를 통해 computational problem 없이 stage의 개수와 각 stage의 width를 늘릴 수 있음
5. GoogLeNet
Architecture
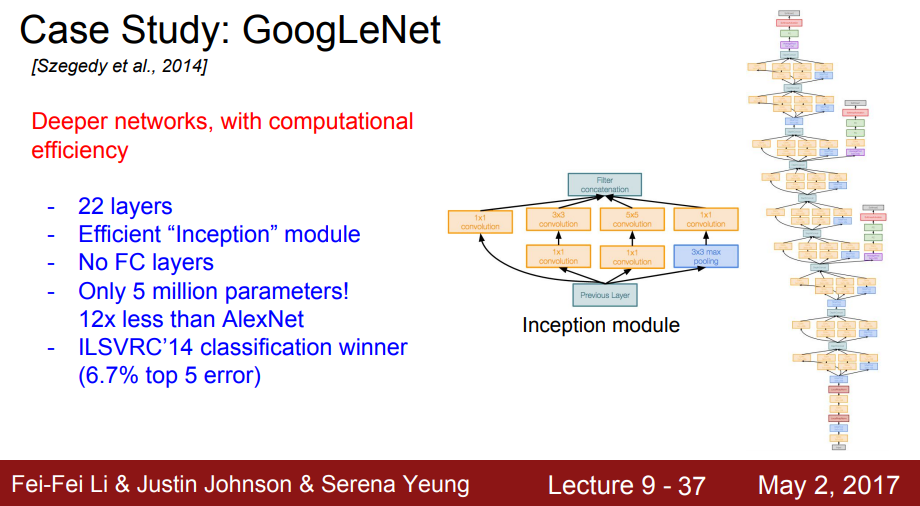
- 기본적으로 LeNet 구조에 “Inception network”를 적용한 model
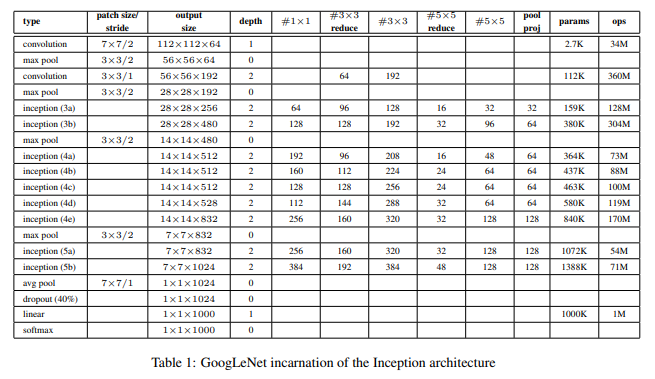
- “Inception module”부분을 포함한 모든 convolution 과정 및 1x1 convolution을 통한 reduction과 projection에서 ReLU로 activation function을 적용함
- 앞서 언급한 것처럼 효율성 증대를 위해서 “Inception modules”를 higher layer에서만 사용하고 lower layer에서는 기존의 convolutional model를 사용하였음을 알 수 있음
- Lower Layer (Traditional Convolutional Model)

- Higher Layer (Inception Module)
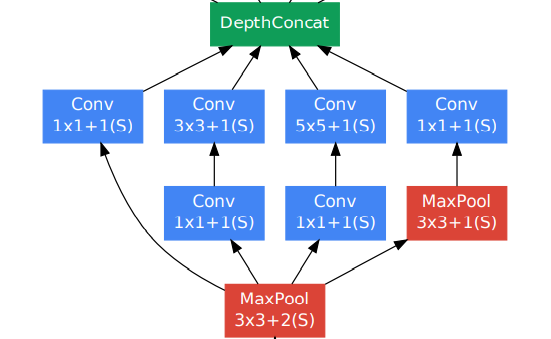
- Lower Layer (Traditional Convolutional Model)
- Auxiliary classifiers
- Gradient를 모든 layer에 효율적으로 propagation이 진행하기 위해 사용
- Network 중간에 있는 layer마다 discriminative한 layer인 auxiliary classifier을 추가함으로써 중간 checkpoint마다 output을 내보내 back propagation과 추가적인 regularization이 진행되어 degradation problem을 방지함
- 다만, 이러한 auxiliary classifier은 “inference” 단계에서는 사용하지 않음

- Final classifier
- Classifier 이전에 average pooling을 적용한 것을 볼 수 있는데 이는 fully-connected layer와는 다르게 직전 layer에서 average 값들을 1-dimensional tensor로 변환한 방법
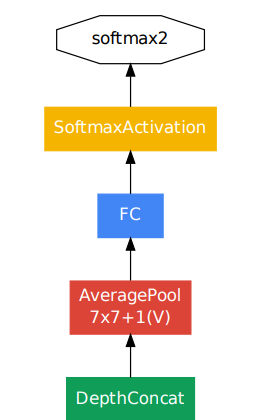
- 여기서 1-dimensional tensor로 변환하는 이유는 activation layer의 input으로 1-dimension을 받아야 하기 때문
- Average pooling을 사용함으로써 parameter 개수를 확연히 줄일 수 있어 다른 label set에 해당하는 network를 fine-tuning하기에 수월해짐
- 이렇게 fully-connected layer 대신 average pooling을 사용함으로써 top-1 accuracy를 0.6%까지 achieve할 수 있었음
- 다만, fully-connected layer를 사용하지 않을지라도 dropout의 사용 유무는 매우 중요한 issue
- Classifier 이전에 average pooling을 적용한 것을 볼 수 있는데 이는 fully-connected layer와는 다르게 직전 layer에서 average 값들을 1-dimensional tensor로 변환한 방법
Training Methodology
- 0.9 momentum의 asynchronous SGD를 사용함
- Learning rate의 경우 8-epoch마다 4%씩 감소하고 그 이외에는 fix된 상태를 유지
- Training dataset : 기존 데이터 뿐만 아니라 image의 ratio를 3/4 ~ 4/3을 유지하면서 본래 image 영역의 8% ~ 100%를 추가적으로 다양한 size의 patch로 사용
- ‘Andrew Howard’가 제안한 photometric distortion을 사용하여 overfitting 방지
- 추가적으로 random interpolation method를 사용하여 상대적으로 late하게 resize하였는데 이는 다른 hyperparameter들이 변하여도 결과의 대세가 바뀌지 않다는 것을 입증하기 위해 사용함
ILSVRC Results
- 실제 대회에서는 training에서 추가적인 external data를 사용하지 않음
- Performance 향상을 위하여 아래와 같은 과정을 거침
- 7 version의 GoogLeNet을 train하여 ensemble prediction을 적용 (이때, 모든 model들은 initialization, learning rate이 동일하게 적용되고 sampling method와 input이 random인 점만 차이를 보임)

- Input image의 경우 4 scale로 더 작은 단위의 square dimension으로 분할하여 각 square마다 4 corner과 center를 crop으로 사용하며 이들의 좌우 반전된 형태도 crop으로 사용)

- Softmax probability의 경우 multiple crop과 각각의 classifier의 average value를 사용하여 final prediction을 진행
- 7 version의 GoogLeNet을 train하여 ensemble prediction을 적용 (이때, 모든 model들은 initialization, learning rate이 동일하게 적용되고 sampling method와 input이 random인 점만 차이를 보임)
- Detection setup
- GoogleNet은 R-CNN과 비슷한 방향으로 approach를 하였으나 region classifier로 “Inception model”을 사용
- Region classifier의 proposal step은 selective search와 multi-box prediction을 결합함으로써 개선됨
- False positive를 줄이기 위해 superpixel size를 2배로 늘림으로써 selective search algorithm의 비용을 반으로 절감함
- Proposal 중에서 coverage가 증가한 것들을 절감한 결과 single model case에서 mean average precision이 1% 정도의 개선이 이루어짐
- 6개의 ConvNet을 ensemble하여 각 region을 분류함으로써 43.9%의 accuracy까지 개선함
- Conclusion
→ Dense building blocks로 설계함으로써 expect하는 sparse 구조를 approximate 하여 성능을 개선함 (다만, 이는 computational cost를 줄이는 방향으로만 개선이 이루어짐)
'컴퓨터비전 : CV > CNN based' 카테고리의 다른 글
| [논문 리뷰] Conv-TasNet: Surpassing Ideal Time-Frequency magnitude Masking for Speech Separation (0) | 2022.09.26 |
|---|---|
| [논문 리뷰] SiamRPN++: Evolution of Siamese Visual Tracking with Very Deep Networks (0) | 2022.05.08 |
| [논문 리뷰] Mask R-CNN (0) | 2022.03.20 |
| [논문 리뷰] Retina Net : Focal loss (0) | 2022.03.12 |
| [논문 리뷰] FPN : Feature Pyramid Network (0) | 2022.03.12 |
'컴퓨터비전 : CV/CNN based' Related Articles
more




Comments