
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- PytorchZeroToAll
- cl
- CS231n
- YAI 8기
- 컴퓨터비전
- Perception 강의
- YAI 11기
- Faster RCNN
- cv
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- NLP
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- 연세대학교 인공지능학회
- RCNN
- YAI 9기
- nerf
- rl
- VIT
- 3D
- YAI
- 컴퓨터 비전
- 강화학습
- YAI 10기
- Fast RCNN
- 자연어처리
- CNN
- transformer
- GaN
- Googlenet
- CS224N
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] GoogLeNet : Going deeper with convolutions 본문
YAI 11기 최가윤님이 작성한 글입니다.
[GoogLeNet] Going deeper with convolutions (2015 CVPR)
Reference
https://arxiv.org/pdf/1409.4842.pdf
https://en.wikipedia.org/wiki/Gabor_filter
[GoogLeNet (Going deeper with convolutions) 논문 리뷰]https://phil-baek.tistory.com/entry/3-GoogLeNet-Going-deeper-with-convolutions-%EB%85%BC%EB%AC%B8-%EB%A6%AC%EB%B7%B0
Abstract
Improved utilization of the computing resources inside the network
- Carefully crafted design that allows for increasing the depth and width of the network
- Keep the computational budget constant
- To optimize quality, the architecture decisions were based on the Hebbian priniple and the intuition of multi-scale processing
1 Introduction
Progress is mainly due to a consequence of new ideas, algotirhms and improved network architectures
GoogLeNet
- Uses 12x fewer parameters than the winning architecture of Krizhevsky et al
- Gain in object-detection from the synergy of deep architectures and classical computer vision, like the R-CNN algorithm
- Ongoing traction of mobile and embedded computing, the efficiency of algorithms (power and memory use)
Deep
1. Introduce a new level of organization in the form of the “Inception module”
2. Increased network depth
Inception
- A logical culmination of Network in Network
- Taking inspiration and guidance from the theoretical work by Arora
2 Related Work
CNN with a standard structure
- Stacked convolutinoal layers (with contrast normalization and max-pooing)
- Followed by one or more fully-connected layers
→ Increase the number of layers and layer size while using dropout to address the problem of overfitting
Concern: max-pooling layers result in loss of accurate spatial information

Serre et al
Use a series of fixed Gabor filters of different sizes in order to handle multiple scales
→ Fixed 2-layer deep moder
→ Ours: all filters are learned and repeated many times
Network in Network
Increase the representational power of neural networks
Method could be viewed as additional $1\times1$ convolutional layers followed typically by the rectified linear activation → easily integrated in the current CNN pipelines
Ours: $1\times1$ convolutional layers used mainly as dimension reduction modules to remove computational bottleneck (otherwise limit the size of our networks) → allows increasing the depth, width without significant performance penalty
R-CNN
Decompose the overall detection problem into two subproblems
1. Utilize low-level cues such as color and superpixel consistency for potential object proposals in a category-agnostic fashion
2. Use CNN classifiers to identify obejct categories at those locations
⇒ Leverages the accuracy of bouding box segmentation with low-level cues, as well as the highly powerful classification power of SOTA CNNs
Ours: Enhancement in both stages, such as multi-box prediction for higher object bounding box recall, and ensemble approaches for better categorization of bounding box proposals
3 Motivation and High Level Considerations
Improving the performance: increase the size
1. depth: the number of levels
2. width: the number of units at each level
⇒ Drawbacks
1. a larger number of parameters makes the enlarged network more prone to overfitting, especially if the number of labeled examples in the training set is limited
→ bottleneck2. Increased use of computational resources
⇒ Solving issues: Moving from fully connected to sparsely connected architectures, even inside the convolutions
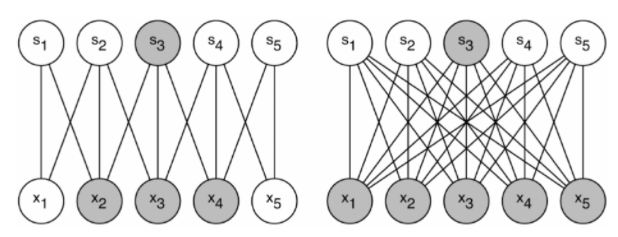
If the probabiltiy distribution of the dataset is rerpresentable by a large, very sparse deep neural network, then the optimal network topology can be constructed layer by layer (1) analyze the correlation statistics of the activations of the last layer (2) clustering neurons with highly correlated outputs (Hebbian principle suggest that the underlying idea is applicable even under less strict conditions, inpractice)
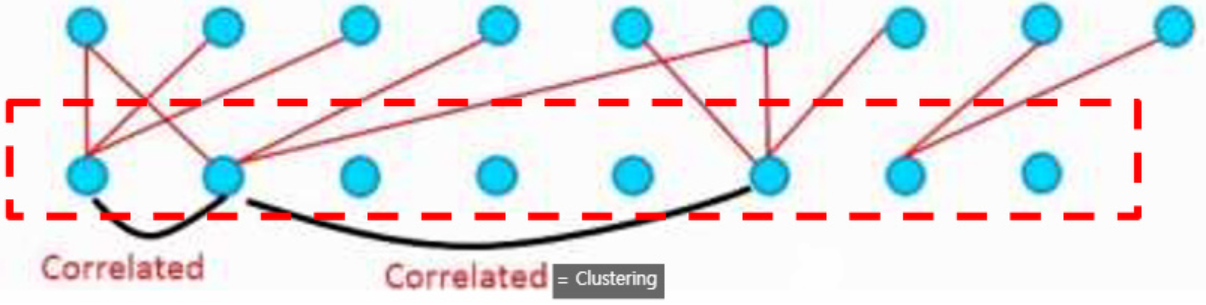
Todays computing infrastructures: inefficient when it comes to numerical calculation on non-uniform sparse data structures
1. The overhead of lookups and caches misses is so dominant → switching to sparse matrices would not pay off. The gap is widened even further by the use of steadily improving, highly tuned, numerical libriaries (↔ allow fast for dense matrix multiplication)
2. Require more sophisticated engineering and computing infrastructure
Convolutions: implemented as collections of dense connections to the patches in the earlier layer
ConvNets: Used random and sparse connection tables in the feature dimensions → break the symmetry and improve learning
⇒ Trend changes to full connections for better optimize parallel computing. Structure uniformity, a large number of filters, greater batch size → Utilizing efficient dense computation
Make use of the extra sparsity even at filter level?
Clustering sparse matrices into relatively dense submatrices → May be utilize for non-uniform architectures!
Ours
1. Assessing the hypothetical output to approzimate a sparse structure
2. Convering the hypothesized outcome by dense, readily available components
⇒ SOTA, Especially useful in the context of localization and object detection
4 Architectural Details
Idea
Find out how an optimal local sparse structure in a convolutional vision network → approximated and covered by readily available dense components
Assuming translation invariance = Ours will be built from convolutional building blocks
- Find the optimal local construction
- Repeat it spatially
Arora
(1) analyze the correlation statistics of the activations of the last layer
(2) clustering neurons with highly correlated outputs → cluster form the units of the next layer and are connected to the units in the previous layer
Assume, each unit from the earlier layer corresponds to some region of the input image and grouped into filter bank
Lower layers (close to input): Units concentrate in local regions → covered by a layer of $1\times1$ convolutions in the next layer
More spatially spread out clusters → covered by a larger patches → decreasing number of patches over larger and larger regions
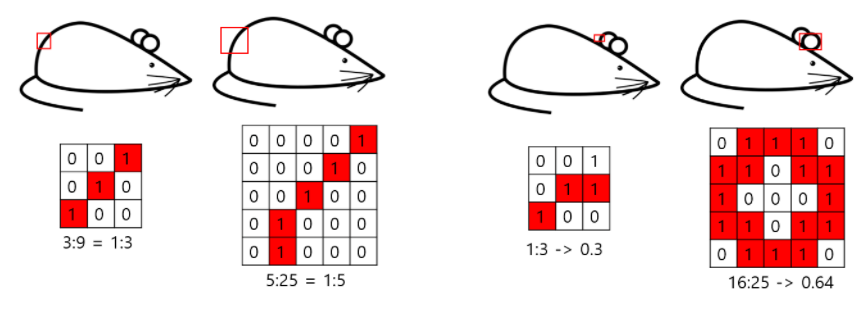
To avoid patch-alignment issues, restricted filter sizes, $1\times1,\ 3\times3,\ 5\times5$
⇒ Architecture is a combination of all those layers with their output filter banks concatenated into a single output vector forming the input of the next stage
Add an alternative parallel pooling path
Inception modules are stacked on top of each other - output correlation statistics are bound to vary:
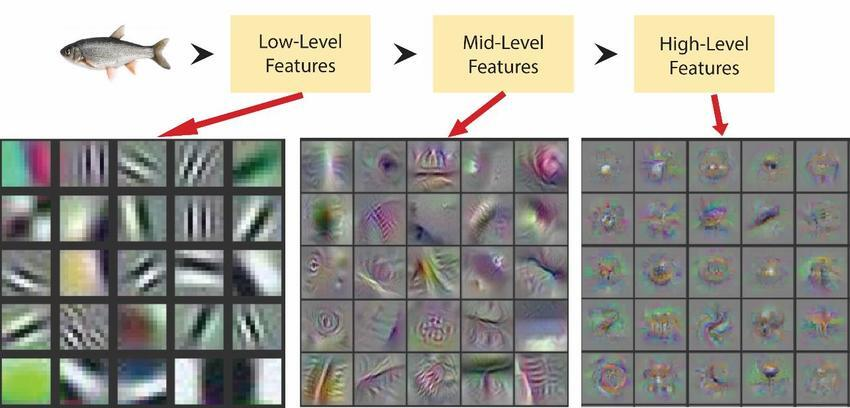
- Higher abstraction are captured by higher layers and their spatial concentration is expected to decrease → the ratio of $3\times3$ and $5\times5$ convolutions should increase as we move to higher layers
Problem: in this naive form, $5\times5$ can be prohibitively expensive → even more pronounced once pooling units are added to the mix: their number of output filters equals to the number of filters in the previous stage
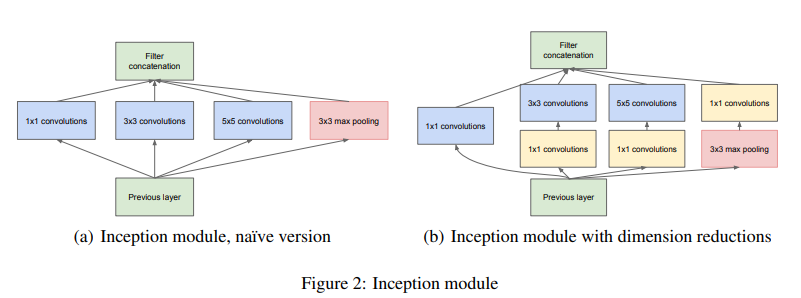
⇒ Applying dimension reductions and projections wherever the computational requirements would increase too much: Based on the success of embeddings - even low dimensional embeddings might contatin a lot of informations about a relatively large image patch
Embedding represent information in a dense, compressed form → $1\times1$ convolutions are used to compute reductions before the expensive $3\times3,\ 5\times5$ convolutions. Also include the use of ReLU which makes them dual-purpose
For memory efficiency, using Inception modules only at higher layers while keeping the lower layers in traditional convolutional fashion is recommened
Beneficial
1. Increasing the number of units at each stage without an uncontrolled blow-up in computational complexity: Ubiquitous use of dimension reduction ⇒ increase both the width of each stage and depth
2. Aligns with the intuition that visual information should be processed at various scales and then aggregated → next stage can abstract features from different scales simultaneously
5. GoogLeNet
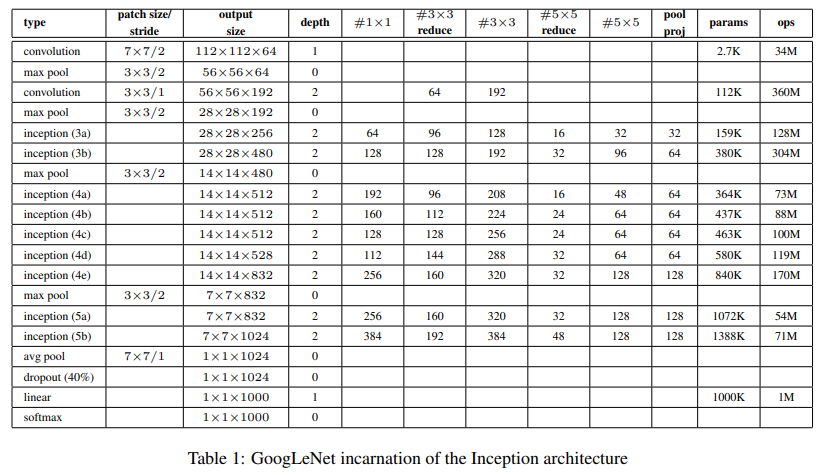
Partiular incarnation of the Inception architecture
- ReLU for all convolution layers
- $224\times224$ RGB receptive field
- Mean subtraction
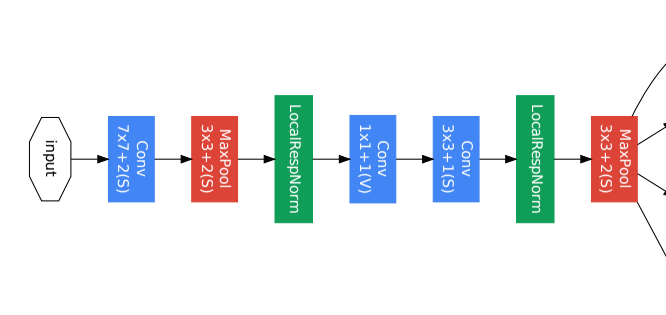
Lower layer part: Traditional CNN architecture
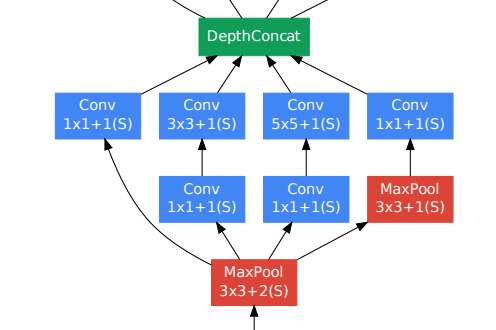
Inception Module: Parallel Convolutional layer
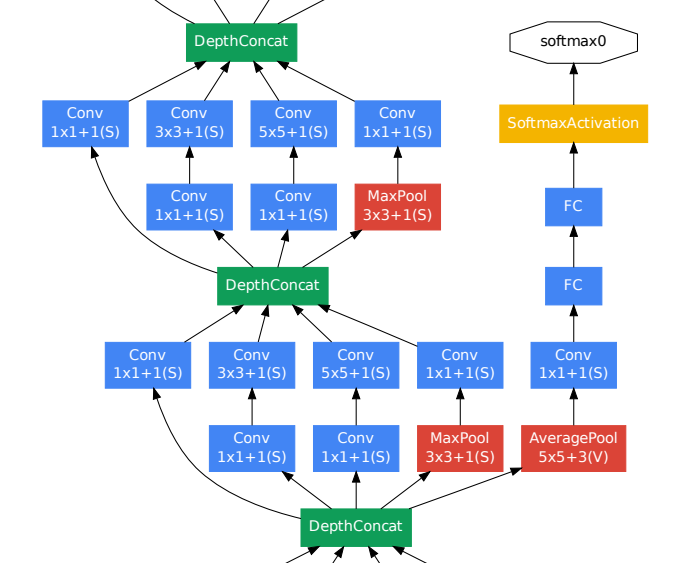
Auxiliary Classifier: To avoid gradient vanishing, encourage discrimination in the lower stages and increase the gradient signal that gets propagated back and provide additional regularization
Not used for test
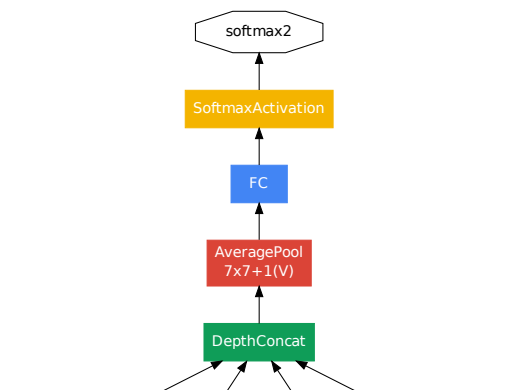
Global average pooling
Discussion
Gabor filter

Linear filter used for texture analysis whether there is any specific frequency content in the image in specific directions in a localized region around the point or region of analysis
Similar to human visual system
In the spatial domain, a 2D Gabor filter is a Gaussian kernel function
'컴퓨터비전 : CV > CV 논문 리뷰' 카테고리의 다른 글
| [논문 리뷰] CoCa : Contrastive Captioners are Image-Text Foundation Models (0) | 2023.03.12 |
|---|---|
| [논문 리뷰] Focal Self-attention for Local-Global Interactions in Vision Transformers (1) | 2023.01.14 |
| [논문 리뷰] Mask R-CNN (1) | 2023.01.14 |

