
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- transformer
- 연세대학교 인공지능학회
- rl
- YAI 8기
- PytorchZeroToAll
- NLP
- 3D
- CS231n
- GaN
- cl
- YAI 9기
- Fast RCNN
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- 컴퓨터비전
- YAI 11기
- nerf
- 자연어처리
- cv
- YAI
- RCNN
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- Faster RCNN
- 컴퓨터 비전
- YAI 10기
- VIT
- Perception 강의
- CNN
- 강화학습
- Googlenet
- CS224N
- Today
- Total
목록강의 & 책 (16)
연세대 인공지능학회 YAI
 [Linear Algebra] Singular Value Decomposition (SVD), Eckart-Young: The Closest Rank k Matrix to A
[Linear Algebra] Singular Value Decomposition (SVD), Eckart-Young: The Closest Rank k Matrix to A
Singular Value Decomposition, Eckart-Young: The Closest Rank k Matrix to A * YAI 9기 송예원님이 선형대수 강의팀에서 MIT 18.065 by Gilbert Strang을 수강한 후 작성한 글입니다. Lecture 6 : Singular Value Decomposition (SVD) Introduciton 6강에서는 rectangular matrix의 factorization 중 하나인 Singular Value Decomposition에 대해 다룬다. 또한 SVD와 linear transformation의 기하학적 의미 및 polar decomposition과의 연관성에 대해 다룰 것이다. Preliminary singular value s..
 [CS231n] Training Neural Networks II, Deep Learning Software
[CS231n] Training Neural Networks II, Deep Learning Software
Training Neural Networks II, Deep Learning Software * YAI 9기 박찬혁 님이 심화 팀에서 작성한 글입니다. Lecture 7 : Training Neural Networks II Optimization SGD 6강에서 배치단위로 Gradient Descent를 진행하는 SGD라는 Optimizer를 소개했다. SGD의 식은 아래와 같다. $$ x_{t+1}=x_t-\alpha\nabla f(x_t) $$ 하지만 SGD에는 단점이 있는데 아래 그림처럼 현재 지점에서의 기울기만 보고 지그재그로 찾아간다는 점이다. 이렇게 진행을 하게되면 바로 최적점을 찾아가는 것 보다 훨씬 느리게 학습이 진행된다. 또한 이렇게 현재 지점에서의 기울기만 보고 이동지점을 판단한다면 L..
 [강의 리뷰] The Background of Perception (1)
[강의 리뷰] The Background of Perception (1)
[Perception 강의 리뷰] 1주차: The Background (1) * YAI 9기 김동하, 박준영님이 Perception 강의팀에서 작성한 글입니다. About the Course Visual Perception and the Brain 강의의 가장 주요한 목적은 “우리가 보는 것을 과연 시각 시스템은 어떻게 만들어낼까?”라는 의문에 대해 이해하고자 하는 것이다. 1960년대 이래로 사람들은 ‘주요 시각 경로에서의 뉴런의 전기생리학적 및 해부학적 특성에 대한 정보’로부터 ‘뇌가 어떻게 망막 자극을 인식하고 시각에 기반한 (visually-guided) 적절한 행동을 이끌어내는지’ 알 수 있게 될 것이라고 생각했지만, 50년 동안 이는 충족되지 않았다. 이 두 가지 개념 사이에서, ‘물리적 속성..
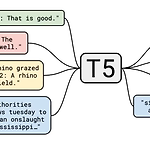 [CS224n] T5 and Large Language Models
[CS224n] T5 and Large Language Models
Lecture-14: T5 and Large Language Models ** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다. T5 Ideas Which transfer learning methods work best, and what happens when we scale them up? → T5 What about non-English pre-trained models? → modify T5 for multilingual model How much knowledge does the model learn during pre-training? Does the model memorize data during pre-training? Which Transformer modifications work..
 [PyTorchZeroToAll] VGG-Net (Visual Geometry Group)
[PyTorchZeroToAll] VGG-Net (Visual Geometry Group)
**YAI 9기 강재범님이 기초1팀에서 작성한 글입니다. 1. Introduction 기존의 CNN을 발전시킨 모델 중 하나이다. 특징은 convolution layer의 kernel (filter) size가 모두 3x3이고, input image는 3 channel의 224x224 픽셀의 이미지를 받도록 설계되어 있다는 점이다. 또, layer의 개수 (11개, 13개, 16개, 19개)에 따라 4가지 모델이 있다. 각각 vgg11, vgg13, vgg16, vgg19로 부른다. 각가의 구조는 다음 그림과 같다. 'C' type은 마지막 layer의 kernel size가 1x1인데 일반적으로 vgg16이라 부르는 모델은 'D' type을 사용한다. 'A-LRN'에서 LRN은 당시에 ReLu acti..
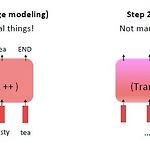 [CS224n] Subword Modeling & Pretraining
[CS224n] Subword Modeling & Pretraining
Subword Modeling & Pretraining ** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다. 1. Introduction 언어 모델링에서 중요한 부분 중 하나인 단어를 어떻게 표현할 것인가를 살펴보겠습니다. 만약 단어의 개수가 유한하다는 가정, 즉 finite vocabulary assumptions를 기반으로 할 경우에는 단어의 변환, 오타, 새로운 단어 등이 모두 unknown words로 동일하게 매핑되게 됩니다. 따라서 이러한 word structure 혹은 morphology를 다루는 방식이 필요하게 됩니다. 한편, 사전 학습된 대규모의 모델은 자연어 처리에 있어서 거의 표준이 되었고, 그 성능도 매우 뛰어납니다. 이러한 방법론에 대해서도 다뤄보겠습니다. 2. Subwo..
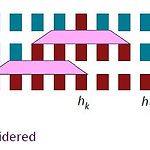 [CS224n] 어텐션 (Attention)
[CS224n] 어텐션 (Attention)
어텐션 (Attention) ** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다. 1. Introduction 앞선 글에서 설명드렸던 Seq2Seq의 경우 하나의 hidden state가 모든 source text의 정보를 포함하고 있습니다. 이 때문에 sentimental analysis와 같은 단순한 태스크에서는 성능이 괜찮지만, translation과 같은 복잡한 태스크에서는 information bottleneck이 발생할 수 있습니다. 이 문제를 해결하기 위해 attention 모델이 제안되었습니다. Attention은 decoder의 각 step에서 encoder와 direct connection을 활용하여 source sentence의 특정 부분에 집중합니다. 사람이 실제로 번역을 ..
 [CS224n] 기계 번역 (Machine Translation)
[CS224n] 기계 번역 (Machine Translation)
기계 번역 (Machine Translation) ** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다. 1. Introduction Machine translation은 어떤 한 언어의 $x$라는 문장을 또다른 언어의 $y$라는 문장으로 번역하는 태스크를 의미합니다. 이때, $x$의 언어를 source language라고 하고, $y$의 언어를 target language라고 부릅니다. 과거에는 rule-based와 dictionary lookup table 등의 방식을 이용했지만, 문법(grammar)이나 의미론(semantic) 등의 이유로 인해서 정보를 잘 전달하지 못했다는 한계가 존재합니다. 이러한 기계 번역의 역사를 살펴보면 아래와 같습니다. 2. Statistical MT (SMT) ..