
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- YAI 9기
- YAI 8기
- YAI 10기
- CS231n
- Googlenet
- transformer
- Perception 강의
- 연세대학교 인공지능학회
- PytorchZeroToAll
- CNN
- Faster RCNN
- GaN
- 컴퓨터비전
- Fast RCNN
- 강화학습
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- NLP
- rl
- 3D
- YAI
- 자연어처리
- RCNN
- 컴퓨터 비전
- VIT
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- cv
- cl
- nerf
- YAI 11기
- CS224N
- Today
- Total
연세대 인공지능학회 YAI
[CS224n] 기계 번역 (Machine Translation) 본문
기계 번역 (Machine Translation)
** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다.
1. Introduction
Machine translation은 어떤 한 언어의 $x$라는 문장을 또다른 언어의 $y$라는 문장으로 번역하는 태스크를 의미합니다. 이때, $x$의 언어를 source language라고 하고, $y$의 언어를 target language라고 부릅니다. 과거에는 rule-based와 dictionary lookup table 등의 방식을 이용했지만, 문법(grammar)이나 의미론(semantic) 등의 이유로 인해서 정보를 잘 전달하지 못했다는 한계가 존재합니다. 이러한 기계 번역의 역사를 살펴보면 아래와 같습니다.
2. Statistical MT (SMT)

Statistical Machine Translation (SMT)가 등장한 것은 1990년대로, 2010년 초반까지만 해도 활발히 사용되었습니다. Data의 확률적 모델을 학습하여, Bayes' rule을 기반으로 하여 문장을 번역합니다. 즉, 이를 식으로 나타내면 아래와 같습니다.
$$
\text{arg max}_y P(x|y)P(y)
$$
이러한 모델링을 위해서는 모델이 두 가지가 필요합니다.
- Translation model (left): 이는 단어와 구가 어떻게 번역되어야 하는 지를 모델링합니다 (fidelity). Parallel data로부터 학습이 됩니다.
- Language model (right): 좋은 문장을 어떻게 작성하는 지를 모델링합니다 (fluency). 6개의 단일 언어로 이루어진 데이터로부터 학습이 됩니다.
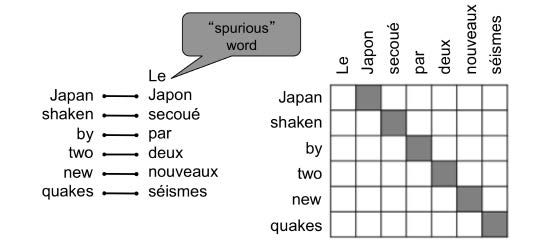
이러한 SMT의 단점으로는 매우 복잡하며, feature engineering이 과도하게 필요하다는 것이고, 또한 이러한 일련의 과정을 위해 필요한 리소스와 사람의 노력이 상당하다는 것입니다.
Translation 모델을 학습시키는 방법은 다음과 같습니다. 일단, source language와 target language의 쌍으로 이루어진 대용량의 parallel data가 필요한데, latent variable (alignment; 즉, counterpart를 연결)을 추가하여 grammatical/typological difference를 포착해냅니다. 그러나 이때, 어떤 단어들은 counterpart가 없다는 문제가 존재합니다. 또한, 단어들의 관계가 항상 일대일(one-to-one)이 아니라, 일반적으로 다대일(many-to-one), 일대다(one-to-many), 다대다(many-to-many)의 의미 구조를 갖는다는 문제도 있습니다. 또한, argmax를 계산할 때 모든 y에 대해서 계산하는 것은 그 비용이 매우 비싸다는 단점이 있스비다. 따라서 Viberti algorithm이라는 방식을 이용해 각 단어로 시작할 경우 그 뒤에 따를 수 있는 단어들의 확률을 연속적으로 계산하는 방법을 사용하기도 합니다.
3. Neural Machine Translation
Neural Machine Translation (NMT)는 종단간 신경망 네트워크(end-to-end neural networks)를 이용하여 기계번역을 수행하는 방식을 의미합니다. 기본적인 구조는 Seqeunce-to-Sequence (Seq2Seq)의 구조를 갖습니다. 일반적으로 두 개의 서브 모듈을 갖게 되는데, source sentence를 읽는 부분에 해당하는 encoder와 target sentence를 생성하는 decoder로 나뉩니다. 이때, neural network의 구조는 sequential data(순차적 자료)를 처리하기 위한 LSTM 등을 주로 사용합니다. 물론 이러한 구조는 문서 요약, 대화, 파싱, 코드 생성 등과 같은 다른 자연어 처리 태스크에도 많이 활용됩니다.
이러한 Seq2Seq 구조는 근본적으로 conditional language model에 속합니다. NMT는 $P(y|x)$를 아래와 같은 방식으로 직접 계산해내게 됩니다.
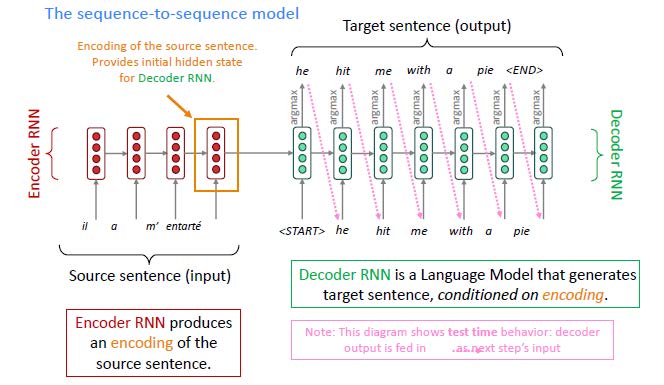
$$
P(y|x) = P(y_1|x) P(y_2|y_1, x) P(y_3|y_1, y_2, x) \dots P(y_T|y_1, \dots, y_{T-1}, x)
$$
여기서 $P(y_i|y_1, \dots, y_{i-1}, x)$는 현재까지 생성된 문장의 단어들과 source sentence $x$를 조건으로 할 때, 다음에 올 단어의 확률값을 의미합니다. 이러한 conditional language model의 경우 낮은 perplexity를 갖게 됩니다. 왜냐하면 생성해야 할 문장에 대한 정보를 많이 갖고 있기 때문입니다.
이러한 모델을 훈련시키기 위해서는 많은 양의 parallel corpus를 필요로 합니다. 이를 이용해서 encoder LSTM을 거려 target LSTM에 정보를 전달(feed)하면, 각 위치의 단어들을 예측하는 방식으로 학습이 됩니다. 이때, 손실 함수(loss function)로는 NLL(negative log likelihood) 혹은 negative log probability를 이용하게 됩니다. 그리고 이렇게 계산된 loss를 통해 back-propagation이 일어나며, encoder와 decoder가 동시에 학습이 진행됩니다. 따라서 단일 계(system)로 학습이 이루어지기 때문에, 종단간 학습이라고 부르는 것입니다.
이러한 방식은 SMT에 비해 많은 장점들이 존재합니다. 일단, 성능이 우수합니다. 문맥 정보와 어구의 유사도를 더 잘 활용하기 때문이라고 강의에서는 말합니다. 또한, 단일 신경망으로 종단간 학습이 가능하다는 것이고, feature engineering이 필요없기 때문에 사람의 엔지니어링 노고가 줄어든다는 것이 있습니다. 그러나 단점으로는 일반적으로 결과에 대한 해석이 가능하지 않고, 규칙이나 가이드라인이 없기 때문에 제어하기가 매우 어렵다는 점이 꼽힙니다.
3-1. Multi-layer RNNs
Multi-layer RNNs 혹은 stacked RNNs이란 여러 개의 RNNs들을 쌓아 더 복잡한 표현(representation)을 구성할 수 있게 만든 것으로, 더 높은 성능을 보이게 됩니다. 가장 낮은 단에 위치한 RNNs은 저수준(low-level)의 feature들을 학습하는 반면에, 더 높은 곳에 위치한 RNNs은 고수준(high-level)의 feature를 연산해낸다고 생각할 수 있습니다. 여기서 저수준이라면 예를 들어 POS, NER 등과 같은 기본적인 개념을 학습하는 것을 의미하고, 고수준은 의미론상 수준에서 전체적인 구조나 의미, 혹은 감정(긍정/부정) 등을 학습한다는 것입니다. 이러한 모델링을 할 때 구체적으로는 skip-connections와 dense-connections을 사용하면 좋다고 알려져 있습니다.
3-2. Decoding
Decoder에서 decoding을 하는 방식과 전략은 여러 개입니다. 모든 가능한 경우에 대해서 계산하는 것은 사실상 불가능하기 때문에, 상황과 모델에 맞는 적절한 decoding 방법을 사용하는 것도 성능을 올릴 수 있는 방법입니다.
3-2-1. Greedy Decoding
가장 흔히 사용되는 것은 greedy한 방식으로 각 step별 가장 probable한 단어를 찾아내는 것입니다. 그러나 지역적으로 가장 적합한 단어를 찾은 뒤 연속적으로 진행하다보니 올바른 문장이 생성되지 않고 stuck될 수 있습니다.
3-2-2. Exhaustive Search Decoding
말 그대로 모든 possible sequence에 대해서 계산하는 것이지만, 앞서 언급했듯이 너무나도 비효율적이고 연산량이 많습니다.
3-2-3. Beam Search Decoding

Beam search는 beam size를 정하고 (보통 5~10), 해당 beam size만큼의 k-most probable partial translations에 대해서만 계산을 이어나가는 것을 의미합니다. 이때, 각 후보 번역 문장들을 hypotheses라고 부르기도 합니다. 이는 가장 optimal한 solution을 찾는 것은 아니지만 exhaustive search에 비해서 계산이 빠르면서도 greedy decoding에 비해 stuck될 확률이 적다는 장점이 있습니다.
Beam search는 두 가지 경우가 발생할 때까지 계속 진행하게 됩니다.
- n개의 hypotheses가 complete할 때까지: 멈춤 조건으로
<END>토큰이 등장하면 hypothesis가 끝이 납니다. 따라서 해당 hypothesis는 중단하고 다른 hypothesis들에 대해 계속 탐색을 진행합니다. - 사전에 정해놓은 cutoff value (T timestep)에 도달할 대까지
이후 가장 높은 score를 가진 hypothesis를 결정하게 됩니다. 그러나 이때, 긴 문장일수록 더 낮은 점수를 갖기 때문에, 이러한 unfair한 bias를 보정하기 위해 length에 대해 normalize하는 과정을 거칩니다.
4. Evaluation of MT
기계번역의 평가는 아래와 같은 평가지표(metric)로 수행하게 됩니다.
4-1. BLEU (Bilingual Evaluation Understudy)
BLEU는 기계번역 문장과 사람이 번역한 한 개 혹은 여러 개의 번역문과 비교하여 n-gram 기반의 precision 기준 유사도를 측정합니다. 이때, n-gram의 n으로는 1, 2, 3, 4-grams이 일반적으로 사용되며, 너무 짧은 기계 번역에 대해서는 penalty가 주어집니다. 그러나 가장 큰 단점은 하나의 문장을 다르게 번역할 수 있는데, n-gram의 overlap으로만 측정하는 것은 실제로 좋은 번역임에도 불구하고 낮은 bleu score를 보일 수 있다는 점이 꼽힙니다. 이러한 측정지표에서 오랜 기간동안 연구된 SMT에 비해서 짧은 시간동안 소수의 연구 그룹에 의해 만들어진 NMT가 더 좋은 성능을 보입니다.
다음 글에서는 Attention의 등장과 Transformer 모델 구조를 알아보도록 하겠습니다.
'강의 & 책 > CS224N' 카테고리의 다른 글
| [CS224N] Language Modeling with LSTM and GRU (0) | 2023.03.04 |
|---|---|
| [CS224N] Language Model, Analysis, Future of NLP (0) | 2023.01.14 |
| [CS224n] T5 and Large Language Models (0) | 2022.04.07 |
| [CS224n] Subword Modeling & Pretraining (0) | 2022.03.18 |
| [CS224n] 어텐션 (Attention) (0) | 2022.03.18 |



