
Notice
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
Tags
- transformer
- CS224N
- cv
- VIT
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- 강화학습
- YAI 11기
- 컴퓨터 비전
- CNN
- Faster RCNN
- PytorchZeroToAll
- CS231n
- Googlenet
- rl
- RCNN
- cl
- Perception 강의
- Fast RCNN
- 자연어처리
- nerf
- YAI 9기
- GaN
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- YAI 10기
- NLP
- 컴퓨터비전
- YAI
- 3D
- 연세대학교 인공지능학회
- YAI 8기
Archives
- Today
- Total
연세대 인공지능학회 YAI
[CS224n] T5 and Large Language Models 본문
Lecture-14: T5 and Large Language Models
** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다.
T5 Ideas
- Which transfer learning methods work best, and what happens when we scale them up? → T5
- What about non-English pre-trained models? → modify T5 for multilingual model
- How much knowledge does the model learn during pre-training?
- Does the model memorize data during pre-training?
- Which Transformer modifications work best?
Transfer learning
- SQuAD Exact Match score (validation set)

- Transfer learning의 역사
- 더 큰 model size, 더 좋은 optimizer, ...을 사용한 pre-train model이 더 좋은 성능을 내는가?
T5 (Text-to-Text Transfer Transformer)
- 여러 task에 대해 동일한 objective/decoding을 사용하여 학습할 수 있음 (동일한 모델을 사용하여 다양한 task를 처리할 수 있음)STSB task에서도 예측할 값 (3.8)을 string으로 인식하여 학습

- vanilla transformer을 기반 (machine translation에서 하나의 sentence를 input으로 하였을 때 다른 sentence를 predict하는 형식 참고)

- 몇 개의 token을 랜덤하게 제거하고 < x >, < y > 등의 토큰(span)으로 대체
- BERT에서 pretraining하는 것과 유사하게, 몇 개의 token을 가리고 그들을 예측하는 방식으로 진행
- 그러나 encoder만 사용한 버트와 달리 transformer 기반
- 단어 하나하나 마스킹하는 게 아니라 span 단위로 masking
- 위치가 중요해서 x y z처럼 유니크한 마스크
- 결과는 < x >는 무엇, < y >는 무엇의 형태로 나옴 (spanBERT 차용)

- BERT에서 pretraining하는 것과 유사하게, 몇 개의 token을 가리고 그들을 예측하는 방식으로 진행
- T5 baselinesC4 dataset: Colossal clean crawled corpus - 오픈소스 사전 훈련 데이터셋
- pretrain
- BERT-base 사이즈의 인코더와 디코더를 사용 → BERT 파라미터의 두 배
- denoising: masking
- finetune individually and separately
- classification, summarizing, NL understanding, translation, ... tasks
- evaluate: checkpoint마다 evaluation; within method를 평가하기 위해no pretraining: 각 task에 맞게 각각 train
- translation task는 big task이므로 pretrain의 효과가 크지 않음

- pretrain

Disclaimer
- Encoder-decoder architecture - span prediction objective - C4 dataset - Multi-task pre-training - Bigger models trained longer에 대한 실험 결과 (hyperparameter를 고정해가면서 찾음)
- attention mask patterns (fully visible: BERT; causal: LM; causal w prefix: 최소한 이만큼은 보여주겠다)

- architecture: input output 확인
- enc-dec, shared: encoder와 decoder이 shared parameter을 가짐
- enc-dec, 6 layers: baseline 모델이 가진 layer 수의 절반으로 구성
- language model: left→right
- prefix LM: masking을 통해 학습 like GPT

- optimal hyperparameterbaseline을 10회 정도 돌린 신뢰범위에 대해, 다른 모델들이 그 범위 안에 들어가면 볼드체로 표시
- BERT-style: 마스킹 하는 방식이 버트와 같은 것이지 아웃풋이 버트와 같은 것은 아님 (버트는 마스킹된 단어를 예측 seq2seq은 문장을 예측)

- dataset에 따른 평가
- C4: Wikipedia의 텍스트는 품질은 우수하지만 스타일이 균일, Common Crawl 웹 스크랩은 데이터 사이즈가 크고 다양하지만 품질은 매우 낮음 → Wikipedia보다 2배 큰 Common Crawl 버전인 C4 (Colossal Clean Crawled Corpus)를 개발 (클리닝: 중복 제거, 불완전한 문장 폐기, 불쾌하거나 noisy한 내용 제거), 크기를 늘려 사전 훈련 중 과적합(overfitting) 감소.
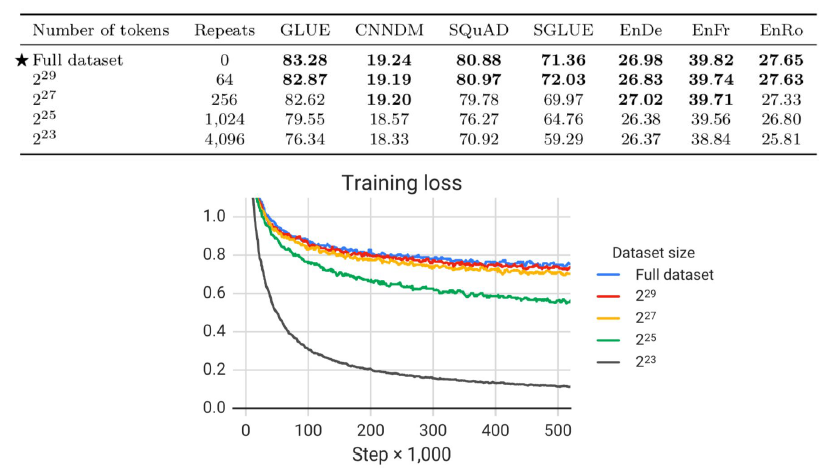
- specialized 데이터셋(e.g. Wikipedia + Book corpus)는 SuperGLUE에 좋은 성능 (encyclopedic article/novel에 대한 understanding task)
- Wikipedica는 정제된 corpus이므로 이를 통해 학습할 경우CoLA에서 좋은 성능을 보이지 못함
- tokens 수에 따른 성능
- overfitting이 일어나지 않도록 적절히 큰 데이터를 사용해야 함

- multi-task training (“TASK: 결과”의 형식을 예측)
- task 별로 데이터도 다르고 난이도도 다르기때문에 multitask 러닝에서 태스크별로 얼마의 데이터를 뽑을지가 중요

- pretraining 데이터가 너무 크므로 task별로 finetuning 시 얼마만큼의 데이터를 사용해야 하는지 → temperature이 커질수록 uniform하게 뽑음

- 영어 데이터만 사용하여 pretraining한 결과
- https://github.com/google-research/text-to-text-transfer-transformer
- task prefix를 input에 포함하지 않으면 unsupervised learning을 수행
- 2,048 token을 가진 문장 등 long sentence에도 적용 가능
what about all of the other languages?
- multilingual T5 (mT5)

- 101개 언어에 대한 데이터를 71개의 common crawl dumps에서 구성
- 영어가 가장 많고 yoruba 데이터가 가장 적음
- temperature를 어덯게 설정하는지에 따라 성능이 달라짐

How much knowledge does a language model pick up during pre-training?
- Reading comprehension: 하나의 질문, 하나의 passage
- Open-Domain Question Answering: 하나의 질문, 여러 passages
- Closed-Book Question Answering: 하나의 질문, no passage (pre-training 정보만 활용)
- 작동 방식
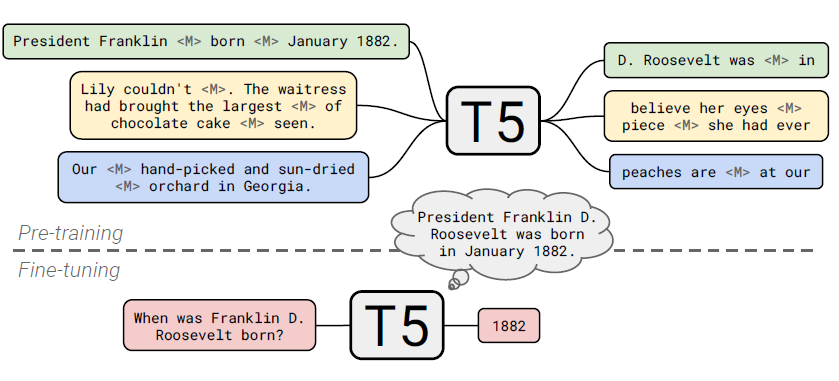
- unsupervised (not multi-task)로 pretraining한 모델(T5.1.1)의 성능

- salient span masking: entity name을 masking하여 학습하도록

Do large language models memorize their training data?
- private data 등의 정보를 memorize하지 않도록 하기 위해?
- GPT-2를 사용, memorize 했는지 여부를 확인
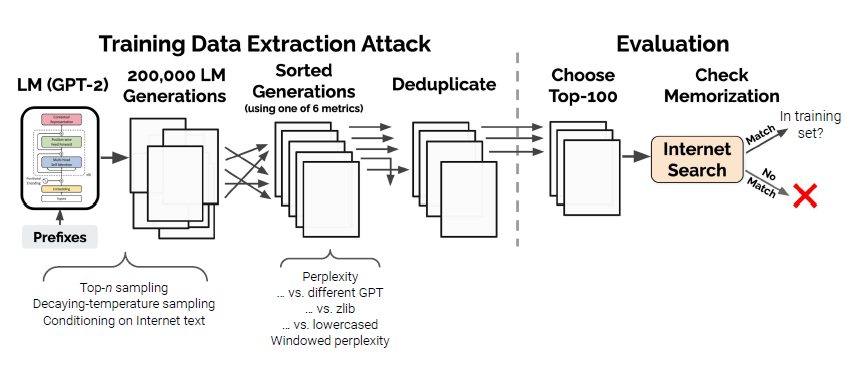
- perplexity를 비교해보면, GPT-2는 zlib보다 더 잘 기억하는 것으로 나타남
- 또한 사이즈가 큰 모델이 더 잘 기억

Can we close the gap between large and small models by improving the Transformer architecture?
- larger model: large energy, computational complexity
- Transformer 기존 구조를 조금씩 수정한 architecture이 등장
- T5를 활용하여, 동일한 환경에서 위 구조들을 비교함pretrainingtask


- remaining questions
- Is our codebase unusual? Transformer을 제안한 사람이 만든 코드라 문제없을 것 같음
- Are our tasks non-standard? pre-training 이후 fine-tuning을 진행하는 것은 일반적
- Do we need to tune hyperparameters? hyperparameter에 대한 여러 번의 실험을 통해 basline보다 높지 않은 성능이 나옴을 확인
- Did we implement the modifications correctly? 구현을 제대로 했는지에 대해 각 authors에 이메일을 보내서 확인함
- Do Transformer modifications not “transfer”? hyperparameter을 수정하지 않고 다양한 task에 적용해본 후 안정적인지 확인. (nonlinearity를 추가하는 등 hyperparameter의 변화가 없는 경우 likely to transfer)
The importance of knowledge-aware language models
- prediction을 잘 진행하는 것과 factually correct한지는 다른 의미 (다음과 같은 이유들로 이러한 문제 발생 가능)
- Unseen facts: 어떤 fact들은 training corpora에 존재하지 않음
- Rare facts: 모델이 해당 fact를 memorize할 만큼 많은 양의 example이 존재하지 않음
- Model sensitivity: fact를 마주했더라도 의미적으로 phrasing에 sensitive하게 반응 (e.g. x was made in y ≠ x was created in y)
- → LM이 가지는 challenge 중 하나는 inability to reliably recall knowledge
- 언어모델을 통해 pretrain된 representation은 지식을 활용하는 다운스트림 tasks에 도움될 수 있음
- 두 entities에 대한 정보를 가지고 있으면 관계를 extract할 때 도움이 됨
- can LMs ultimately replace traditional knowledge bases?
- LM이 recalling facts를 잘하는 경우 LM을 통해 사실에 대한 지식 기반을 query할 수 잇음
Knowledge bases
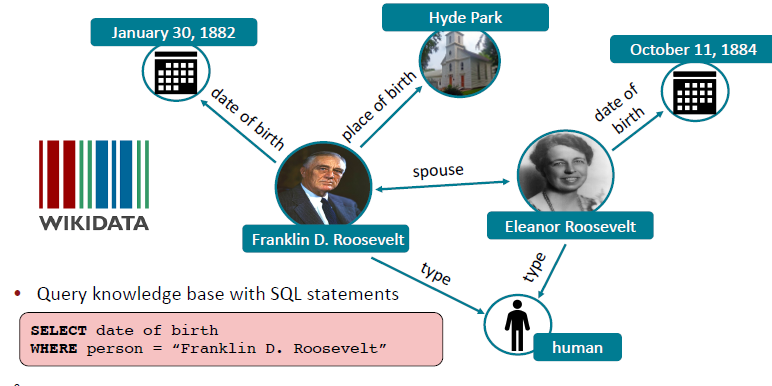
- 위와 같은 형식의 knowledge base를 LM로 query할 수 있음
- 전통적인 KBs는 extract하기 위해 사람의 수동적인 annotation이나 복잡한 NLP pipeline을 필요로 함 → LM은 unstructured/unlabeled text에 대해 사전 학습되어 있어 효율적
- LM은 더 flexible한 query를 사용할 수 있음
- 그러나 LM을 query에 사용하기에는 다음과 같은 challenges 존재
- 1) interpret이 어려움
- 2) trust하기 어려움 (실제로 아는 것인지 모름, incorrect한 정보를 제시할 수도)
- 3) modify하기 어려움 (원래 memorize하고 있는 지식을 remove하거나 update하기 어려움)
Techniques to add knowledge to LMs
1. Add pretrained entity embeddings
- entities에 대한 notion이 따로 없음 + 하나의 단어(e.g. USA, United States of America, ..)를 여러 가지로 표현할 수 있음
- 따라서 하나의 entity에 대해 하나의 embedding으로 표현해야 함 → entity linking을 통해 해결
- Entity linking
- 보통은 identifiers를 사용하지만, ambiguous matching을 할 때 같은 text가 다른 entity를 의미할 수 있음 (candidates가 여러 개)
- context에 맞게 entity를 link해주어야 함
- entity embedding을 위해 다음과 같은 방법들을 사용할 수 있음
- KG embedding (e.g. TransE)
- word-entity co-occurence (e.g. Wikepedia2Vec)
- Transformer encodings of entity description (e.g. BLINK)
- 다른 embedding space에 있는 entity embeddings를 어떻게 통합할 것인가?
- fusion layer을 사용하여 context와 entity information을 combine → single hidden representationw_j: Washington; e_k: George Washington (aligned embedding)


ERNIE: Enhanced Language Representation with Informative Entities [Zhang et al., ACL 2019]
- 1) text encoder: sentence의 단어들에 대한 multi-layer bidirectional Transformer (BERT 등 모델)
- 2) Knowledge encoder: 아래와 같은 layer로 구성된 blocks로 이루어짐entity가 없는 경우 e는 사용하지 않음

- 전체적인 구조
- text에서 얻은 정보와 knowledge에서 얻은 정보를 잘 aggregate
- 텍스트의 ner정보와 kg의 entity를 align
- TransE를 사용해서 entity embedding
- entity embedding을 버트 등 기존 모델에 적절히 통합
- BERT training + entity를 위한 objective 추가
- 이를 위해 individual vector space fusion
- knowledgeable language representation=entity repre + token repre

- (b)에서 bob dylan과 Bob Dylan이 하나의 entity로 통합됨
- text에서 얻은 정보와 knowledge에서 얻은 정보를 잘 aggregate
- Pretraining
- BERT에서처럼 1) masked language model, 2) next sentence prediction
- Knowledge pretraining task (dEA): 일부 token-entity alignments를 임의로 masking하고 시스템은 aligned token에 대한 모든 상응하는 entity를 찾는 것을 목표로 함 (token과 entity를 엮음)
: auto-encoder를 denoising하는 것과 비슷하기에 이를 denoising entity auto-encoder(dEA) 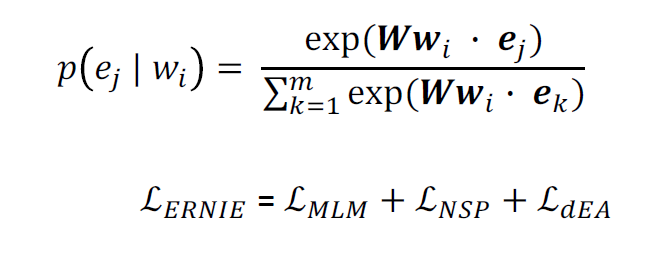
- Strengths
- entity와 context를 fusion layers와 knowledge pretraining task를 사용하여 통합
- knowledge-driven tasks에 대한 성능 향상
- Challenges
- downstream task에 대해서도 entity가 annotated된 text data를 필요로 함 (For instance, “Bob Dylan wrote Blowin’ in the Wind” needs entities pre-linked to input entities into ERNIE)
- LM에서 further pretraining을 필요로 함
Python, Machine & Deep Learning
Jointly learn to link entities with KnowBERT [Peters et al., EMNLP 2019]
- pretrain an integrated entity linker (EL) as an extension to BERT
- Entity linker: 문맥이 주어졌을 때 entities에 대한 점수를 부여
- 링크 목록 C는 잠재적인 mention-span의 시작 끝과, KG의 엔티티 후보인 Mm으로 이루어져 있다. 경우에 따라 잠재적인 후보들을 과도하게 생성하고, 각 후보 목록에 특수한 NULL 엔티티를 추가하면 링커가 실제 링크와 오 탐지 후보를 구별할 수 있다. 이 작업에서 엔티티 후보 선택기는 고정되어 있지만, 후보 출력을 명확하게 하기 위해 학습된 컨텍스트 종속 엔티티 링커(dependent entity linker)로 출력이 전달된다.
- C=<(startm,endm),(em,1,...,em,Mm)>,m∈1...C,ek∈1...K

- entity annotations가 불필요 (후보)
- EL을 학습함으로써 knowledge를 더 잘 encoding할 수 있게 됨 (ERNIE보다 dowstream tasks에서 더 좋은 성능)
- dEA는 EL보다 simpler한 방식 (하나의 sentence만 사용하는 것이 아니라 더 많은 정보를 기반으로 link)
Knowledge Enhanced Contextual Word Representations
2. Use an external memory
- modify KB를 위해서는 다시 training을 해야 함
- Are there more direct ways than pretrained entity embeddings to provide the model factual knowledge?

- → learning parameter와 independent하게 외부 정보들을 사용
- 장점
- factual knowledge를 inject/update하여 retraining 과정이 필요 없음
- 설명 가능성
Barack's Wife Hillary: Using Knowledge-Graphs for Fact-Aware Language Modeling (KGLM) [Logan et al., ACL 2019]
- Transformer이 아닌 LSTM으로 predict next wordentity에 대한 정보도 predict

- “local” KG를 생성: subset of the full KG with only entities relevant to the sequence (문장 내에 있는 entity에 대한 정보만 전체 KG에서 가져옴)
- softmax를 계산할 때 전체 KG를 사용하기보다 local KG에서 다음 단어를 예측하는 것이 더 큰 시그널을 줄 수 있음
- single-hop에 대한 정보들만 있는 것으로 확인됨

- When should the LM use the local KG to predict the next word?
- LSTM으로 다음 word가 related entity인지(in the local KG), new entity인지(not in the local KG), not an entity인지를 분류

- How does the LM predict the next entity and word in each case?
- top scoring parent entity, top scoring relation을 찾은 후 KG triple에 기반하여 다음 entity를 예측위의 예시를 참고하여 entity aliases를 설명하자면, Nintendo, Nintendo company, .. 등 nintendo의 다른 명칭들을 포함


- 전체 구조

- fact completion task에서 GPT-2와 AWD-LSTM보다 더 좋은 성능을 보임
- GPT-2보다 더 specific한 토큰을 예측함 (GPT-2는 generic한 토큰을 예측)
- local knowledge graph를 수정/업데이트 할 경우 prediction 값도 directly change
Nearest Neighbor Language Models (kNN-LM)
- learning similarities between text sequences is easier than predicting the next word
- Nearest neighbors는 LM 학습데이터에 있는 text 데이터에 대해 pre-trained LM embedding space 상의 거리에 따라 계산됨
- nearest neighbor datastore에 있는 text sequences에 대한 모든 representations를 저장하는 식
- 가장 유사한 k개의 sequences를 datastore에서 찾음
- k개 sequences에 대한 corresponding values (예를 들어 next word)를 찾음
- keys: representations of the context → nearest neighbor 계산
- values: next words → copy over values
- kNN prob와 LM prob를 통합하여 prediction

- 전체 구조 (Example: Shakespeare’s play ___)
- kNN-LM은 pre-trained LM에 nearest neighbors retrieval mechanism을 더한 형태로서 추가적인 학습은 하지 않음training context를 represent하고 (k_i), test context를 represent해서 생성한 query와 거리가 가까운 k개의 이웃에 대해 softmax를 통해 무엇이 나올지 classify

- 각 k neighbor에 많이 등장한 단어들은 더 높은 점수를 부여(aggregate)
- interpolation: knn과 LM의 distribution을 interpolate하여 통합
- 모든 단어에 대해 next word를 계산해야하기 때문에 계산량이 많을 것 → quantization을 통해 less expensive하게 하고자 하지만 큰 데이터셋에 대해서는 여전히 expensive
- domain adaptation에 좋은 성능: 새로운 도메인에 대한 nearest neighbor datastore을 생성하여 encode all representations 후 LM에 knn prob을 계산하기만 하면 됨
- Generalization through Memorization: Nearest Neighbor Language Models (ICLR 2020)
3. Modify the training data
- Can knowledge also be incorporated implicitly through the unstructured text?
- Mask or corrupt the data to introduce additional training tasks that require factual knowledge.

- 장점
- 추가적인 memory나 계산이 필요하지 않음 (e.g. datastore, ...)
- 구조의 변경이 필요하지 않음 (e.g. BERT 등 기존 모델을 활용 가능)
Pretrained Encyclopedia: Weakly Supervised Knowledge-
Pretrained Language Model (WKLM) [Xiong et al., ICLR 2020]
- train the model to distinguish between true and false knowledge
- mentions를 same type을 가진 다른 entities로 대체하여 negative knowledge statements를 생성
- 모델은 entity가 대체된 것인지 아닌지를 평가하고, type-constraint는 언어적으로 말이 되는 문장인지를 평가
- mentions를 same type을 가진 다른 entities로 대체하여 negative knowledge statements를 생성
- 전체 구조replace한 지식이 true인지 false인지도 평가L_entRep: binary classification을 하듯이; entRep의 경우 여러 단어들로 구성된 entity일 수도 있음


- fact completion task에서 BERT, GPT-2보다 좋은 성능을 보였으며, downstream tasks에서는 ERNIE보다 좋은 성능
- MLM loss는 downstream task 성능에서 중요
- WKLM은 MLM loss만 사용하는 것보다 좋은 성능
ERNIE: Enhanced Representation through Knowledge Integration [Sun et al., arXiv 2019]
- Can we encourage the LM to learn factual knowledge by being clever about masking?
- ERNIE (앞에서 언급한 ERNIE와는 다른 모델): phrase(multiple words)-level과 entity-level의 masking (Chinese NLP tasks)BERT는 각 단어를 일정 확률로 masking하고 이를 예측하지만, ERNIE는 단어뿐 아니라 독립체(entity), 구(phrase) 전체를 하나의 unit으로 취급하여 masking

Python, Machine & Deep Learning
How Much Knowledge Can You Pack Into the Parameters of a Language Model?, Roberts et al., EMNLP 2020
- “salient span masking” (Guu et al., ICML 2020) 를 사용하여 salient spans (i.e. named entities and dates)을 마스킹
- 사전 학습된 NER 모델을 사용해서 named entity로 판단되는 span 부분을 다 마스킹하는 등
- QA task에서 T5의 성능을 향상시킴

Recap

Evaluating knowledge in LMs
LAnguage Model Analysis (LAMA) Probe [Petroni et al., EMNLP 2019]
- 얼마나 많은 relational (commonsense, factual) knowledge가 해당 LM에 encode되어 있는지
- wikidata에 저장된 entity간의 관계, ConceptNet의 개념간 상식 관계 및 SQuAD의 자연어 질문에 대답하는데 필요한 지식등 다양한 지식 유형 테스트.
- 사람이 만든 cloze statements를 사용하여 모델이 missing token을 얼마나 잘 예측하는지 평가
- KG triples와 QA pairs를 통해 cloze sentences를 생성
- i.e. The theory of relativity was developed by [MASK]. The native language of Mammootty is [MASK]. Ravens can [MASK]. You are likely to find a overflow in a [MASK].
- supervised relation extraction (RE)과 QA systems에 대해 LM 비교
- existing pretrained LMs에 해당 지식이 존재하는지 평가 (this means they may have different pretraining corpora!)1-to-1: unique 값, N-to-M: e.g. 하나의 class에 여러 학생이 존재 등
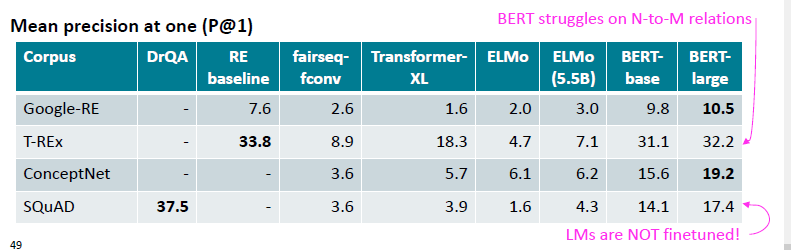
- limitations
- 결과에 대해 모델이 왜 그렇게 판단했는지 알기 어려움
- BERT-large의 경우 cloze sentence를 “이해”하기 보다는 co-occurence pattern을 기억한 것으로 생각됨
- LM은 subject와 object에 대한 표면적인(surface) 유사도만을 identify할 수 있는 것으로 생각됨
- phrasing에 sensitive하게 반응
- 각 relation에 대해 하나의 defined template만 가지고 있음
- 이는 제시된 결과가 knowledge의 lower bound임을 의미
- 결과에 대해 모델이 왜 그렇게 판단했는지 알기 어려움
A More Challenging Probe: LAMA-UnHelpful Names (LAMA-UHN) [Poerner et al., EMNLP 2020]
- Remove the examples from LAMA that can be answered without relational knowledge
- BERT는 surface form만을 사용하여 prediction을 진행
- 따라서 실제로 factual knowledge가 존재하지 않더라도 correct prediction을 했다고 판단할 수 있음
- E-BERT는 기본 BERT보다 좋은 성능을 보임
Developing better prompts to query knowledge in LMs [Jiang et al., TACL 2020]
- query와 다른 corpus를 통해 pretraining을 하기 때문에 LAMA에서 좋지 않은 성능을 보일 수 있다. (실제로는 may know the fact; sentence structure 등이 달라서)

→ Generate more LAMA prompts by mining templates from Wikipedia and generating paraphrased prompts by using back-translation + Ensemble prompts to increase diversity of contexts that fact can be seen in
Knowledge-driven downstream tasks
- knowledge-enhanced LM이 지식을 downstream task에 얼마나 잘 전달하는지
- Unlike probes, this evaluation usually requires finetuning the LM on downstream tasks, like evaluating BERT on GLUE tasks
- Relation extraction, Entity typing에서 성능 향상을 확인
'강의 & 책 > CS224N' 카테고리의 다른 글
| [CS224N] Language Modeling with LSTM and GRU (0) | 2023.03.04 |
|---|---|
| [CS224N] Language Model, Analysis, Future of NLP (0) | 2023.01.14 |
| [CS224n] Subword Modeling & Pretraining (0) | 2022.03.18 |
| [CS224n] 어텐션 (Attention) (0) | 2022.03.18 |
| [CS224n] 기계 번역 (Machine Translation) (0) | 2022.03.10 |
'강의 & 책/CS224N' Related Articles
more



