
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- 자연어처리
- GaN
- NLP
- YAI 9기
- YAI 10기
- 컴퓨터비전
- 연세대학교 인공지능학회
- 컴퓨터 비전
- Fast RCNN
- rl
- nerf
- Googlenet
- YAI 8기
- CNN
- Faster RCNN
- cv
- 강화학습
- Perception 강의
- cl
- YAI
- CS224N
- YAI 11기
- 3D
- VIT
- transformer
- RCNN
- CS231n
- PytorchZeroToAll
- Today
- Total
연세대 인공지능학회 YAI
[CS224n] Subword Modeling & Pretraining 본문
Subword Modeling & Pretraining
** YAI 9기 전은지님이 자연어강의팀에서 작성한 글입니다.
1. Introduction
언어 모델링에서 중요한 부분 중 하나인 단어를 어떻게 표현할 것인가를 살펴보겠습니다. 만약 단어의 개수가 유한하다는 가정, 즉 finite vocabulary assumptions를 기반으로 할 경우에는 단어의 변환, 오타, 새로운 단어 등이 모두 unknown words로 동일하게 매핑되게 됩니다. 따라서 이러한 word structure 혹은 morphology를 다루는 방식이 필요하게 됩니다.
한편, 사전 학습된 대규모의 모델은 자연어 처리에 있어서 거의 표준이 되었고, 그 성능도 매우 뛰어납니다. 이러한 방법론에 대해서도 다뤄보겠습니다.
2. Subword Modeling
위와 같은 문제를 다루기 위해 '단어' 단위보다 작은 parts of words (subword tokens)를 사용하여 학습하게 됩니다. 이때, 가장 많이 사용하는 BPE (Byte-Pair Encoding) 알고리즘에 대해 다루겠습니다.
2-1. Byte-Pair Encoding System
목표는 characters의 sequence를 기반으로 학습하고자 하는 것입니다. 과정은 아래와 같습니다.
- Characters와
end-of-wordsymbol (e.g., sty, ify, ...)로만 이루어진 vocab을 사용 - 가장 많이 등장하는 adjacent characters (characters 묶음)를 vocab의 subword로 추가
- 원하는 vocab size에 도달할 때까지 반복
이러한 방식은 원래 machine translation에 사용되었고, 유사한 방식이 pretrained model로 사용되기도 합니다. 대표적인 것은 WordPiece Tokenizer가 있습니다. 즉, word를 subword 기준으로 vocab mapping을 수행하는 것은 주류가 되었으나, 하나의 단어가 너무 많은 subwords로 쪼개질 수 있다는 단점이 존재합니다.
3. Pretraining
3-1. Pretraining Word Embeddings

word2vec 등 distributional semantics를 활용한 모델에서는 의미적으로 다른 단어들을 구별할 수 없습니다. 예를 들어, 배와 배, 눈과 눈이 그러합니다. LSTM이나 Transformer 등을 통해 pretrained word embeddings을 학습한다면, 주변의 문맥까지도 학습하게 되어 그 의미를 구별할 수 있게 됩니다. 그러나 단점은 downstream task에 적합한 데이터가 불충분하거나, 시작할 때의 parameter가 랜덤하게 초기화된다는 점이 있습니다.
3-2. Pretraining Whole Models
전체 모델을 사전 학습하는 방법은 초기 파라미터들이 pretraining을 통해 초기화됩니다. Pretraining은 일반적으로 인풋에서 일정 부분을 가리고, 그 부분을 예측하도록 학습됩니다. 이러한 방식을 Masked Language Model (MLM)이라고 합니다. 이는 아래의 것들을 구축하는 데 매우 효과적인 방식입니다.
- 언어 표현
- 파라미터 초기화
- 확률 분포로 표현
이러한 방식을 이용해서 단어 간 관계, sentiment 등을 나타낼 수 있습니다.
3-3. Pretrianing and Finetuning
Pretraning은 모델의 parameter를 초기화하는 것을 의미합니다. 많은 양의 텍스트를 이용해서 매우 일반적인 언어 특징들을 학습하게 됩니다. 이후 Finetuning 단계에서는 레이블이 존재하는 데이터가 많이 존재하지 않더라도, 태스크에 적절하게 파라미터를 세부 조정할 수 있게 됩니다.
이렇게 pretraining 하는 방식은 아래와 같이 도식화할 수 있습니다.
3-4. Decoders
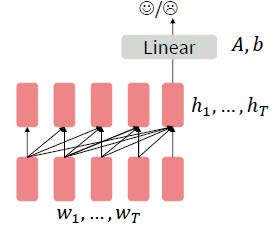
디코더는 단방향으로 예측하기 때문에 미래에 등장하는 단어에 대한 condition(조건)이 존재하지 않습니다. 아래에 보이는 task에서는 linear layer 전까지 pretrained를 사용하게 되고, A와 b는 랜덤하게 초기화됩니다. 이러한 것은 language model의 역할로 사용되기 보다는 파라미터 초기화를 사용한다고 볼 수 있습니다.
혹은 domain-specific task를 위해 finetuning을 할 수도 있습니다. 이는 마지막 layer까지 pretrained 모델을 사용하게 됩니다. 대표적인 예로는 GPT, GPT-가 있습니다. 매우 큰 규모의 feed forward layers (dimension 768 (hidden states) -> 3072 (feed-forward) -> 768 (hidden states))를 갖습니다. 또한, BookCorpus를 사용하여 long-distance dependencies를 학습하였습니다.
3-5. Encoders
Decoder와 달리 encoder는 양방향으로 예측하나, 미래의 단어에 대한 정보가 있기 때문에 pretrain을 어떻게 하느냐가 쟁점이라고 할 수 있습니다. 따라서, 몇몇 input을 [MASK] token으로 대체하여 해당 단어를 예측하게 됩니다. BERT의 경우에는 랜덤한 15%의 subword tokens를 예측하도록 학습됩니다. 이때, 실제로는 [MASK] token 외의 다른 토큰들에 대해서도 잘 학습할 수 있도록 다음과 같이 변경하여 수행했습니다.
- Replace input word with
[MASK]80% of the time - Replace input word with a random token 10% of the time
- Leave input word unchanged 10% of the time (but still predict it!)
3-6. Encoder-Decoder
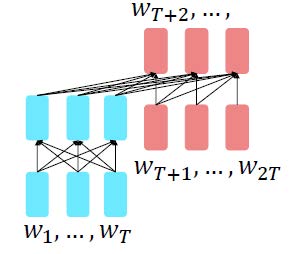
Encoder 부분은 양방향의(bidirectional) 문맥으로부터 성능을 끌어올릴 수 있고, decoder 부분은 언어 모델링을 통해 전체 모델을 훈련하는 데에 사용됩니다. Encoder-decoder가 서로 다른 부분을 갖도록, encoder와 decoder가 서로 정답을 알려주면서 prediction을 수행합니다. T5와 같은 모델은 그 파라미터로부터 지식을 얻어서 매우 다양한 범위의 답변을 얻을 수 있도록 finetuned 될 수 있습니다.
3-7. GPT-3
매우 큰 규모의 언어 모델로, gradient가 흐르는 과정이 없이도 어떠한 "학습"이 일어나기도 하는데, 이를 zero-shot, few-shot등으로 불립니다.
'강의 & 책 > CS224N' 카테고리의 다른 글
| [CS224N] Language Modeling with LSTM and GRU (0) | 2023.03.04 |
|---|---|
| [CS224N] Language Model, Analysis, Future of NLP (0) | 2023.01.14 |
| [CS224n] T5 and Large Language Models (0) | 2022.04.07 |
| [CS224n] 어텐션 (Attention) (0) | 2022.03.18 |
| [CS224n] 기계 번역 (Machine Translation) (0) | 2022.03.10 |



