
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- YAI
- nerf
- 자연어처리
- GaN
- PytorchZeroToAll
- YAI 9기
- Perception 강의
- YAI 11기
- 연세대학교 인공지능학회
- 강화학습
- Faster RCNN
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- Fast RCNN
- CNN
- YAI 8기
- CS231n
- rl
- 컴퓨터 비전
- 컴퓨터비전
- transformer
- cv
- RCNN
- YAI 10기
- NLP
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- Googlenet
- 3D
- CS224N
- VIT
- cl
- Today
- Total
연세대 인공지능학회 YAI
[CS224N] Language Model, Analysis, Future of NLP 본문
CS224N Lecture 15~18
* 10기 김준완님이 자연어 강의 팀에서 작성하신 리뷰입니다.
Language Model
Language Model은 Masked LM과, Standard LM 두가지로 나눌 수 있는데, 전자는 BERT류의 Deonising Auto Encoding이고, 후자는 기존의 조건부 확률 기반으로 다음에 올 단어를 예측하는 Auto Regressive 한 모델이다.

이런 예측된 값들은 make sense하지만 항상 factually correct하진 않다. 그 이유는 unseen facts, rare facts, model sensitivity때문이라고 할 수 있다. 여기서 sensitivity는 문맥상 같은의미의 문장이라도 모델은 사용된 단어가 다르면 다른 문장으로 인식할 수도 있기 때문에 학습이 제대로 진행되지 않을 수 있다.
따라서 factually correct한 정보를 담기 위해서는 두가지 개선 방법이 있다. 하나는 traditional한 knowledge base방법으로 manual annotation과, 모델이 structure를 이해할 수 있도록 처리해주는 complex NLP pipeline이 필요하다는 문제점이 있다. 최근의 방법은 knowledge base를 사용하지 않고 Query LM 자체를 knowledge base로 취급하여 LM 자체에 많은 정보를 학습하여 사용하는 방법이 있다. (Like T5) 그런데 이런 방법을 사용하는 경우 더 flexible하다는 장점이 있지만 학습된 모델이 너무 방대하게 학습되어있기 떄문에 어ㄷ디서 정보를 가져오는지 파악하기 어렵고, 이를 변경하기도 어렵다.
각자 장단점이 있는 만큼 LM에 어떻게 Knowlegde를 주입할 것인지에 대한 세부적인 방법은 아직도 많은 논의가 이루어지고 있다.
ERNIE : Enhanced Language Representation with Informative Entities
Pretrained 된 BERT를 조금 더 확장시킨 모델으로 가지고 있는 사전학습 데이터에 Knowledge Base에서 나온 Entity 데이터에서 가지고 있는 관계를 학습하여 같이 Embedding을 하여 Entity간의 관계를 더 잘 학습하기 위해서 제안되었다. Bob Dylan ~ 이라는 문장에서 기존의 BERT는 Bob Dylan이라는 Entity에 대해 학습하는 것은 없고 단지 Masked LM을 통해 학습할 뿐이라면 해당 모델에서는 위키 등을 통해 밥 딜런에 대한 Entity 관계또한 학습하는 것이라고 생각할 수 있다. 아래의 모델을 확인해보면 Bob이라는 Word Embedding에 밥 딜런이라는 Entity 정보(TransE라는 기존모델을 통해 사전 학습)가 같이 합쳐지는 것을 확인할 수 있는데 이렇게 두 단어가 같은 것을 가리키는 것을 판별하여 합치는 작업이 해당 모델의 주요 목표라고 할 수 있다. 이렇게 BERT에서 나온 단어의 벡터와 Entity의 vector를 잘 합쳐 동일한 벡터 스페이스를 합치게 위해 추가적인 레이어가 존재한다.

ERNIE의 구조를 더 자세히 살펴보면 위와 같이 두개의 Encoder로 구성되어 있는 것을 확인할 수 있다. T Encoder의 경우 BERT의 Encoder과 동일한 기능을 하며 토큰으로 부터 기본적인 lexical, syntactic info를 추출한다. K Encoder의 경우 T 인코더에서 나온 값을 엔티티 정보와 합치는 역할을 한다고 할수 있다. 즉 두가지 벡터 공간으로부터 만들어지는 representation을 united feature space로 통합하는 역할을 한다.
KNN - LM : 의미가 유사한 단어를 KNN을 통해 학습하고, 단어를 예측하는 방법을 통해 학습한다.
KNN prob과 LM prob을 결합하여 사용하는 것으로 기존의 context에서 의미가 유사한 것을 KNN을 통해 탐색하고 이를 같이 사용하는 것이라고 생각할 수 있다.
Knowledge를 inject하는 방법 말고도 학습 과정에서 자연스럽게 knowledge를 학습시키는 방법 또한 존재한다.
WKLM : Weakly Supervised Knowledge Pretrained LM
모델이 true knowledge와 false knowledge를 구분할 수 있도록 학습하는 방법으로, 기존의 데이터를 사용하여 false knowledge를 생성해내는 방법으로 학습을 진행한다.

이렇게 학습을 하는 경우 Loss가 Entity에 대한 정보가 사실인지 아닌지 구분하는 Loss가 필요하므로 다음과 같이 진행된다.

ERNIE by Baidu : entity 정보를 주입하기 위해 별도의 entity 임베딩을 사용하지 않고 masking을 통해 정보를 주입한다.

Masking strategy는 다음과 같이 세가지 방법을 사용하는데 사전 학습과정에서 이런 세가지 방법을 모두 사용할 경우 기존의 LM보다 높은 수준의 representation을 생성한다고 한다.

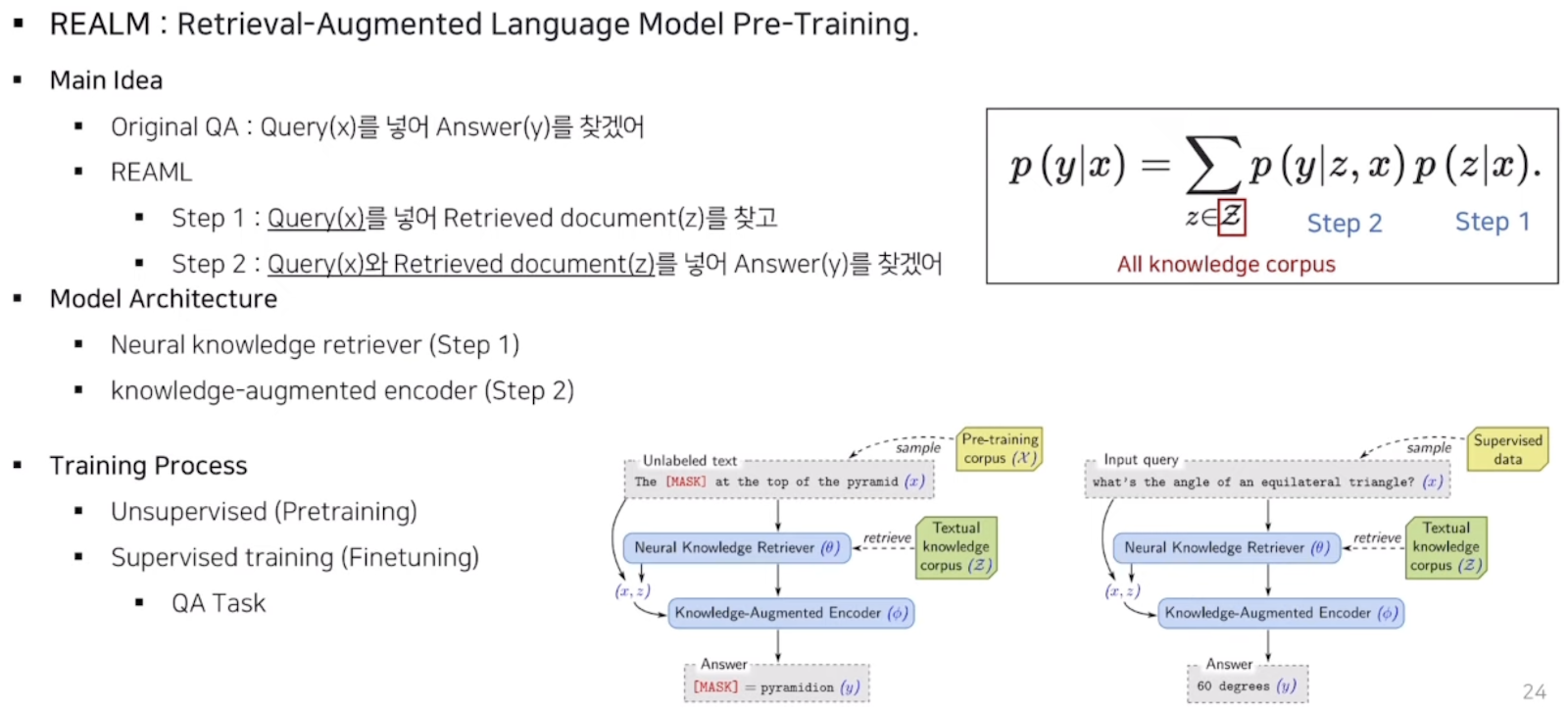
REALM : Retrieval Augmented Language Model Pre-Training
Masking을 잘 수행하여 QA를 잘 하고자 하는 모델로, QA에서 특정 정보를 찾아오는 Retriever가 있고, 그를 바탕으로 정답을 찾는 reader가 있는데 이 둘을 한번에 학습하여 성능을 끌어올리는 방법이다. (기존에 retriever 는 코사인 유사도를 사용해 유사도만 측정하였고, 학습은 따로 하지 않았음)

따라서 해당 모델은 pretraining 과 fine tuning을 모두 수행하고 있다.
기존의 Pretrained LM같은 경우 사전학습 단계에서 큰 말뭉치들로 핛브이 되어 대량의 정보를 포함하고 있으므로 mask 를 예측하는 과정에서 언어를 이해하고 정보를 습득한다. 그러나 이렇게 정보를 저장하는 방식은 굉장히 implicit하고 따라서 네트워크에 어떤 지식이 학습되어있는지 확인할 수가 없으며, 더 많은 지식을 학습시키기 위해서는 더 큰 모델 사이즈가 필요하며 이는 계산비용이 상당하다. 따라서 REALM모델이 유용한데 기존 PLM보다 해석 가능하고 explicit하게 지식을 학습할 수 있다.
Language Model Analysis (LAMA Probe)
동일한 세팅에서 학습하여 어떤 LM이 가장 많은 정보를 포함하는지 비교하는 방법으로 factual and common sense knowledge 에 대한 벤치마크 지표이다.
LAMA-UHN
LAMA에서 relational knowledge 없이 답변 가능한 예제를 모두 제거하여 새로운 데이터를 생성해 entity가 있어야 답변 가능한 데이터만 남긴다. 이 경우 LAMA대비 성능이 저하되는데 BERT가 entity name의 surface form에 크게 의존하는 것을 확인할 수 있다.
Evaluation을 할 때 LM은 Input 형태에 따라 성능에 큰 영향을 미치는데 이는 이전에 언급한 model sensitivity와 연관되는 내용이다.

다른 NN 모델과 마찬가지로 NLP모델 또한 모델 내부에서 정확히 어떤 과정을 거쳐 결과를 도출해내는지 확인하기 쉽지 않다. 즉 적절한 실험들을 진행하여 모델을 분석하는 연구가 진행되어 오고 있다.
Out of domain data : Training에 사용하지 않은 데이터
보통 in domain 데이터에 대해 높은 정확도를 기록하지만 out of domain데이터에 대해서는 정확도가 낮게 나오는 경우가 많고 따라서 out of domain data를 통해 model을 분석할 수 있다.
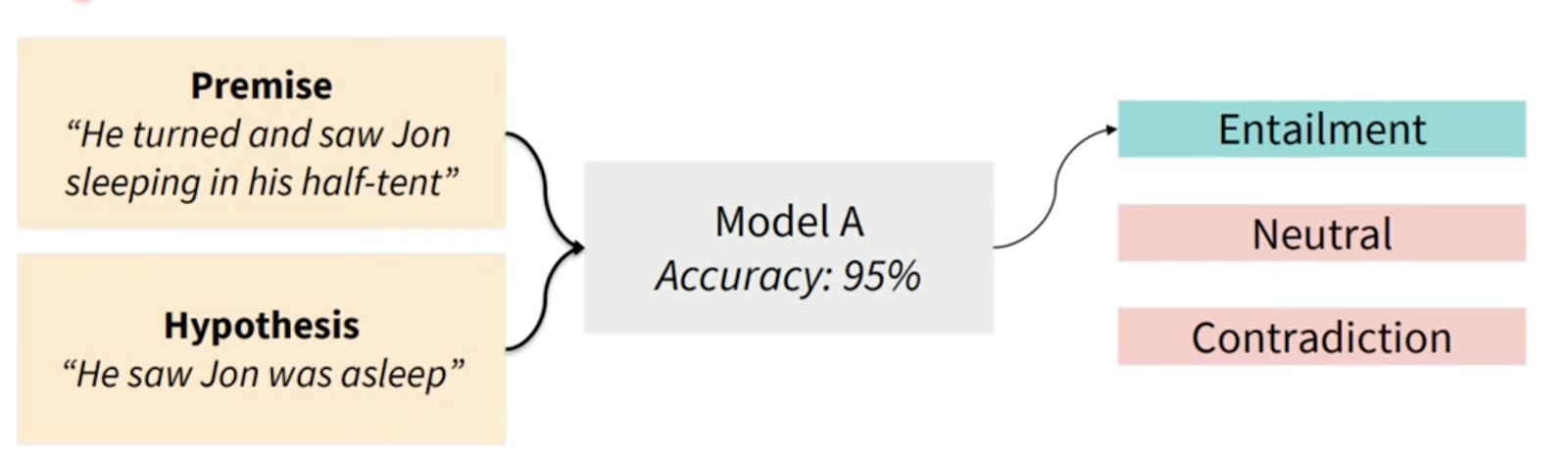
NLI : Premise이 주어졌을 때 다른 Hypothesis에 의미적으로 Entail 되는가?

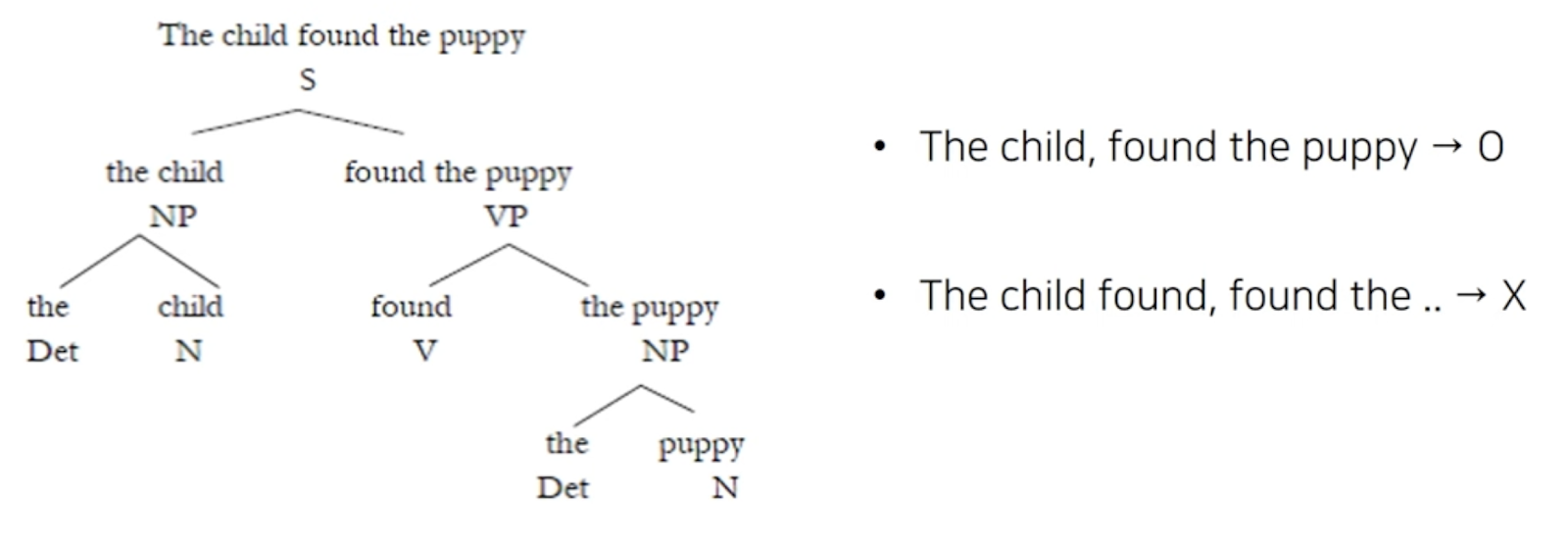
Constituent에 대해 조금 더 설명하면 이는 같은 subtree안에 연속되는 단어일 때 constituent라고 한다.
위와 같은 Syntax Heuristics를 통해 모델의 성능을 확인하면 다음과 같이 syntactic heuristics가 만족되지 않는 경우에 정확도가 매우 낮은 것을 확인할 수 있고 이는 모델이 NLI를 학습하는 것이 아니라 heuristic한 task를 학습해 태스크를 수행하는 것으로 파악할 수 있다.
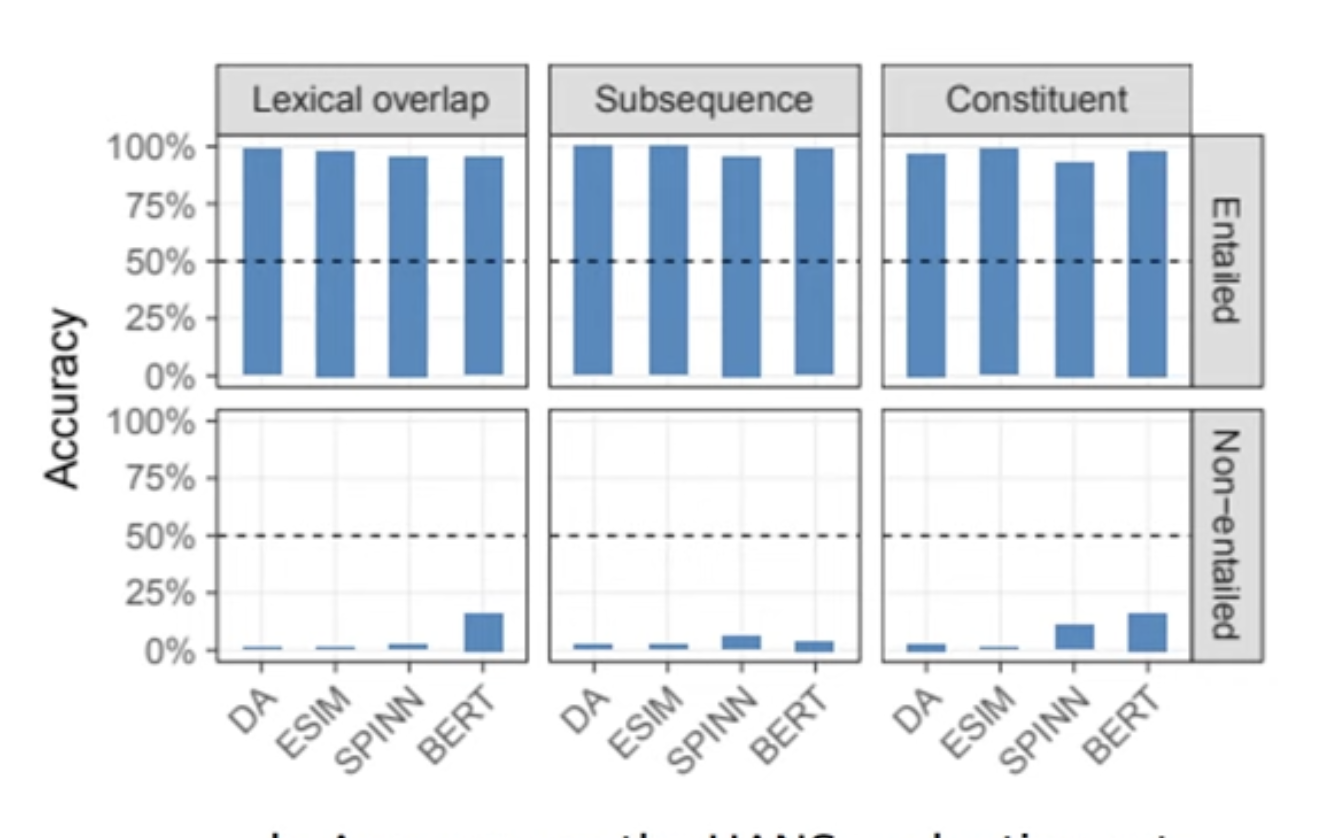
이를 통해 좋은 out of domain dataset을 사용하면 모델 평가를 잘 수행할 수 있음을 간접적으로 확인할 수 있다. 그렇다면 좋은 out of domain data는 어떻게 생성할 수 있는가?
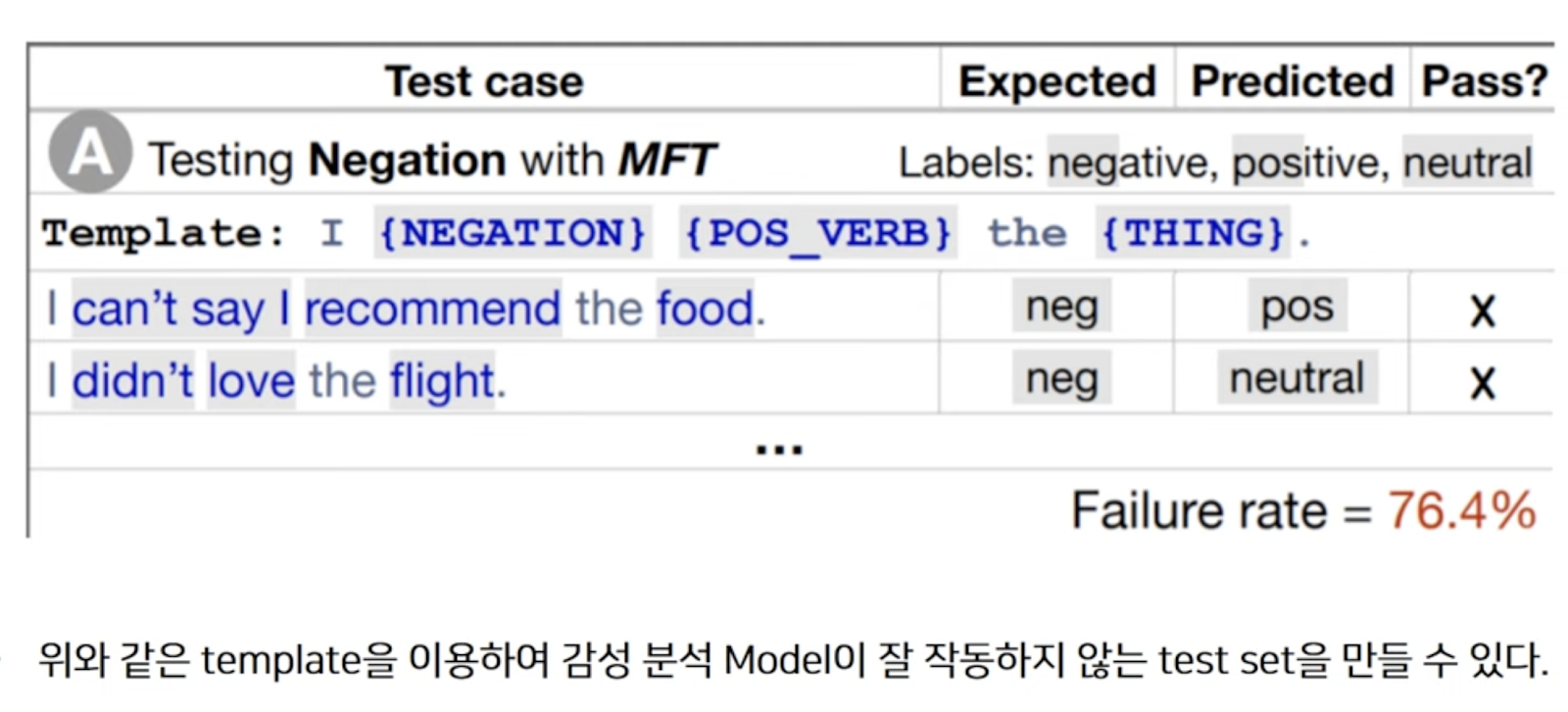
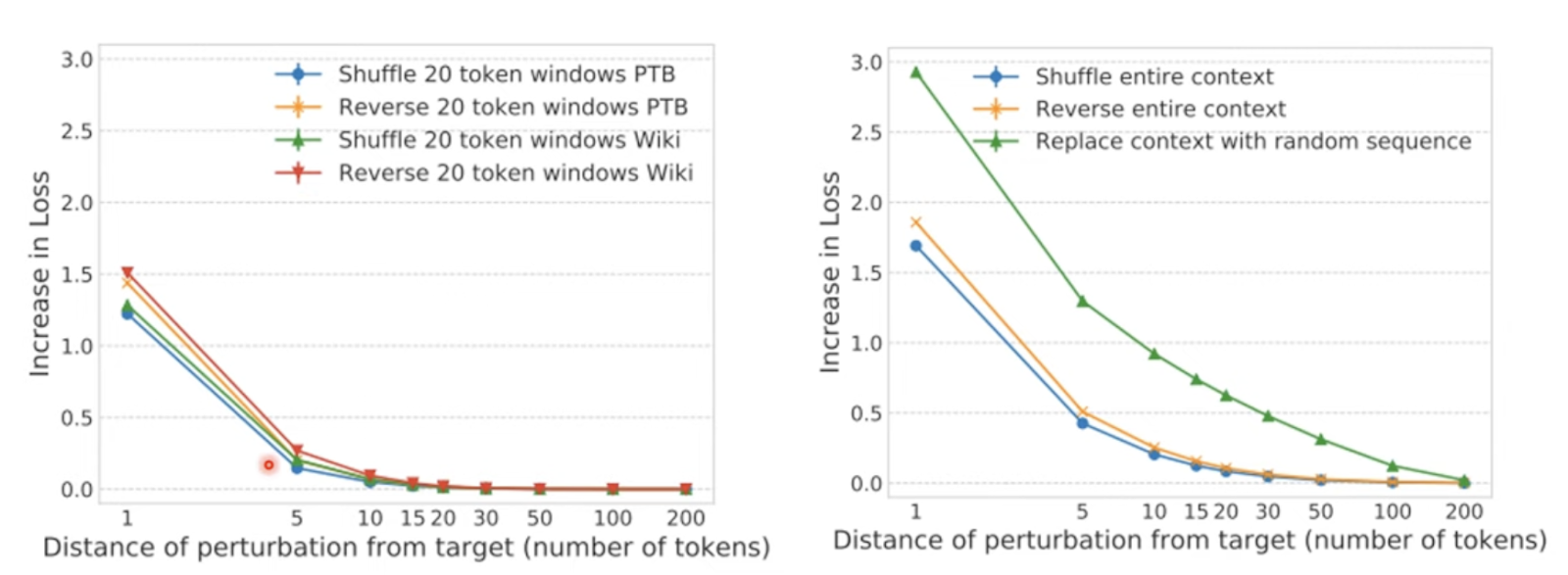
다음은 모델이 실제로 어떤 과정을 거치는지 파악하는 방법으로 LSTM을 사용해 실험을 진행하고 token의 permutation 전 후의 Loss를 비교하여 모델이 Long distance context를 사용하는지 확인하기 위한 실험이다. Replace Case의 경우 Loss가 증가하는 것을 통해 단어의 identity가 중요하다라는 것을 확인할 수 있다고 한다.?
Saliency maps : 모델의 prediction에 input이 얼마나 영향을 미쳤는지 scoring 하는 방법이다.


Gradient가 크다는 것은 score에 영향을 많이 준다는 의미를 반영한 정의이다. 하지만 local optima 같이 기울기가 0인 경우에 중요도를 잘 반영하지 못한다는 문제도 있다.
이런 saliency map을 적용하다 보면 rubbish example이라는 사람은 대답하기 힘들지만 모델의 confidence는 높은 문제를 만들 수 있는데 (가장 중요도가 낮은 word를 beam search를 통해 삭제)

또 다른 방법으로 모델의 예측을 빗나가게 할 수 있는데 paragraph에 답을 바꾸지 않는 애매한 문장을 추가하는 경우 모델이 정답을 예측하지 못하는 경우를 만들 수 있다.


위와 같은 방법들을 사용하여 모델의 예측을 빗나가게 하는 질문을 생성할 수 있다.
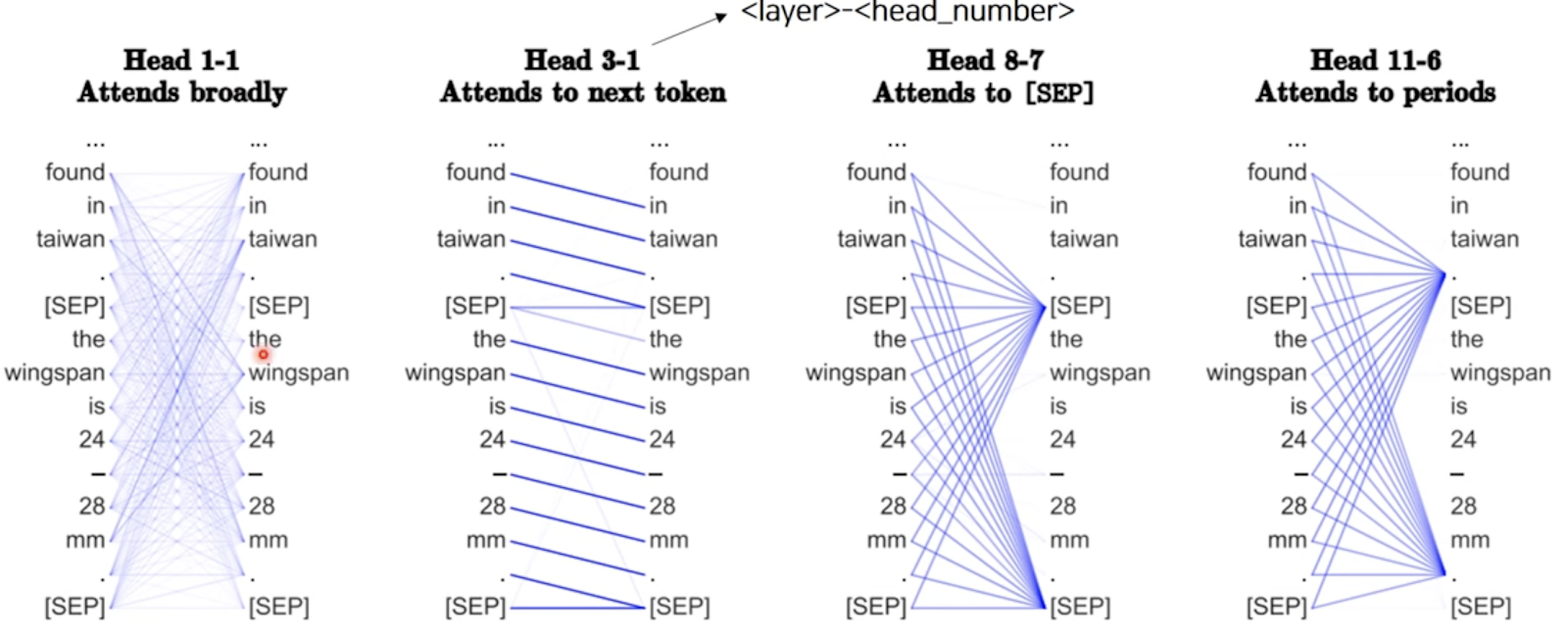
위와 같이 Attention을 통해 레이어마다 어떤 단어나 토큰에 집중하고 있는지도 확인해볼 수 있다.
모델의 tuning 과정을 analysis 관점으로 해석하여 모델의 동작을 확인해보는 방법도 있는데
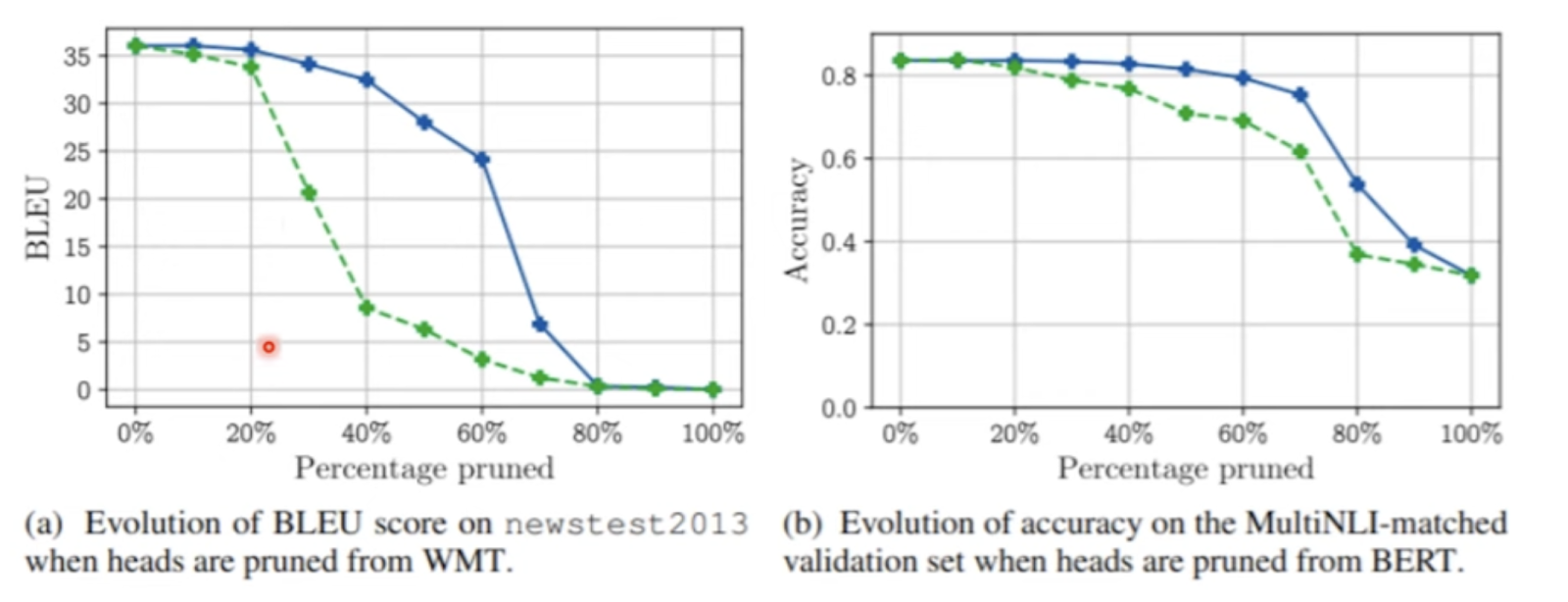
위와 같이 attention head를 삭제해보면서 성능의 변화를 확인해본 결과 몇개를 삭제해도 큰 영향이 없다는 결과도 있고

트랜스포머의 self attention과 feed forward의 구조를 바꿔가면서도 실험을 진행해본 결과 기존의 구조에서 변형을 가한 결과 성능이 더 정확해지는 경우도 있었다고 한다.
Future of NLP
GPT-1 : 트랜스포머 디코더만 사용한 단방향 모델로, 이전까지의 단어 기반으로 다음 단어를 예측하는 것이다. Fine Tuning을 진행해야 하므로 비용이 크고 다른 태스크에 사용하기 힘들다.
GPT-2 : Fine Tuning이 필요없이 여러 태스크에 적용가능한데 이는 GPT-1과 달리 수행할 태스크를 토큰으로 인풋에 함께 집어넣는 방식으로 진행된다. 따라서 이미 거대한 데이터를 통해 사전학습을 하므로 따로 태스크에 맞는 fine tuning을 하지 않아도 태스크를 수행 가능하다.
GPT-3 : GPT-2와 동일하게 토큰을 사용하나 Few Shot Learners 방식을 사용한다. GPT-3는 엄청난 파라미터를 가지며 Attention을 Sparse하게 주어 계산량을 줄인다. 또한 학습 과정을 학습하는 메타 러닝과정을 수행할 수 있다. 즉 태스크가 명시되지 않아도 test description과 예제를 통해 쉽게 학습을 진행할 수 있다.
GPT-3는 마지막 단어를 예측하거나 하는 태스크에는 높은 성능을 보이지만 여러 스텝의 과정이 필요한 태스크는 잘 수행하지 못하는 모습을 볼 수 있다.
GPT-3의 한계로는 인간과 같은 일반화 능력을 가지지는 못하고, 글로만 언어를 배우며 modality를 가지지 못한다는 점이 있다.
Compositional Representations and Systematic Generalization
Systematicity : 사람이 이해하는 문장들 간에는 확실하고 예측 가능한 패턴이 있다.
Compositionality : 한 표현의 의미는 그 표현을 구성하는 요소들의 의미와 구조로 구성된다. (인간의 언어는 구성성을 모두 만족하지는 않는다.)
학습한 모델이 주어진 문장에 대해 출력한 representation이 syntax tree 와 특정 composition function에 따라 결합된 representation을 잘 근사한다면 해당 representation은 compositional하다고 생각할 수 있다. 이를 통해 Tree Reconstruction Error라는 것을 정의할 수 있는데 이는 모델의 결과로 나온 representation과 각 구성요소들의 임베딩과 그로부터 만들어진 표현의 거리가 가까워질 수 있도록 Tree의 Leaf Node와 Composition function을 학습시키는 것이다.
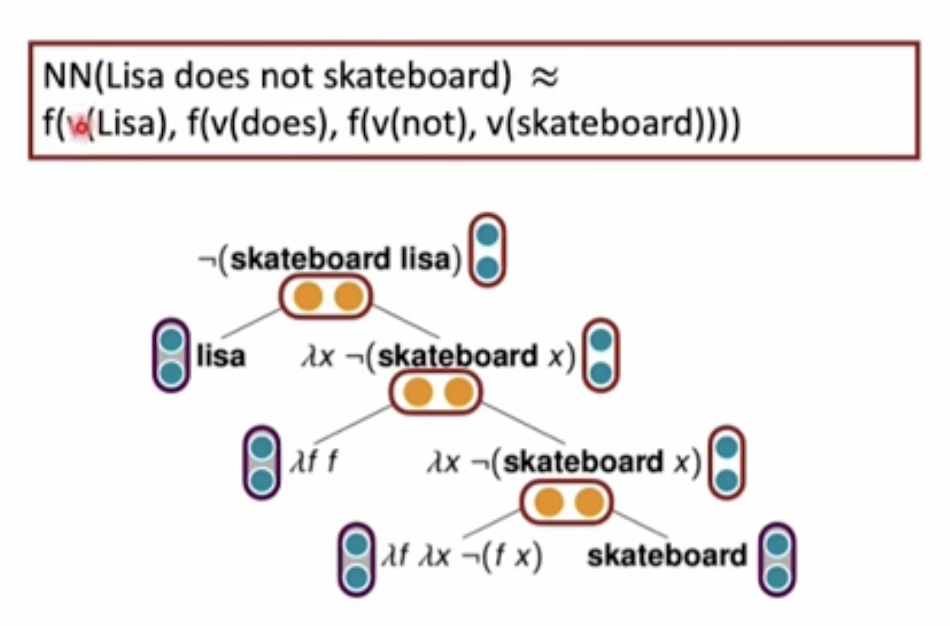
다음으로는 현존하는 모델이 구성 일반화 능력을 갖췄는지 측정하기 위한 방법이다.
알고 있는 요소들을 통해 새로운 조합을 만들거나 이해하는 능력이다. [니, 사과, 먹다, 아침] 이라는 단어를 알고 있는데 나 아침에 사과 먹었어 라는 문장은 이해하며 아침에 나 사과 먹었어는 이해하지 못한다면 구성 일반화 능력이 떨어진다고 생각할 수 있다.
이런 구성 일반화 능력을 측정하기 위해서 Atom과 Compound라는 개념이 필요한데, Atom은 Compound를 생성하는 가장 작은 단위가 되는 구성요소이고 Compound는 이러한 Atom들의 결합체를 의미한다.
구성 일반화 능력이 좋다는 것은 비슷한 Atom distribution하에서 Compound Distribution이 다른 환경이다. 따라서 train/test 를 compound divergence는 최대화하면서 atom divergence를 minimize하도록 분리한다.
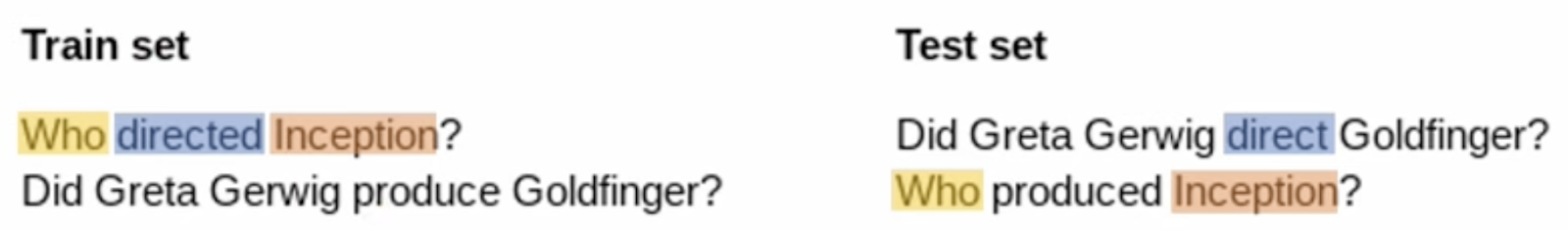
이를 수식으로 표현한 것이 Chernoff coefficient이다.

Atom divergence를 고정시키고 compound divergence를 늘리면 실험한 결과 우리가 사용하는 모델 대부분이 구성 일반화 능력이 좋지 않음을 확인할 수 있다. 그리고 pretraining 을 진행하면 구성 일반화 능력을 향상시킬 수 있지만 한계가 있음도 확인할 수 있었다.
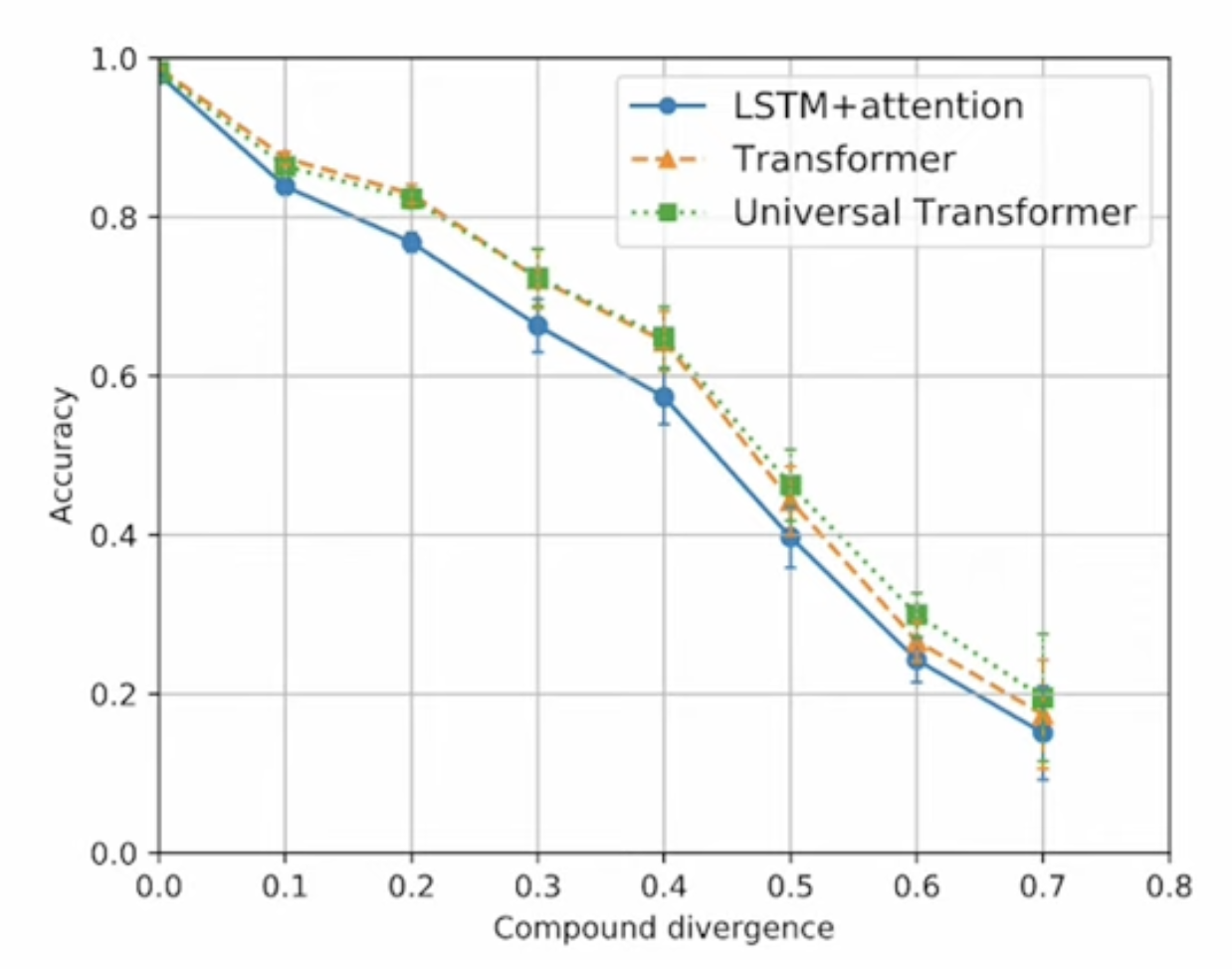
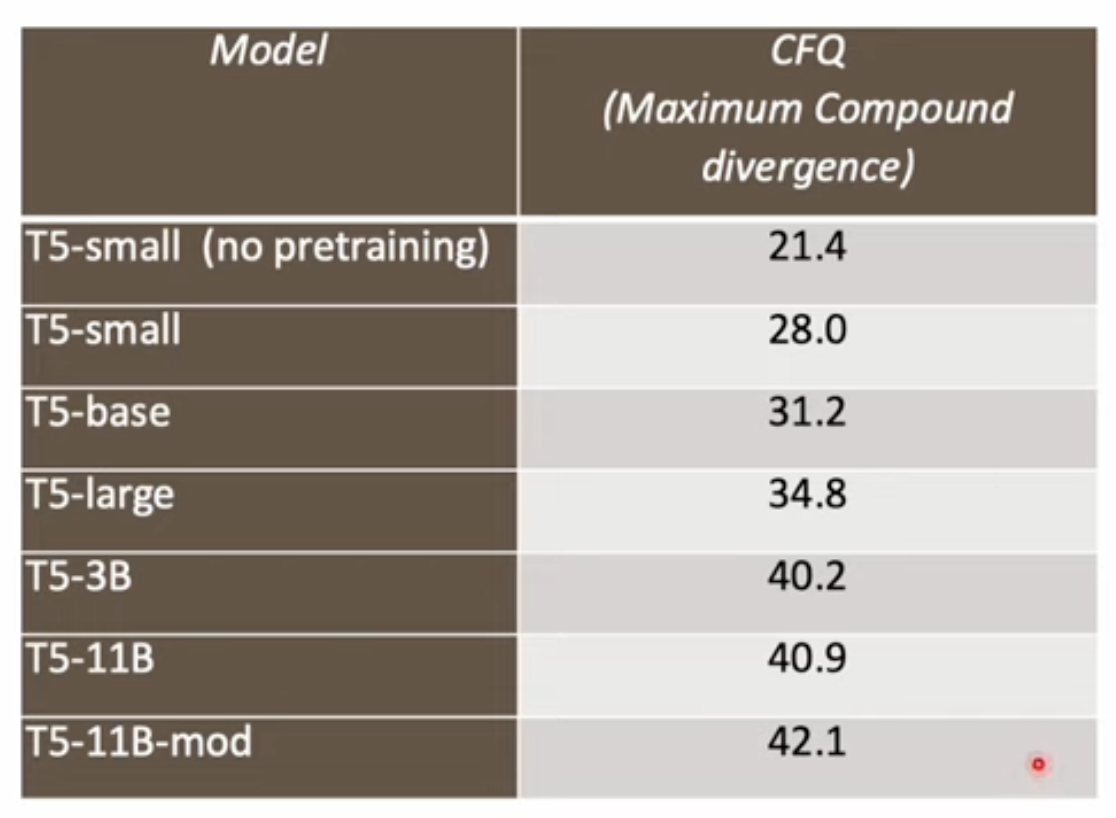
다음으로 NLP 모델의 평가방법에 대한 고찰이다.
NLP모델의 벤치마크 성능은 계속 증가하고 있는데 실제 practical 한 성능도 그만큼 증가했는지 평가하기 위한 방법 중 하나는 dynamic benchmarks이다. 이는 인간이 기계가 해석하기 힘든 문장을 계속 생성하여 이를 다시 학습하는 방법을 무한히 반복하는 것으로 다음과 같은 방식이 있다.

다음으로는 단순히 text만이 아닌 다양한 modality를 이용하여 언어를 이해하는 방식이다. 우리가 어떤 개념을 단순히 글로만 이해하기는 쉽지 않고 오감을 사용하면 더 쉽게 이해할 수 있다. 이렇게 다양한 방식으로 언어를 이해하는 단계를 세부적으로 Word Scope로 나눈 것이 다음과 같다.
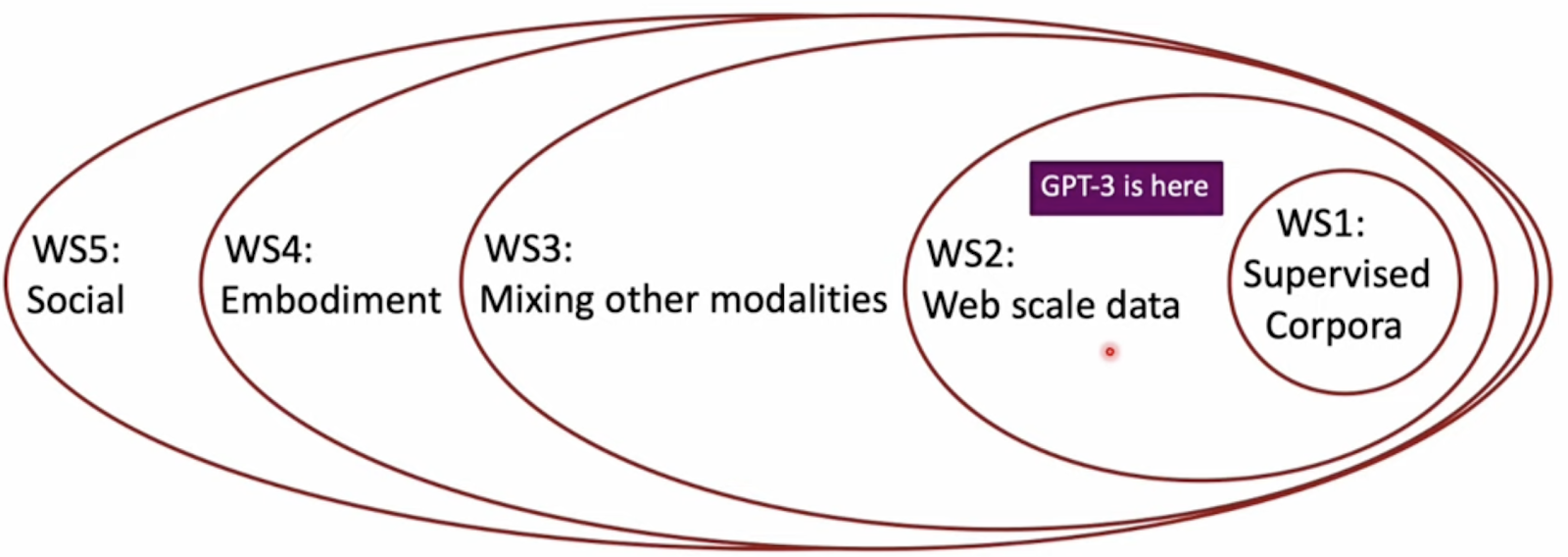
즉 앞으로 비전 등 다른 분야와 NLP를 결합해보는 것을 기대해볼 수 있다.
'강의 & 책 > CS224N' 카테고리의 다른 글
| [CS224N] Lecture 9, 10 : Pretraining, NLG (Natural Language Generation) (0) | 2023.03.04 |
|---|---|
| [CS224N] Language Modeling with LSTM and GRU (0) | 2023.03.04 |
| [CS224n] T5 and Large Language Models (0) | 2022.04.07 |
| [CS224n] Subword Modeling & Pretraining (0) | 2022.03.18 |
| [CS224n] 어텐션 (Attention) (0) | 2022.03.18 |


