
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- YAI 9기
- CNN
- transformer
- 자연어처리
- YAI 11기
- CS231n
- 3D
- YAI 8기
- 컴퓨터 비전
- VIT
- CS224N
- RCNN
- PytorchZeroToAll
- NLP
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- Perception 강의
- Googlenet
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- 컴퓨터비전
- 강화학습
- cl
- YAI
- YAI 10기
- Fast RCNN
- nerf
- GaN
- 연세대학교 인공지능학회
- rl
- Faster RCNN
- cv
- Today
- Total
연세대 인공지능학회 YAI
[CS224N] Language Modeling with LSTM and GRU 본문
YAI 10기 김강현님이 자연어강의팀에서 작성한 글입니다
1. Language Modeling
Language modeling이란, 다음 단어로 어떤 단어가 오는지 예측하는 task이다. 그리고 이러한 task를 수행하는 system을 가지고, Language Model이라고 한다.
2. N-gram Language Model
이 방법은, 딥러닝을 도입하기 전에 Language model을 학습시키기 위해 사용했던 방법이다. N-gram이란, N개의 연속된 단어이다.
다음에 어떤 단어가 올 확률을 구하기 위해, 우선 Markov Assumption을 한다: 이는, 다음 단어는 직전 N-1개의 단어에만 영향을 받는다는 의미이다. 즉, 그보다 더 이전 단어에는 영향을 받지 않는다는 의미이다. 만약 4-gram language model이라면, 다음과 같다.

여기서, N-gram model의 문제점이 발생한다.
Sparsity problem: 특정 N-gram이 corpus 안에서 출현빈도가 낮을 때 발생한다. 만약 매우 낮은 빈도로 출현하거나, 아얘 출현하지 않는다면 확률이 0이기 때문에, 분자가 0이 되거나 분모가 0이 되는 경우가 발생한다. 이에 대한 해결책으로, 최소한의 확률을 부여해서 0이 되는 것을 막는 smoothing이나, Ngram 대신 N-1 gram으로 줄이는 back-off가 있다.
Storage problem: N-gram의 count 정보를 저장하기 위해선, model의 크기가 매우 커져야 한다.
Incoherence problem: N-gram model이 문맥을 충분히 반영하지 못하는 문제이다. 즉, N개보다 훨신 이전의 문맥을 반영하지 못하기 때문에 필요한 정보를 놓치게 된다. N의 크기를 늘리면 해걸 가능 하지만, sparsity 문제가 발생한다.
3. Neural Language Model
이러한 N-gram 문제를 해결하기 위해 도입한 것이 Neural Network이다. NER처럼, 여기서는 N-gram처럼 예측할 단어 이전에 window를 고정한다.
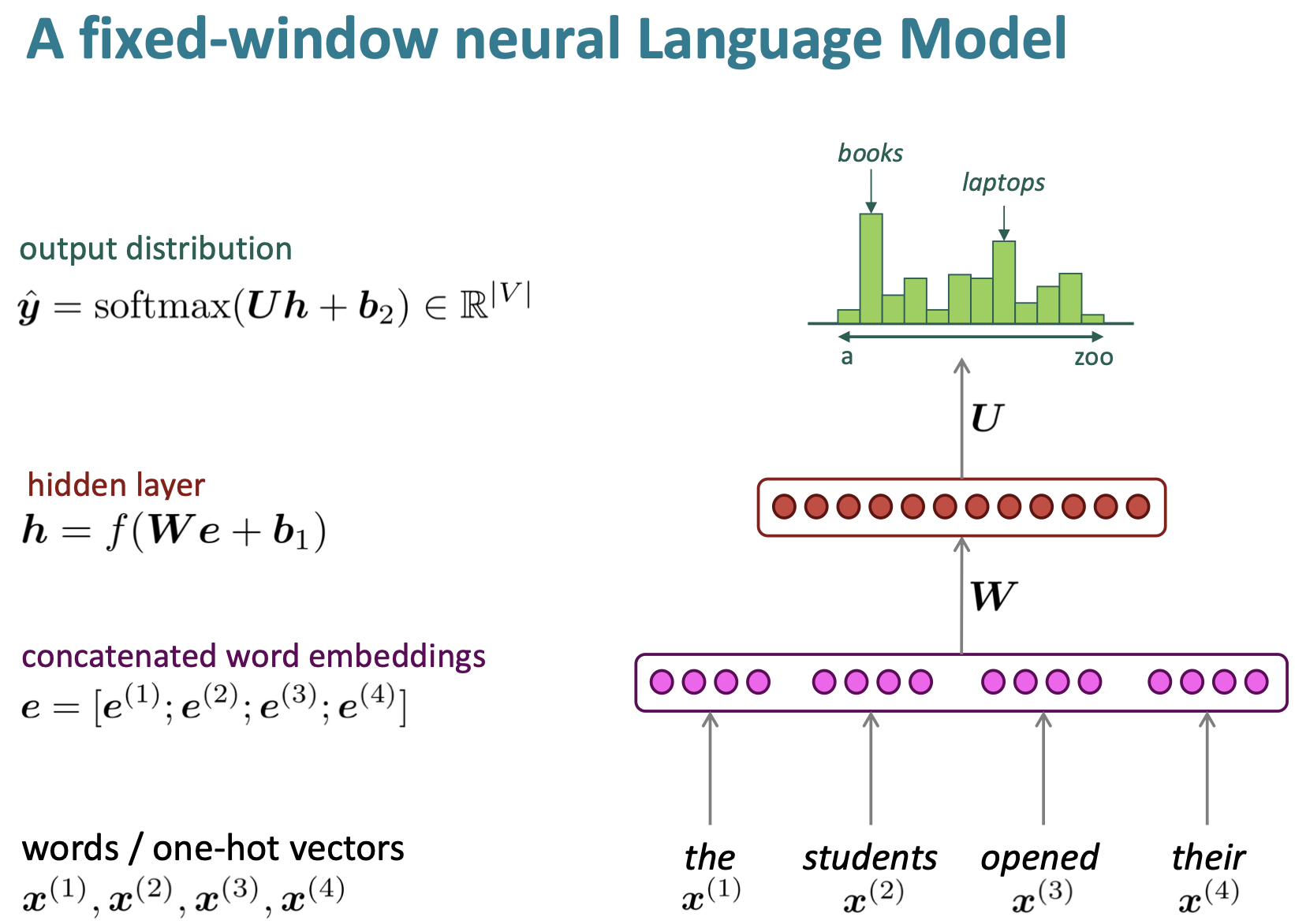
위의 예시에서는 4개의 단어를 입력받았다. 이를 적절히 embedding한 후, Neural Network로 다음 단어의 확률을 찾아내는 것이다. 이렇게, 고정된 개수의 단어를 neural network의 input으로 받는 model은 fixed-window neural language model이라고 한다.
N-gram에 비해 장점으로 다음과 같다.
softmax값을 통해서, sparsity 문제를 해소 가능하다.
Counting값을 저장할 필요가 없다.
단점은 다음과 같다.
N-grame과 같이, window size의 제한 때문에 제대로 된 context의 반영이 어렵다.
단어의 위치에 따라 가해지는 가중치가 다르기 때문에, Neural model이 비슷한 내용을 여러번 학습하게 되는 비효율성을 갖게 된다.
4. RNN Language Model
RNN의 아이디어는, input마다 동일한 가중치를 반복적으로 사용한다는 것이다. 또한, 순차적으로 정보를 처리한다는 것이 기본 아이디어이다.
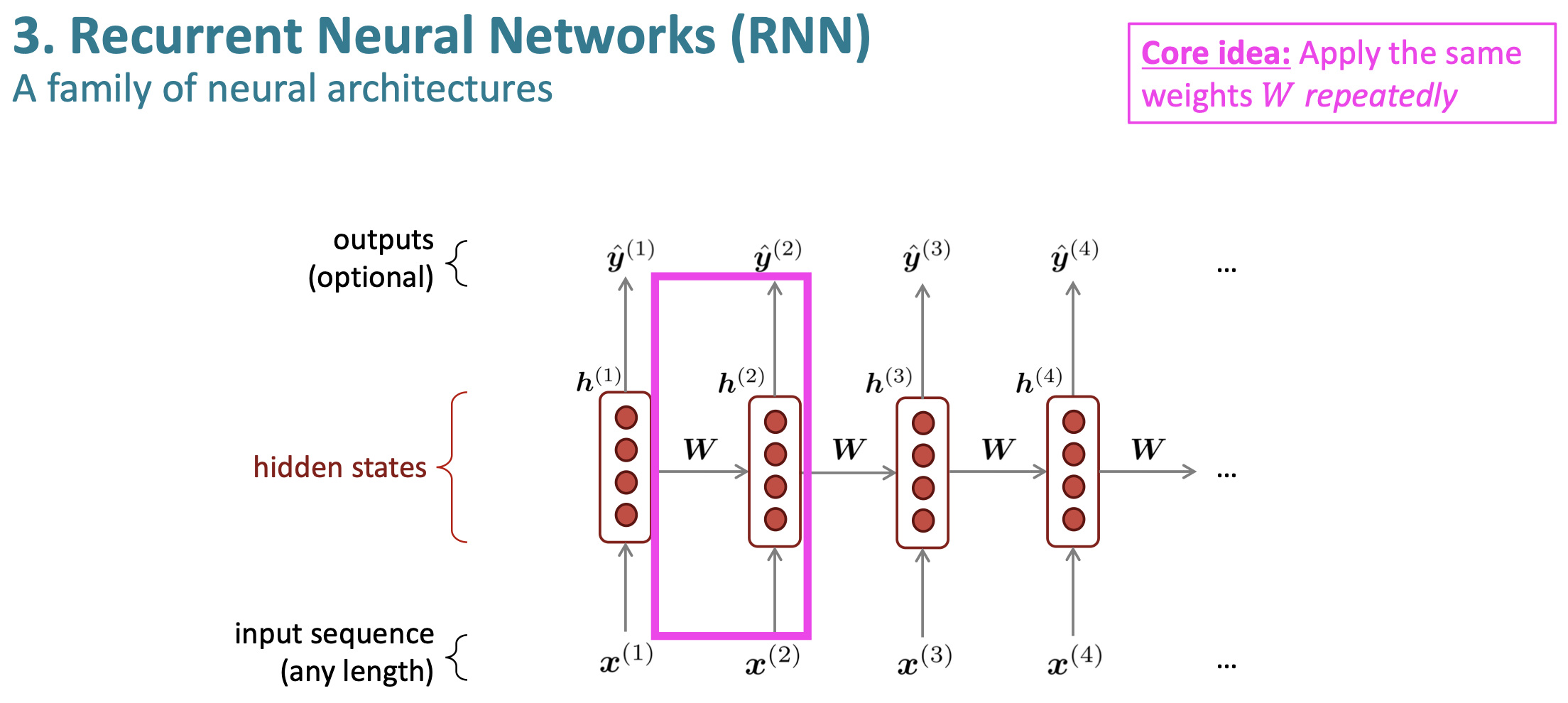
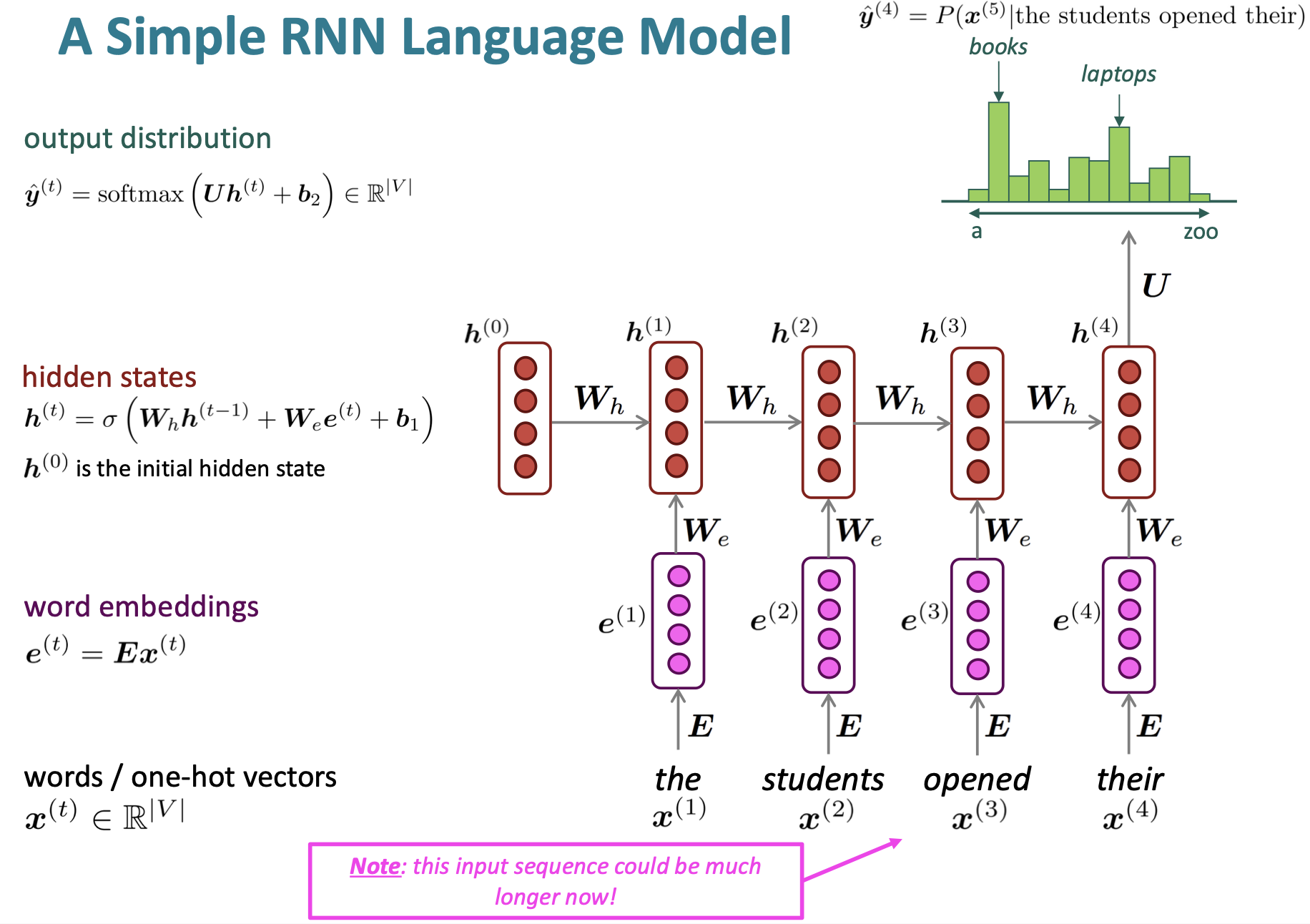
RNN의 장점은 다음과 같다.
어떤 길이의 input이라도 처리가 가능하다.
어떠한 step에서의 word더라도, 먼 곳의 word도 고려 가능하기 때문에 context 반영에 유리하다
input context가 길어지더도 model size가 커지지 않는.
매 timestep마다 동일한 weight가 적용되기 때문에, input이 어떻게 process되던지 symmetric하다.
단점은 다음과 같다.
computation이 느리다
여러 step 이전의 information에 접근하기가 어렵다.
RNN의 학습은 다음의 방법으로 진행된다.
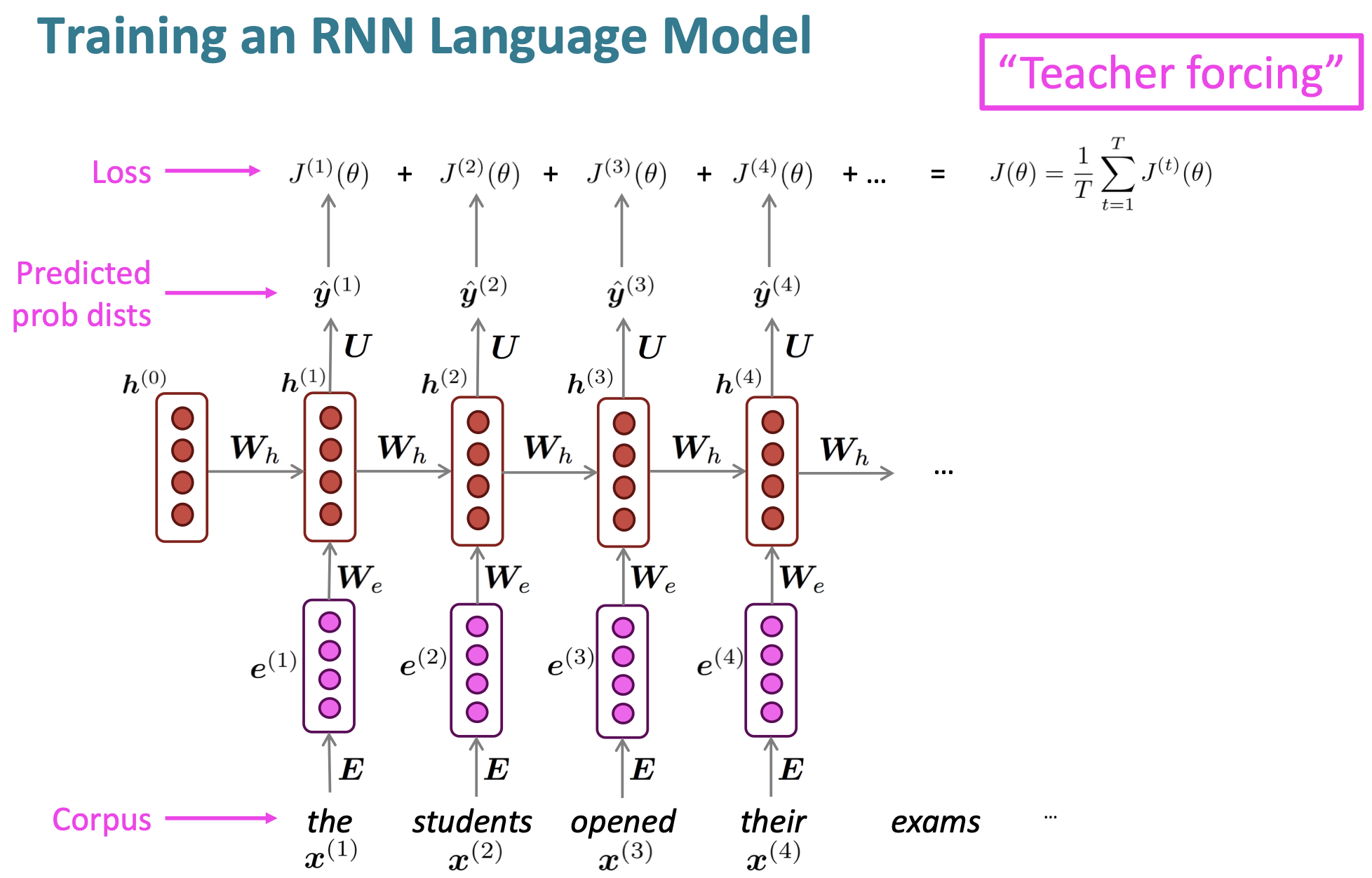
이렇게 각 단어에 대해서 input으로 주고, 예상되는 다음 단어를 계산한다. 그리고 그 차이를 cross entropy로 loss를 구하고 나서, 평균내어 전체 loss를 계산하여 학습한다.
다만 실제로 학습시키기엔 너무나도 많은 계산이 필요하기 때문에, 문장이나 문서 단위로 입력을 주거나, SGD 등의 방식으로 optimize하기도 한다.
여기서 학습할 때, network의 시간 step마다 parameter가 공유되기 때문에, 기존 backpropagation을 사용하지 않고, backpropagation through time이란 변형된 방식을 사용한다. 이는, 각 출력의 gradient가 이전 time step에서도 영향을 받기 때문이다.
5. Evaluation 방법 - perplexity
일반적인 Language model의 evaluation metric은 perplexity이다. 이는, Language model을 통해 예측한 corpus의 역을 corpus 길이로 normalize하는 방법이다. 이는 계산을 통해, cross-entropy에 log를 씌운 후, exponential을 통해 구할 수 있으며, 이 값이 낮을수록 좋은 Language model이다.

6. RNN의 문제점
RNN의 문제점은, Vanishing과 exploding gradient 문제이다. 일반적으로 학습이 이루어지게 되면, loss값이 뒤의 방향으로 전파되면서, 거치는 state의 gradient값과 곱해지게 된다. 만약 이때 곱해지는 값들이 작게 된다면, 계산되는 loss값이 점점 작아지면서, 학습의 속도가 매우 느려지게 된다.
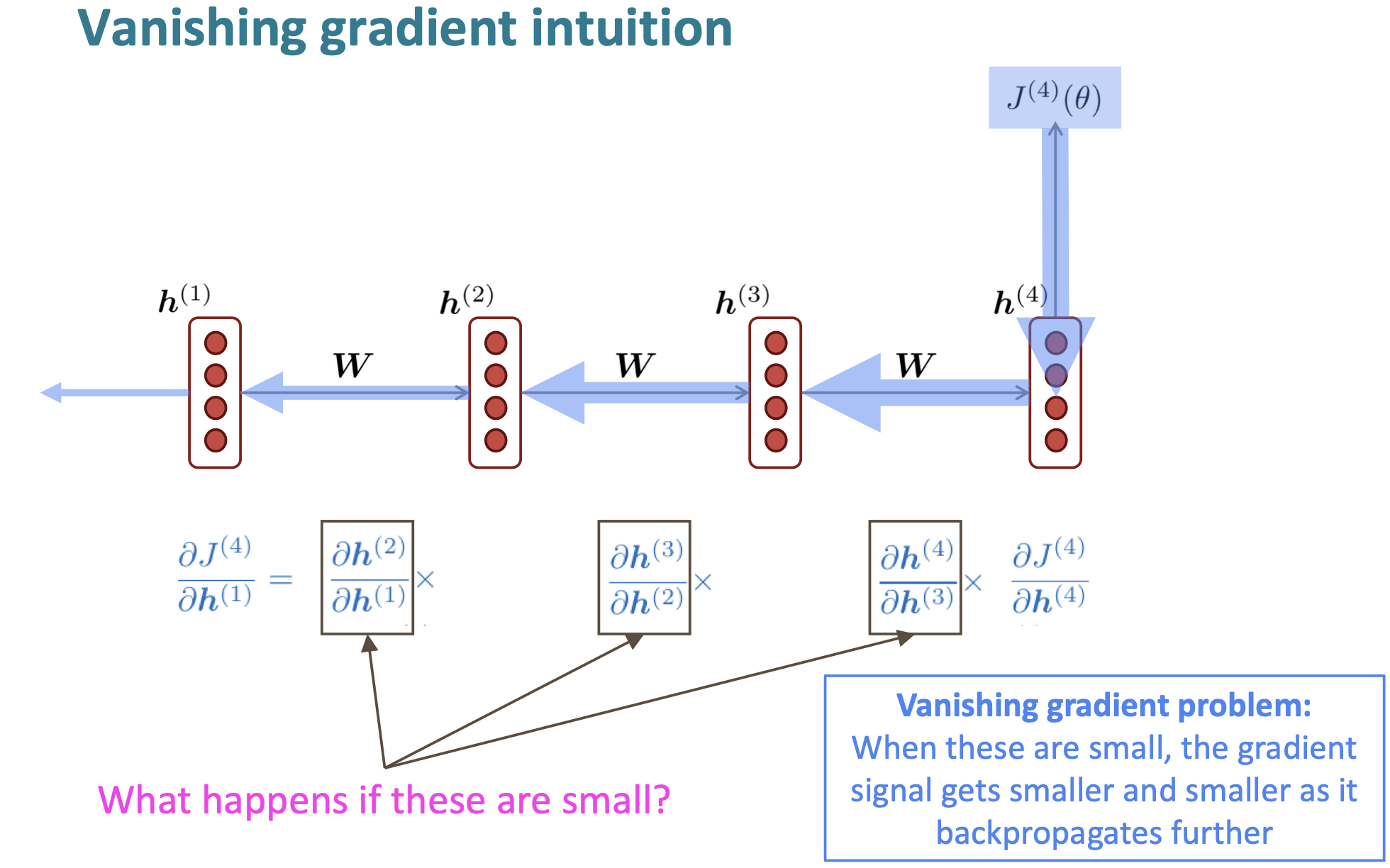
이러한 gradient값이 매우 작아지는 현상이, RNN에 어떠한 영향을 미칠까?
- 멀리 있는 gradient signal보다 가까이 있는 gradient signal에 대해서 더 많이 학습하게 된다. 즉, RNN의 장점 중 하나인, 멀리 있는 word로부터 학습이 가능하다는 점이 많이 줄어든다.
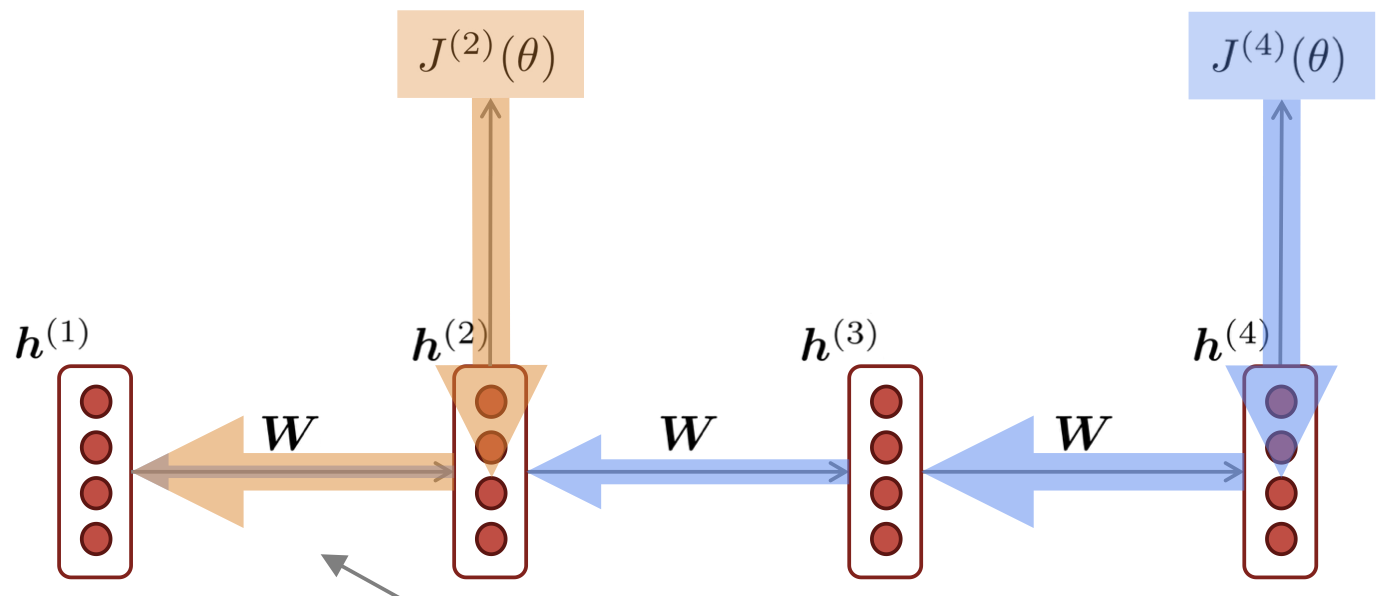
- gradient값인 너무 작아져서 0에 가까이 가는 경우, 이 값이 정말 의미가 없어서 0인것인지, 아니면 gradient가 0으로 작아진 것인지 구분하기가 힘들다.
강의자료에서는 다음과 같은 문장을 예시를 들었다.
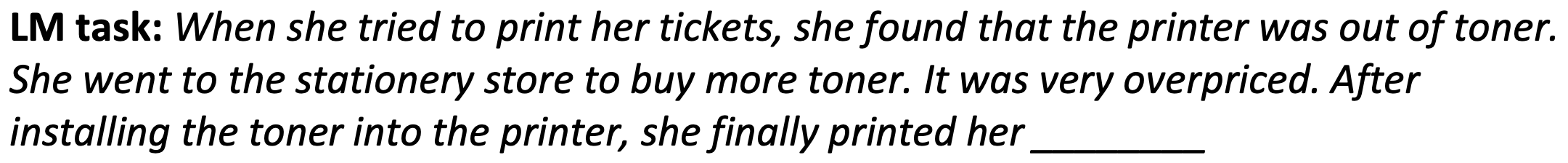
해당 LM task에서, 문맥상 예상되는 단어는 ticket이다. 하지만 vanishing gradient 문제로 인해, 멀리 있는 ticket과의 dependency를 학습을 못해서, 가까이 있는 printer를 학습하게 된다.
이러한 vanishing problem 말고도, exploding problem도 있다.
만약 gradient가 너무 크다면, SGD update step이 너무 커져서, bad update를 발생하게 된다. 이러한 경우, INF값을 갖게 되거나, NaN 값을 갖게 되어, network를 재시작해야 할 수도 있다.
이를 해결하기 위, Gradient Clipping 방식을 사용한다. 이는, 만약 gradient의 평균이 특정 threshold보다 높다면, SGD update를 하기 전에 scale down하는 방식이다.
주된 문제는, RNN이 many timestep동안 얻는 information을 preserve하면서 학습시키는 것이 어렵기 때문이다. vanilla RNN에서는, hidden state가 계속 rewritten되기 때문!

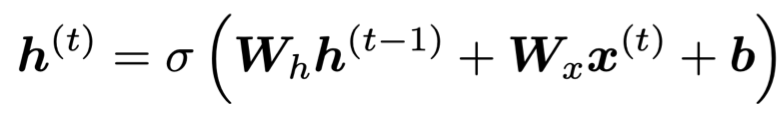
이러한 RNN을 memory와 분리해서 설계하는 방식이 이제 LSTM과 GRU이다.
7. LSTM
RNN의 장기 의존성 문제를 해결하기 위해, RNN에서 메모리를 분리하여 따로 정보를 저장, 이전의 데이터도 함께 고려할 수 있는 모델이다.
LSTM의 핵심 아이디어는 다음과 같다.
cell state로 이전 단계의 정보를 memory cell에 저장해서 흘려보낸다.
현재 시점의 정보를 바탕으로, 과거의 내용을 얼마나 잊을지 곱하고, 그 결과에 현재 정보를 더해서 다음 시점으로 정보를 전달한다.
전체적인 모습은 다음과 같다.
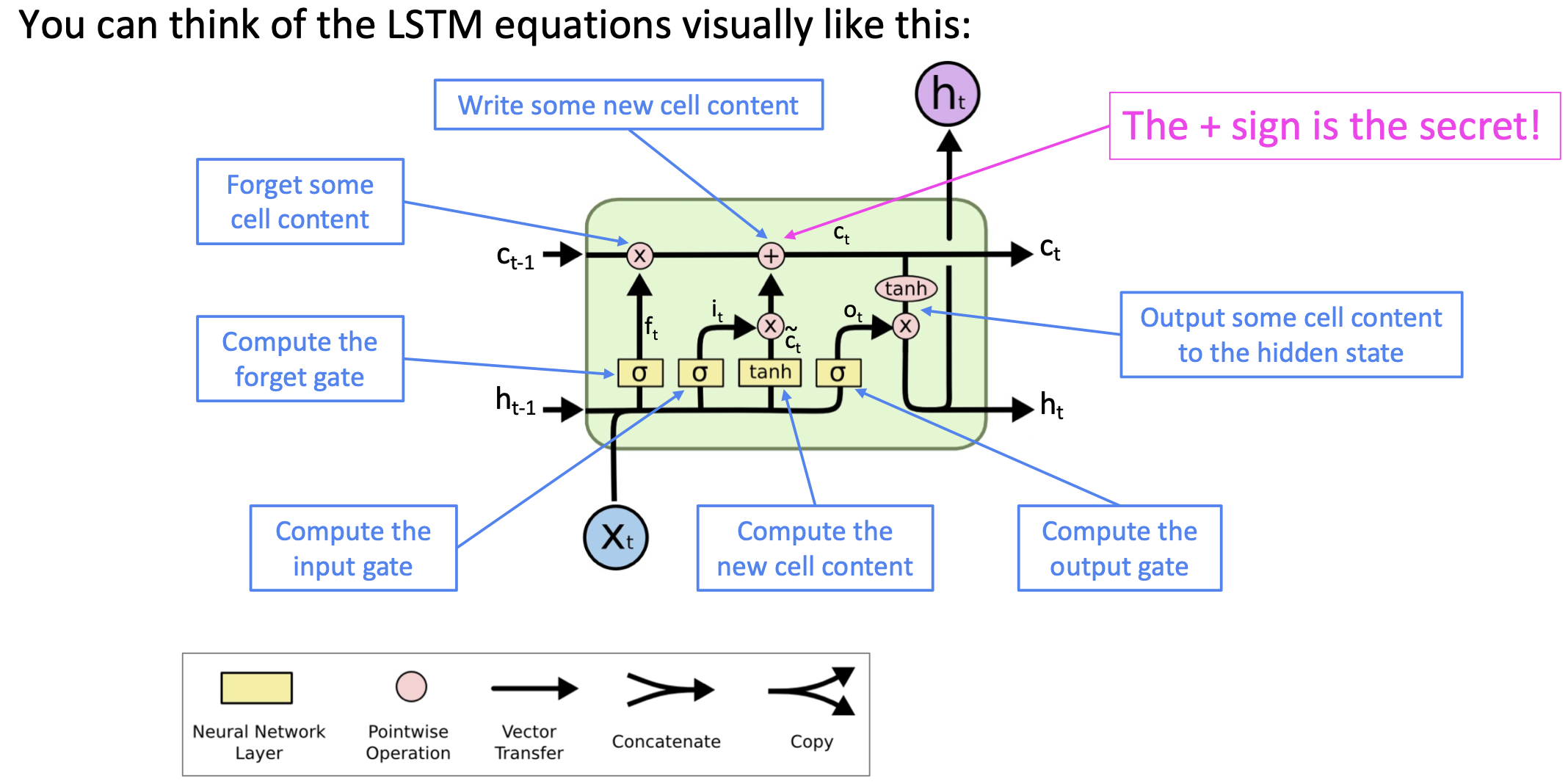
Forget gate: 어떤 정보를 잊고, 어떤 정보를 반영할지에 대한 결정을 한다. 출력값이 0이면 불필요한 정보를 지우고, 1에 가까우면 반영을 많이 한다는 의미이다.
Input gate: 새로운 정보가 cell state에 저장될 지 결정하는 gate이다. sigmoid로 반영할지 말지 결정하고, tanh로 그 값을 반영한다.
Update cell: 최종적으로 과거의 정보를 삭제/유지 유무를 forget gate로 결정, 그리고 input의 반영을 input gate에서 결정한다.
output gate: output을 계산해서, 최종 output 값과 다음 state의 input값을 결정한다.
여기서 LSTM이 vanishing gradient 문제를 해결하는 방법은 다음과 같다.
만약 forget gate가 1, input gate가 0이면, information은 완전히 보존되게 된다.
하지만, 이 방법은 무조건적으로 해결한다고 보장할 수는 없다.
8. Machine Translation
Machine translation이란, sentence x를 다른 언어로 바꾸는 과정이라고 생각하면 된다. 과거 1950년대에는 냉전 당시 소련과 미국의 통신/기밀 문서를 자동으로 번역, 해석하기 위해서였다. 당시의 번역은 주로 rule-based방식으로, 사전을 통해 대응하는 단어를 찾아 번역하는 가장 간단한 모델이었다.
그러다 1990~2010년대에는 Statistical Machine Translation이라는 방법으로, 확률 모델을 이용해서 번역을 하는 모델이 등장했다. 데이터를 통해 확률 분포를 학습하여, bayes theorem을 사용해서 계산하는 방식으로 이루어졌다.
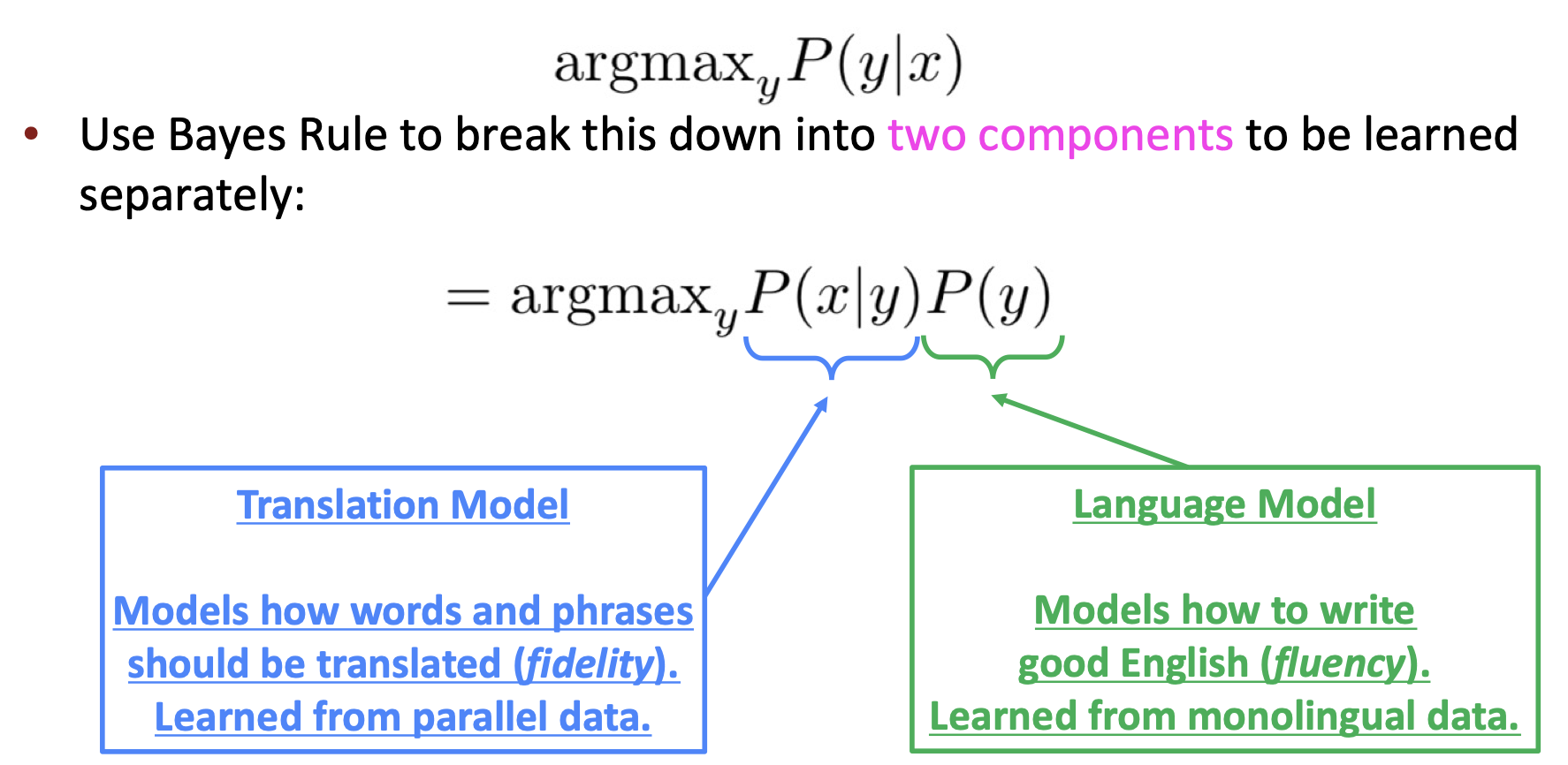
이러한 SMT는 상당한 연구가 많이 진행되었지만, 가장 성능이 좋은 system은 매우 복잡했다. 그러던 와중에, Neural Machine Translation이 등장했다.
Neural machine translation은, single end-to-end neural network를 통해 machine translation을 진행한다. 이렇나 Neural architecture는 Seq2Seq라고 부르며, 2개의 RNN을 사용한다.
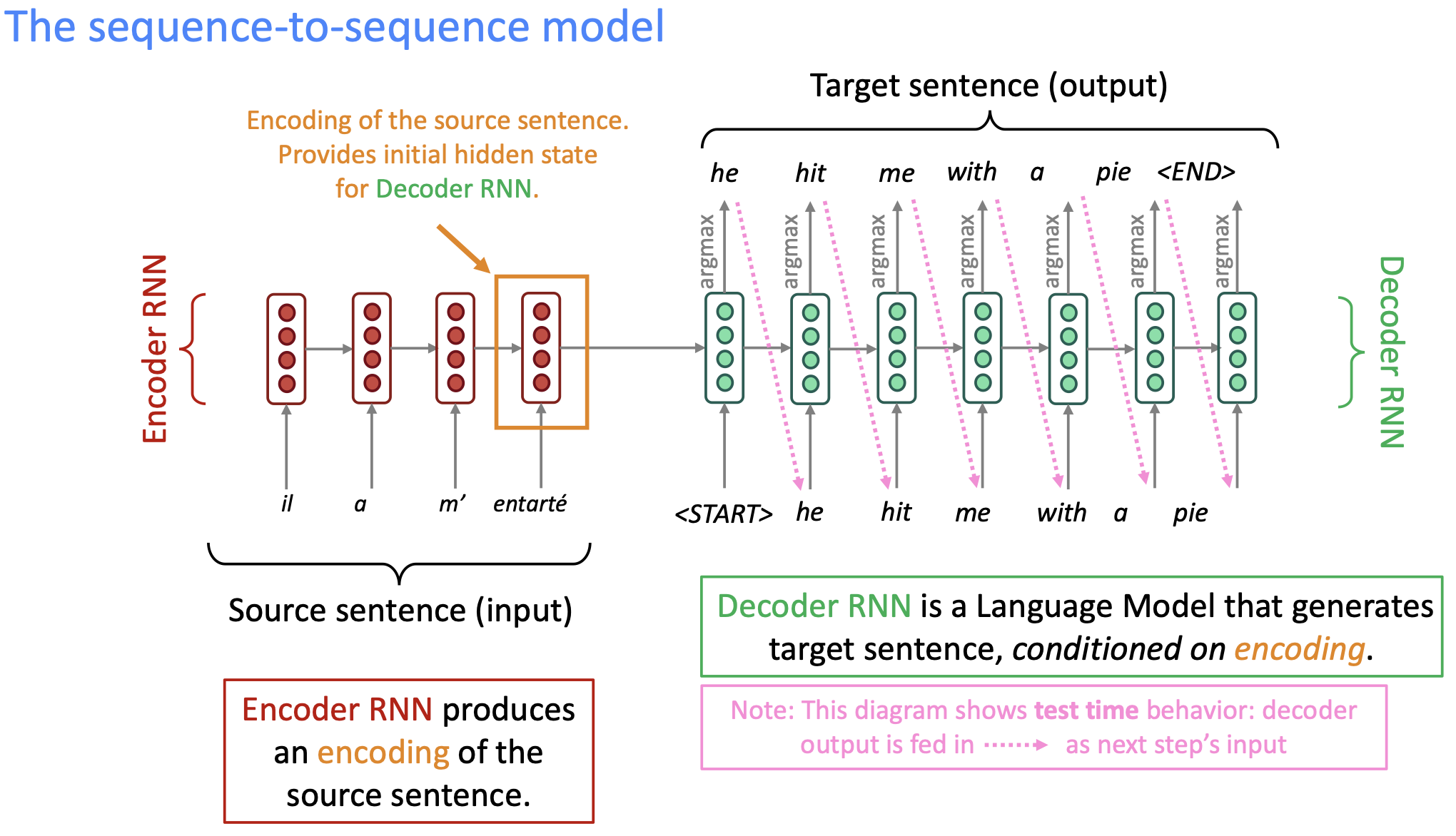
Seq2Seq의 neuron architecture는 2개의 RNN, 즉 encoder와 decoder를 가지고 있다. 하나의 sequence를 다른 sequence로 매핑하는 방식이다.
왼쪽의 Encoder측에서, source sentence를 encode하여 decoder RNN에 전달하면, 해당 decoder RNN은 이를 decode하여 target sentence를 만든다. 이 방법을 반복하여 계속 학습하는 방법이 seq2seq 모델이다. 해당 모델은, 단순 MT보다도 훨신 유용한데, 다양한 NLP task들은 seq2seq로 해결 가능하다.
Summarization : long → short
Dialogue : previous utterances → next utterance
Parsing : input text → output parse as sequence
Code generation : Natural language → python code
이러한 Seq2Seq 모델은 conditional language model의 예시라고 할 수 있다.
Language model의 이유로, decoder는 target sentence y의 다음 단어를 예측하기 때문이다.
Conditional의 이유로, prediction은 source sentence x의 조건에 따라 바뀔 수 있기 때문이다.
이러한 NMT(Neural Machine Translation)은 직접 확률을 계산하게 된다:

여기서, 이러한 system을 train하는 방법으로, 간단한 해결책은 big parallel corpus를 사용하면 된다고 한다. 하지만, 이러한 방법 말고 더 현명하고 좋은 방법이 있다: unsupervised NMT, data augmentation 등등등..
'강의 & 책 > CS224N' 카테고리의 다른 글
| [CS224N] Lecture 9, 10 : Pretraining, NLG (Natural Language Generation) (0) | 2023.03.04 |
|---|---|
| [CS224N] Language Model, Analysis, Future of NLP (0) | 2023.01.14 |
| [CS224n] T5 and Large Language Models (0) | 2022.04.07 |
| [CS224n] Subword Modeling & Pretraining (0) | 2022.03.18 |
| [CS224n] 어텐션 (Attention) (0) | 2022.03.18 |


