
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- YAI 9기
- YAI 8기
- 컴퓨터비전
- CS231n
- PytorchZeroToAll
- YAI 10기
- YAI 11기
- VIT
- GaN
- 자연어처리
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- RCNN
- transformer
- cv
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- cl
- nerf
- rl
- NLP
- YAI
- CS224N
- CNN
- 강화학습
- Fast RCNN
- 컴퓨터 비전
- 연세대학교 인공지능학회
- Perception 강의
- Googlenet
- Faster RCNN
- 3D
- Today
- Total
목록분류 전체보기 (57)
연세대 인공지능학회 YAI
 [논문 리뷰] GDumb A Simple Approach that Questions Our Progres
[논문 리뷰] GDumb A Simple Approach that Questions Our Progres
GDumb A Simple Approach that Questions Our Progres * YAI 9기 조용기 님이 작성한 글입니다. 논문소개 GitHub - drimpossible/GDumb: Simplified code for our paper "GDumb: A Simple Approach that Questions Our Progress in Continual Learning". Easily extensible to various settings, datasets and architectures.
 [논문 리뷰] Continual Unsupervised Representation Learning
[논문 리뷰] Continual Unsupervised Representation Learning
Continual Unsupervised Representation Learning ** YAI 8기 김주연이 Continual Learning 팀에서 작성한 글입니다.
 [논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
[논문 리뷰] ViT / An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale ** YAI 9기 박찬혁님이 비전논문팀에서 작성한 글입니다. Introduction 현재 Transformer와 같은 Self-attention-based 구조들이 NLP에서 주된 방식이다. 이 방법들은 주로 큰 모델에서 사전학습을 진행 후에 작은 데이터셋으로 Fine tuning하여 사용하는 방식으로 쓰인다. 이 Transformer 방식을 이미지에 바로 적용시키는 것이 이 논문의 목적이다. 이미지를 patch라는 작은 단위로 나누어서 NLP의 token과 같은 방식으로 간단한 imbedding 후에 Transformer에 집어넣는다. 이 방식은 기존 CNN이 이미지에 ..
 [논문 리뷰] End-to-End Incremental Learning
[논문 리뷰] End-to-End Incremental Learning
End-to-End Incremental Learning GitHub - fmcp/EndToEndIncrementalLearning: End-to-End Incremental Learning *YAI 9기 조용기님이 Continual Learning 팀에서 작성한 글입니다. 1 Introduction 실제 응용 프로그램을 대상으로 하는 시각적 인식 시스템을 개발할 때 주요 과제 중 하나는 새로운 클래스가 계속해서 학습되는, 즉 분류기를 점진적으로 학습하는 것이다. 예를 들어, 얼굴 인식 시스템은 새로운 사람을 식별하기 위하여 새로운 얼굴을 학습해야 하며, 이러한 task는 이미 학습한 얼굴들을 재학습시킬 필요 없이 해결되어야 한다. 이는 대부분의 사람들에게 사소하지만 (매일 새로운 얼굴들을 인식하므로),..
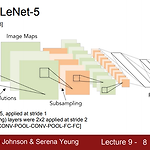 [논문 리뷰] Going Deeper with Convolutions
[논문 리뷰] Going Deeper with Convolutions
Going Deeper with Convolutions YAI 9기 김석님이 비전논문기초팀에서 작성한 글입니다. 0. Abstract 목적 → Network 내에서 compute가 진행될 시 소모되는 자원의 효율성을 높이기 위함 Method Compute 할 양을 늘어나지 않는 상태에서 depth와 width를 늘릴 수 있는 디자인 (codenamed Inception) Optimization 방법 → Hebbian principle에 근거한 multi-scale processing 사용 GoogLeNet Proposal Classification과 detection 목적으로 설계된 22 layer deep network 1. Backgrounds Object detection에서 사용한 방법 → Mod..
 [MLOps] Docker Basics / Images & Containers / Managing Images & Containers
[MLOps] Docker Basics / Images & Containers / Managing Images & Containers
Docker Basics / Images & Containers / Managing Images & Containers *YAI 8기 김상현님이 MLOps팀에서 작성한 글입니다. Docker Basics What is Docker? Docker Docker는 컨테이너(container)를 만들고 이를 관리하는 기술입니다. 이때, 컨테이너란 표준화된 소프트웨어의 단위(a standardized unit of software)를 의미합니다. 예를 들어서 NodeJS 어플리케이션 컨테이너라면 어플리케이션 코드뿐만 아니라 의존성(dependencies)을 포함합니다. 컨테이너는 모두 동일하기 때문에, 같은 행동(behavior)을 할 것이라고 기대할 수 있습니다. Container 컨테이너는 규격화된 모양을 갖..
 [Continual Learning] What is continual learning?
[Continual Learning] What is continual learning?
What is continual learning? * YAI 9기 조현우 님이 작성한 글입니다. Introduction 사람과 다르게 인공지능은 순차적으로 들어오는 데이터를 전부 기억하지 못합니다. 동물을 분류하는 인공지능 모델을 예로 들어보겠습니다. Day 1에는 개의 이미지만 있어서, 이것으로만 학습을 하면 모델은 개를 인식하고 분류할 수 있게 됩니다. 그 다음에 Day 2에 고양이 이미지가 새로 들어와서, 이것으로 새로 학습을 시키면 모델은 고양이를 분류할 수 있게 됩니다. 하지만 고양이로만 학습을 시킨다면 이전에 학습했던 개에 대한 정보는 전부 잃어버리게 될 것입니다. 이처럼 인공지능 모델이 새로운 데이터를 학습할때 기존의 데이터에 대한 정보를 잃어버리는 현상을 Catastrophic forget..
 [논문 리뷰] Variational AutoEncoder(VAE)
[논문 리뷰] Variational AutoEncoder(VAE)
Variational AutoEncoder(VAE) YAI 9기 박준영님이 창의자율과제 Multimodal팀에서 작성한 글입니다. Deep generative learning 딥러닝을 배제하고 무언가를 생성하는 모델을 생각해보자. 그 무언가에 해당하는 modality는 시각적인 정보가 될 수도 있고, 사람이나 다양한 사물, 동물의 소리를 모사한 형태의 음성 정보가 될 수도 있으며 혹은 획기적인 디자인이나 심금을 울리는 글 형태가 될 수도 있다. 인간은 생물학적인 발전을 거치면서 자연스럽게 무언가를 ‘인식’하거나 ‘분류’하는 능력을 가지게 된다. 이는 assimilation과 accomodation을 거치며 내적으로 여러 가지 자극들에 대해 범주화가 자동으로 진행되기 때문이다. 이처럼 인간은 classif..