
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- nerf
- CS224N
- rl
- RCNN
- Faster RCNN
- Googlenet
- transformer
- 자연어처리
- PytorchZeroToAll
- NLP
- 3D
- VIT
- 강화학습
- YAI
- Fast RCNN
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- 연세대학교 인공지능학회
- cv
- cl
- YAI 10기
- YAI 11기
- YAI 9기
- CS231n
- CNN
- 컴퓨터비전
- YAI 8기
- Perception 강의
- GaN
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- 컴퓨터 비전
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] Variational AutoEncoder(VAE) 본문
Variational AutoEncoder(VAE)
- YAI 9기 박준영님이 창의자율과제 Multimodal팀에서 작성한 글입니다.
Deep generative learning

딥러닝을 배제하고 무언가를 생성하는 모델을 생각해보자. 그 무언가에 해당하는 modality는 시각적인 정보가 될 수도 있고, 사람이나 다양한 사물, 동물의 소리를 모사한 형태의 음성 정보가 될 수도 있으며 혹은 획기적인 디자인이나 심금을 울리는 글 형태가 될 수도 있다.
인간은 생물학적인 발전을 거치면서 자연스럽게 무언가를 ‘인식’하거나 ‘분류’하는 능력을 가지게 된다. 이는 assimilation과 accomodation을 거치며 내적으로 여러 가지 자극들에 대해 범주화가 자동으로 진행되기 때문이다. 이처럼 인간은 classification이나 object detection, segmentation 등 정답이 정해진 문제에 대해 유연하게 대처하는 능력이 존재한다. 이처럼 딥러닝, AI로도 비슷한 task를 처리하는 부분에 대해 파라미터를 가진 deep network를 구성하고, 전체 구조를 학습하는데 있어 Gradient descent라는 연산이 간단한 메커니즘으로 알 수 없는 미지의 고차원 영역을 방대한 데이터로 학습하기 시작했다.
그러나 위에서 자연스럽게 소개한 내용은 모두 특정 task가 있다면 그 task는 어떠한 modality를 받아 인간이 인지하지 못하는 feature 영역으로 정보를 압축시키고, 해당 정보를 가지고 어떠한 일을 처리하는 과정이다. 그렇다면 이와 반대로 실제로 데이터를 만드는 모델은 어떻게 구성할 수 있을까?
Generative model 중에 단연코 딥러닝에서 가장 자주 들었던 친구를 찾자면 그것은 GAN일 것이다. GAN은 말 그대로 discriminator network와 generator network를 싸우게 해서 서로의 성능을 높이고자 한 모델이다.
$\min_{G} \max_{D} V(D, G) = E_{x\sim p_{data}(x)[\log D(x)]}]+E_{z\sim p_z(z)}[log(1-D(G(z)))]$
따라서 해당 네트워크는 위와 같은 식에서 generator는 최소화하는 방향, discriminator는 최대화하는 방향으로 학습을 진행하게 된다. 하지만 이번 내용에서 살펴볼 것은 GAN이 아닌 VAE며, 이 두 모델에 대해 trade-off가 어떻고 서로 어떻게 다른 지에 대해서 살펴볼 예정이다.
Deep generative learning에는 크게 두 framework로 구분할 수 있는데,
- Likelihood-based frameworks
- autoregressive models
- variational autoencoders
- flow-based models
- diffusion models
- Implicit models
- generative adversarial networks(GAN)
Autoencoders
VAE(Variational Autoencoder)를 보기 전에 우선 그와 형태가 똑같은 Autoencoder에 대해 소개하도록 하겠다. Autoencoder의 목적은 마치 PCA(Principal Component Analysis)와 같이 고차원의 실제 데이터를 미지의 feature latent 상에서 표현하고, 이를 토대로 구분 가능한 형태로 mapping 하고자 하는 목적을 달성하는 것이다. 따라서 Autoencoder의 주 목적은 데이터를 잘 mapping하는 encoder를 학습함에 있다.
- Architecture

위의 구조에서 확인할 수 있듯이 Autoencoder는 두 개의 큰 구조로 구성되는데, encoder와 decoder이다. autoencoder에서의 encoder는 input $x$를 토대로 deterministic 혹은 stochastic을 거쳐 latent vector $z$를 생성해 내고, decoder는 바로 이 latent vector $z$를 input으로 원래의 input $x$와 유사한 $\tilde{x}$를 생성하게끔 학습된다.
Autoencoder에서의 decoder의 역할은 encoder가 너무 터무니없는 code를 학습하지 않게끔 보조하는 역할을 수행하며, 원래의 데이터인 $x$를 복원할 수 있을 정도까지의 latent space code를 학습할 수 있게 된다.
일반적으로 PCA에서와 비슷하게 encoder는 dimension을 줄이는 역할을 수행하고, decoder는 dimension을 늘리는 역할을 수행한다. 이를 표현하는 용어가 있는데,
$dim(x) > dim(z)$ : undercomplete —> capture important features of input
$dim(x) < dim(z)$ : overcomplete
위와 같다.
- Training
파라미터의 학습 목적은 다음과 같다.
$$\phi^* ,\theta^* = argmin_{\phi , \theta} L(x, \bar x )$$
여기서 $L$은 loss function을 의미하고, encoder input $x$와 decoder output $\tilde{x}$ 간의 거리를 최소화하는 모든 형태의 objective가 가능하다.
- Application
흔히 생각할 수 있는 활용도는 차원 축소, feature(representation) learning 그리고 generative modeling의 forefront 등이 있다.
앞서 설명했던 것과 같이 $f, g$가 non-linearity가 배제된 형태의 네트워크 구조이고 MSE loss가 사용된다면 마치 $z$는 PCA한 것과 같다고 볼 수도 있다.
- Denoising autoencoder(DAE)
만약 input에 인위적으로 noise를 가한 후 이를 latent vector로 넘기고, 노이즈가 더해진 데이터를 feature latent부터 복구하면서 decoder가 노이즈를 제거하게끔 하는 DAE도 생각해볼 수 있다.
언어 모델 중 유명한 BERT가 바로 denoising autoencoder의 메커니즘과 동일한데, 바로 다음과 같은 구조를 가지는 것을 볼 수 있다.
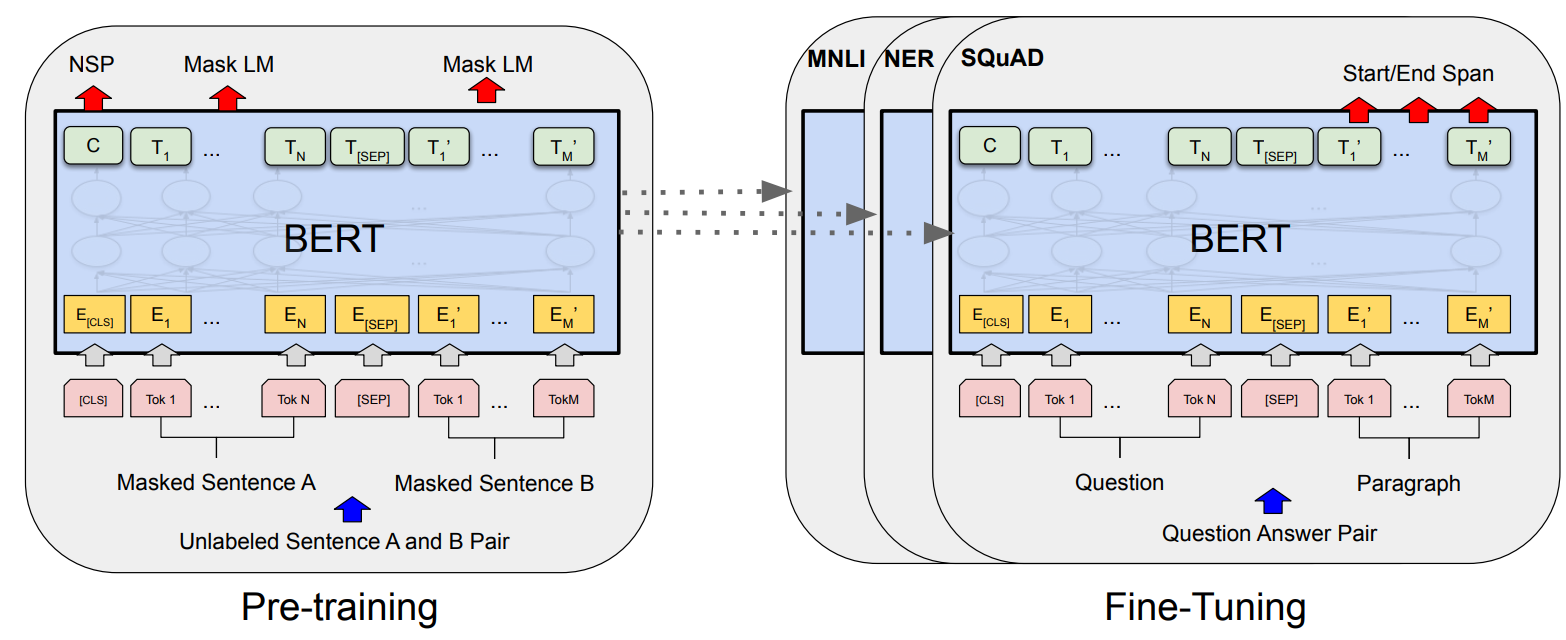
Denoising autoencoder에서 noise의 형태는 아무 것이나 될 수 있기 때문에 masking하거나 다른 token으로 바꾸는 과정을 noise를 추가한다고 생각하면 이를 해결하는 형태의 학습으로 이해할 수 있다.
Variational Autoencoder
VAE는 가장 앞부분에서 설명했듯이 likelihood based framework라고 했었다. 즉 generative modeling을 할 때 확률에 기반한 학습을 할 것이라는 암시가 된다.
VAE의 경우 복잡한 distribution을 가지는 학습 과정을 approximate하게 추론 가능하게끔 구조를 잡았으며, 이와 더불어 gradient based method를 통해 네트워크를 학습시킬 수 있다. VAE의 장점은 빠르고 tractable sampling이 가능하다는 점이 있으며, encoding network에 쉽게 access할 수 있다는 것이고, 단점은 sample quality가 획기적으로 좋다고 말할 수 없다는 점이다.
VAE는 intractable density function을 latent variable $z$를 가지고 정의하게 된다.
$p(x) = \int p(z)p(x | z) dz$
앞서 말했던 사실과 같이 complex distribution $x$에 기반한 $p(x)$ 자체를 해석하는 것은 어렵지만, 이를 구성하는 latent space $z$의 분포($p(z)$)와 조건부 $p(x | z)$는 다소 간단할 수 있다는 것이다.
VAE가 AE와 다른 점은 학습 목적이 다르다는 것이다.
autoencoder는 input $x$를 reconstruct하기 위해 decoder를 보조적으로 사용하게 되고, 실질적으로 학습하고자 하는 것은 encoder가 latent code $z$를 잘 만들게끔 하는 것이다. 따라서 feature learning에 집중한다.
그에 반해 variational encoder는 새로운 sample $x$를 만들고자 하는 목적이 크고, 실제로 간단한 random distribution인 $p(z)$를 가정하고 실제 data $x$에 기반한 latent 분포 $z$에서의 dependency modeling이 가능하다는 아이디어에서 시작되었다.

그래서 학습된 형태의 latent space를 보면 알 수 있듯이 standard autoencoder의 경우 clustering, seperation이 목적이기 때문에 feature space 상에서 굳이 각기 다른 분포끼리 연결성이 없어도 되지만, variational autoencoder의 경우 학습된 latent space를 기반으로 sampling 및 modeling을 하기 때문에 최대한 continuity를 유지하고, 전체 분포의 completeness에 초점을 맞춰 학습이 진행된 것을 볼 수 있다.

뒤에서 더 자세히 설명할 것이지만 일단 간단하게 소개하면 VAE의 loss function은 reconstruction loss와 KL-Divergence loss로 구성된다.
Reconstruction loss의 경우 주 목적은 각 카테고리(실제 데이터 상에서의 분포)를 구분하고자 하는 목적이고 KL-Divergence loss의 경우 주 목적은 latent space $z$에서의 분포가 우리가 가정하는 분포의 형태(e.g. Guassian distribution)에 따르도록 regularization하는 것이다.
따라서 각 loss의 역할을 독립적으로 보았을 때, 함께 사용한 형태의 분포가 만들어지는 이유를 직관적으로 확인해볼 수 있다.
Recall from the variational inference
$\log p(x) - D_{KL} [q(z) || p(z | x)] = E_z[\log p(x | z)] - D_{KL}[q(z) || p(z)]$
이 식을 보게 되면 일반적인 variational inference에서의 식이 된다. 즉 $p(x)$의 확률에 대해 직접적으로 알 수 없기 때문에 $z$에 기반한 확률을 $z$에 대해서 구하게 되고, 마찬가지로 $x$에 기반한 $z$의 확률 자체를 간단하게 가정하고 사용하게 된다.
수식의 앞부분을 먼저 살펴보면,
$\log p(x) - D_{KL} [q(z) || p(z | x)]$
뒤쪽의 KL divergence는 확률 분포에 따른 거리(distance)를 수치화하기 때문에 항상 0 이상이다. 따라서 수식의 뒷부분 전체를 bound로 삼을 수 있게 된다.
$E_z[\log p(x | z)] - D_{KL}[q(z) || p(z)]$
이를 ELBO(Evidence lower bound )라고 부르며, 직접적으로 확률인 $p(x)$를 최대화할 수 있는 parameter를 학습하는 것은 불가능한 영역(intractable)이기 때문에 ELBO를 최대화하여 간접적으로 data distribution에 대한 가능성을 높이는 것이다.
VAE는 각 확률 분포를 parameterized($\theta, \phi$) network를 사용하여 학습하기 때문에 이를 보다 자세히 표현하면,
$\log p_{\theta}(x) - D_{KL} [q_{\phi}(z | x) || p(z | x)] = E_z[\log p_{\theta}(x | z)] - D_{KL}[q_{\phi}(z | x) || p(z)]$
ELBO를 최대화하는 것은 총 두 가지의 optimization을 내포한다.
- Approximately maximize $p_{\theta}(x)$ —> generative model becomes better
- Minimize KLD of approximation $q_{\phi}(z | x)$ from true posterior($p(z | x)$) —> inference model becomes better
즉, 1번의 내용은 ELBO를 최대화하는 것이 간접적으로 곧 확률 분포 $x$를 최대화하는 방향이 되고, 이 과정에서 확률 분포 $x$를 생성하는 것은 $\theta$ parameterized network인 decoder이므로 generative model을 최적화하는 꼴이 된다.
그리고 2번의 내용은 ELBO를 최대화하는 과정에서 우리가 가정한 regularization term에 대해서 $z$를 모델링하는 $\phi$ parameterized network인 encoder이므로 inference model을 최적화하는 꼴이 된다.
위와 같이 정리할 수 있고, 위에서 parameterized probability가 input $x$에 대해 conditioning이 된다는 점이 곧 학습을 위한 메커니즘으로 작용하게 된다. 학습에 대한 자세한 부분은 뒤쪽에서 추가적으로 설명하고 이쯤에서 variational encoder formulation은 넘어가도록 하겠다.
Problem formulation
Maximization the probability $x$ under the entire generative process는 다음과 같이 정의해서 해결하고자 한다고 했었다.
$p(x) = \int p(z)p(x | z)dz$
수학적으로 보면 단순한 이 식에 내포된 세 가지 구현 문제가 있는데, 바로 다음과 같다.
- Latent variable $z$를 정의하는 방식
- Output distribution $p(x | z)$를 정의하는 방식
- $z$ 전체에 대해서 어떻게 적분하지?**
Solution 1 : prior $p(z)$
$p(z)$를 해결하는 것은 의외로(?) 간단하다. 바로 가장 simple한 형태의 distribution을 가정하면 되는데, 예를 들어 $z$가 $D$차원의 벡터 space 상의 한 code라고 한다면 $D$차원 각각의 한 축을 담당하는 normal distribution을 정의하면 된다.
즉, $p(z) = N(z; 0,~I)$
Solution 2 : Output distribution $p(x | z)$
결국 네트워크를 구성하는 요소에서의 $p(x | z)$에서 각 확률 분포가 conditioning 되는 애들을 분리해서 생각해보면, $x$의 분포를 정의하는 parameter는 $\theta$로 parameterized된 generator(decoder)에 의한 결과이므로 $p(x; g(z; \theta))$로 표현 가능하다.
따라서 학습 시에는 각 input $x^{(i)}$에 대한 likelihood는 $p_{\theta}(x^{(i)} | z)$를 통해 연산이 가능하고, 이를 기반으로 SGD backpropagation training을 진행한다. 그렇게 되면 학습이 끝난 후에는 새로운 $x$를 이미 학습된 $\theta$에 기반한 decoder에 대해서 $p_{\theta}(x | z)$로부터 생성할 수 있게 된다.

Solution 3 : Integration over $z$
이 부분에서 아이디어가 되는 부분은 non-zero $z$ 영역에 대해서만 더하자는 것이다.
실제 확률 분포 $z$전체를 더하는 것은 불가능하기 때문.
$p(x) = \simeq \frac{1}{n} \sum_{i=1}^n p(x | z_i)$
간단하게 생각해보면 많은 $z$를 샘플링하고, 이를 토대로 생성한 $x$ 데이터 전반에 걸쳐 평균을 내면 $x$의 분포를 효과적으로 학습해낼 수 있지 않을까? 싶지만.. 보통 high dimensional space에서의 이런 sample mean은 dimension에 따라 그만한 양의 방대한 sampling을 요구하게 되고, 현실적으로 연산이 불가능한 것을 알 수 있다(Monte-Carlo sampling).
그렇기 때문에 실질적으로 $p(x |z) \simeq 0$ for most of $z$를 활용하게 된다.
우리가 가지고 있는 데이터를 기반으로 한 $q(z | x)$를 활용하고자 한 것이 바로 그 이유이며, exact posterior $p(z | x)$ 대신 알고 있는 $x$에 기반한(conditioned) $z$ distribution을 활용하고자 한 것이 VAE 전체 구조의 이유가 된다.
Baye’s Rule에 따르면 posterior $(p(z | x)) = \frac{p(x | z)p(z)}{p(x)}$ 인데, 여기서 $p(x)$가 intractable한 것은 여전하므로 불가능하다는 것. 그렇기에 approximate posterior $q(z|x) \simeq p(z| x)$를 학습하고자 한 것이다.
즉, 위에서 간단하게 설명했던 바와 같이 두 분포를 서로 유사하게 가져가는 과정에서 정의되는 ELBO(Evidence Lower Bound)를 최대화하기 위한 학습을 하게 된다. 다만 variational inference 자체가 closed form 연산이기 때문에 이를 계산하는 것이 어렵다는 문제가 제기된다.
그렇기 때문에 differentiable inference가 가능한 ‘Encoder network’를 네트워크에 연결해서 학습하게 된 것이다($f(x; \phi)$). 이번에는 네트워크를 구성하는 요소에서의 $q(z | x)$에서 각 확률 분포가 conditioning 되는 애들을 분리해서 생각해보면, $z$의 분포를 정의하는 parameter는 $\phi$로 parameterized된 encoder에 의한 결과이므로 $q(z; f(x; \phi))$로 표현 가능하다.
$f(x; \phi)$로 parameterized된 분포는 gaussian으로 가정하며, 각 dimension 축은 서로에 독립적일 수 있도록 standard deviation이 diagonal하게 정의된 covariance matrix $\Sigma$ 로 제한한다.
당연한 결과겠지만 학습이 끝난 후 $z$는 학습된 parameter를 기반으로 한 normal distribution으로부터 sampling을 진행한다.

전체 구조는 위와 같다.
Training
학습에 대한 자세한 내용은 뒤에서 언급한다 하고 variational inference에 대해 간단하게 소개 후 넘어왔다.
$\log p(x) = E_{z\sim q(z|x)}[\log p(x)]$
$= E_{z}[\log \frac{p(x|z)p(z)}{p(z|x)}]$
$= E_{z}[\log \frac{p(x|z)p(z)}{p(z|x)} \frac{q(z|x)}{q(z|x)}]$
$= E_z [\log p(x|z)]-E_z [\log \frac{q(z | x)}{p(z)}] + E_z [\log \frac{q(z | x)}{p(z | x)}]$
앞서 소개했던 것과 같이 이를 intractable한 부분과 tractable한 부분으로 나눈 것이다. 이를 앞에서 잠깐 언급했던 것과 같이 식을 바꾸게 되면,
$=E_z[\log p_{\theta}(x | z)] - D_{KL} [q_{\phi}(z | x) || p(z)] + D_{KL} [q_{\phi}(z | x) || p(z | x)]$
위와 같이 정리되고, 이를 각각 tractable한 ELBO :
$E_z[\log p_{\theta}(x | z)] - D_{KL} [q_{\phi}(z | x) || p(z)]$
그리고 intractable한 KL divergence
$D_{KL} [q_{\phi}(z | x) || p(z | x)]$
의 두 부분으로 분리할 수 있다.
즉, 우리는 VAE 학습 과정에서 $\phi$와 $\theta$로 parameterized된 네트워크를 ELBO를 maximize하는 형태로 학습을 진행할 것이다.
$\log p(x) \geq E_{z\sim q_{\phi}(z | x)}[\log p_{\theta}(x | z)] - D_{KL} [q_{\phi}(z | x) || p(z)]$
reconstruction term이 앞부분에 해당되고, regularizer(gaussian 형태로 제한)하는 부분이 뒤에 붙게 된다.
Regularizer 부분이 $\phi$로 parameterized된 encoder를 학습하는 term이 될 것이고, reconstruction term이 $\theta$로 parameterized된 decoder를 학습하는 term에 해당될 것이다.
How to backpropagation from the sampling node?
여기서 문제가 하나 생기는데, 이는 바로 sampling하는 부분에 대한 문제다.
앞서 그림을 통해 보여준 구조를 보면 알 수 있지만 encoder와 decoder 각각이 내보내는 결과값은 distribution을 가정한 mean($\mu$)와 covariance matrix($\Sigma$)일 뿐이고, 여기서 sampling을 하게 된다. 따라서 ELBO를 하나의 loss 기준으로 삼았을 때 Encoder output을 통해 sampling을 하는 과정 자체가 deterministic하지 않기 때문에 미분이 불가능하다는 문제가 생긴다. 그렇다면 학습하기 위해 gradient를 흘려보낼 수 없는데, 이를 어떻게 해결할까?
Encoding objective
인코딩 목적함수를 보면 다음과 같다.
$D_{KL} [q_{\phi}(z | x) || p(z)]$
일반적으로 가정을 하고 들어가는 부분이 있기 때문에 이를 간단하게 표현하면,
$D_{KL} [N(\mu_0, \Sigma_0) || N(\mu_1, \Sigma_1)]$
$= \frac{1}{2}(tr(\Sigma_1^{-1} \Sigma_0+(\mu_1-\mu_0)^T \Sigma_{1}^{-1}(\mu_1-\mu_0)-K+\ln (\frac{\det \Sigma_1}{\det \Sigma_0})))$위와 같이 표현할 수 있고, VAE에서는 이를 simplify하게 된다. 왜냐하면 각 dimension에 따르는 분포들을 서로 독립적으로 가정하기 때문
$= \frac{1}{2}(tr(\Sigma (x)) + \mu (x)^T \mu (x) -K -\ln \det \Sigma (x))$
$= \frac{1}{2} (\sum_{k=1}^{K} \sigma_k^2(x)+\sum_{k=1}^K \mu_k^2(x)-\sum_{k=1}^K 1 - \ln \prod_{k=1}^K \sigma_k^2(x))$
위의 식은 미분이 가능한 형태이기 때문에 gradient descent를 사용 가능하다.
Decoding objective
디코딩 목적함수를 보면 다음과 같다.
$E_z[\log p_{\theta}(x | z)]$
우리는 이를 직접적으로 구하지 않고 Monte Carlo sampling을 각 input $x^{(i)}$에 따라 진행할 것이다. 이를 바로 식으로 표현하면,
$E_z\sim q_{\phi}(z | x)[\log p_{\theta}(x^{(i)} | z^{(i, l)})] \simeq \frac{1}{L} \sum_{l = 1}^L \log p_{\theta} (x^{(i)} | z^{(i, l)})$이고 SGD에서는 sampling $L = 1$로 잡는다.
그러나 실제로 parameter $\phi$를 학습시키기 위해서는 reparameterization trick을 사용해야 한다.

이를 우선 간단하게 그림으로 표현하면 위와 같은데, $\phi$로 학습된 encoder가 $z$ sampling을 위한 parameter를 리턴하고, 이를 기반으로 샘플링하는 stochastic한 과정을 input 영역으로 내려버리는 것이다. 이를 바로 $\epsilon$으로 표현하고, 이 부분에서는
$\epsilon \sim N(0,~I)$를 샘플링하고 여기에 구한 parameter를 곱해서 scaling 및 biasing을 진행하면 원래 구현했던 것과 동일한 효과를 낼 수 있는 것이다. 즉 denormalization 과정이라고 생각하면 될 듯
출처 : https://www.youtube.com/watch?v=cUyhMyPqkpU&ab_channel=서울대딥러닝
'Multimodal' 카테고리의 다른 글
| [논문 리뷰] Zero-Shot Learning Through Cross-Modal Transfer (0) | 2022.07.23 |
|---|
