
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- cv
- 자연어처리
- VIT
- YAI 10기
- 강화학습
- PytorchZeroToAll
- Googlenet
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- Fast RCNN
- RCNN
- YAI
- YAI 11기
- rl
- CS224N
- GaN
- CNN
- CS231n
- 컴퓨터 비전
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- YAI 8기
- YAI 9기
- Perception 강의
- cl
- Faster RCNN
- NLP
- transformer
- 연세대학교 인공지능학회
- 3D
- 컴퓨터비전
- nerf
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] Zero-Shot Learning Through Cross-Modal Transfer 본문
Zero-Shot Learning Through Cross-Modal Transfer
Socher, Richard, et al. "Zero-shot learning through cross-modal transfer." Advances in neural information processing systems 26 (2013).
* YAI 9기 박준영님이 Multimodal팀에서 작성한 글입니다.

논문 소개
Multimodal 연구에 있어 zero-shot learning에 대한 가능성을 연구한 논문이다. 사실상 성능이 그리 뛰어나지도 않고 zero-shot이 가능한 class에 대해서도 제약조건이 걸리지만, 단순히 image feature를 word vector, language manifold로 옮겨, image와 text modality(여기서는 text라고 하기에는 단순히 class에 대한 부분이지만)가 서로 고차원의 공간 상에서 유의미한 mapping을 가질 수 있는 사실을 보여주었다.
Abstract를 읽어보면 알 수 있지만 간단히 요약해보자면 해당 모델은 10개의 class를 가지는 CIFAR-10에 대해 실험을 진행했으며, $n$개의 training sample을 가지는 class와(seen class, observed class) $10-n$개의 zero-shot class(unseen class)에 대한 성능을 보여준 실험이다.
Introduction
zero-shot learning은 사람이라면 당연히 가지고 있는 능력이다. 최근에 나온 제품이라던지, 아니면 특성 상황에 놓여 한 번도 보지 못했던 물체가 있을 것이다. 물론 아무런 정보 제공 없이 단순히 zero-shot learning은 사람도 거의 불가능한 수준이지만, 만약 특정 물체에 대한 설명이 주어지고 나서 그 설명에 부합하는 형태의 예시가 주어진다면, 사람은 이를 구분할 수 있을 것이다.
예를 들어 다음과 같은 설명을 듣고 이에 부합하는 물체를 골라보자.
“이 물체는 두 개의 바퀴가 달려있으며, 자체적으로 균형을 유지하는 전자 vehicle입니다. 중간에는 제어하는 막대기가 있습니다. 당신은 이 물체 위에 서서 막대기를 움직이며 조종할 수 있고, 이를 통해 돌아다닐 수 있습니다.”






위의 설명을 보고 Segway를 고르지 않는 사람은 없을 것이다. 우리에게는 너무나도 당연한 추론 과정을 해당 논문에서는 네트워크로 하여금, natural language를 토대로 처음 보는 물체나 이미 봤던 물체에 대해 비교적 정확하게 예측하는 모델을 제안하고자 한다.
- 가장 먼저, 이미지를 semantic space of words로 mapping하는 과정을 neural network 학습을 통해 구현한다. Word vector는 각 distribution에 따른 유사도를 내포하게 되고, 해당 네트워크를 학습하는 과정을 통해 visual modality와 word vector 사이의 접지가 생긴다.
- Classifier 자체가 test image를 학습된 example에 기반하여 mapping을 하게 되므로, outlier(unseen data)를 구분하는 작업 또한 학습이 된다. 만약 training data가 있었던 class에 해당되는 이미지라면 classifier를 일반적인 형태의 supervised-learning을 통한 image classification model에서의 분류기와 동일하게 보면 되고, 그렇지 않은 경우라면 unseen category에 대한 class를 학습된 확률 분포에 따라 할당하게 된다.
그래서 모델 구조를 간단하게 그림으로 나타낸 것이 다음 그림과 같다.
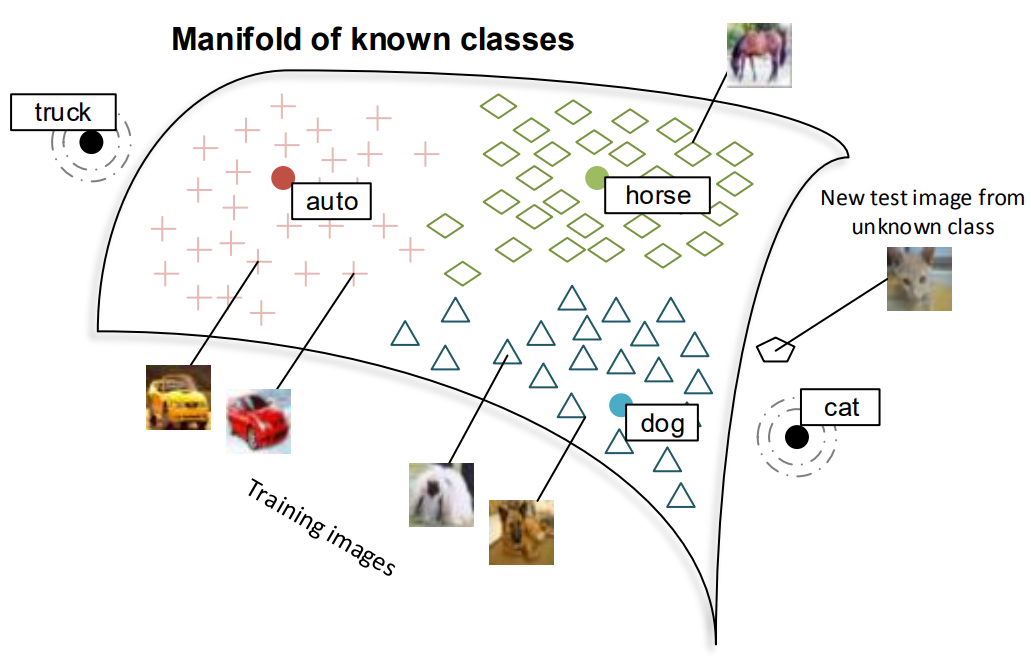
CIFAR-10 dataset class인 airplane, automobile, bird, cat, deer, dog, frog, horse, ship, truck 중에서 training dataset을 사용하지 않는 class는 cat과 truck이다. 이 두 class를 고른 이유는 뒤에서 모델을 구성하기 위한 brain-storming 과정과 함께 설명할 것이다.
이 논문이 기존 방식과 다른 점은 이전 연구는 zero-shot learning을 진행할 때 zero-shot task를 진행하는 class 사이에서 구분짓는 단순한 작업을 하는데 있었다. 그러나 이 논문에서는 training data가 존재하는 class와 training data가 없는 class 사이의 유기적인 학습 과정을 통해 known class에 대한 성능과 함께 unseen class에 대해서도 꽤 좋은 성능을 보여주었다.
Related Work
이 논문을 제대로 읽기 전에 related work 5가지를 짚고 넘어가는게 사실상 가장 중요할 것 같다. 차례대로 이해를 하고 넘어가보도록 하자.
Zero-Shot Learning
위에서도 설명하고 넘어왔지만, 이 논문과 가장 유사하면서도 다른 것이 바로 Palatucci, Mark, et al. "Zero-shot learning with semantic output codes." Advances in neural information processing systems 22 (2009). 요 논문이다. 이 연구에서는 사람들이 특정 단어를 생각하는 상황에서의 fMRI scan image를 manually designed feature space로 mapping 한다. 이를 통해 fMRI scan이 없는 단어에 대해서도 semantic feature를 추출할 수 있으며, 이를 통해 zero-shot class에 대한 differentiating이 가능하다는 연구였다. 그러나 이 연구의 경우 단순히 새로운 이미지가 새로운 것이든 원래 알고 있던 것이든 관계없이 semantic code를 리턴할 수 있다는 것일 뿐, 이 이미지가 unseen class인지 seen class인지 알 수 없다는 문제가 있다.
One-Shot Learning(Few-Shot Learning)
논문에서는 One-Shot Learning으로 소개했지만 디테일한 내용은 Few-Shot Learning과 맥락이 맞아서 이를 통해 확인하도록 하겠다. Zero-Shot Learning과 Few-Shot Learning의 다른 점은 Zero-Shot은 아예 training data가 전무한, 즉 학습한 네트워크가 한 번도 보지 못한 class에 대한 inference가 되고 Few-Shot은 training data를 아주 조금 본 상태의 네트워크가 해당 class에 대한 inference를 진행하는 것이다. 이 논문과 비슷한 형태의 연구에서는 low-level image feature를 학습하는 과정에서 probabilistic model을 토대로 knowledge transfer를 진행한다.
Knowledge and Visual Attribute Transfer
그래서 대체 Knowledge transfer가 뭔데(?)라고 할 사람이 있을 것 같아서 바로 밑에서 related work로 knowledge transfer를 넣어두셨나보다. 암튼 Knowledge 및 Visual attribute transfer를 간략하게 설명하자면, 학습되거나 manually designed feature 및 attribute를 다른 instance에 적용하는 것이다. 예를 들어 강아지 이미지에 대한 학습된/만들어진 형태의 특성이 존재하고, 이를 만약 한 번도 관찰하지 못한 고양이 이미지에 대해 적용할 수 있다.
Domain Adaptation
Domain adaptation은 한쪽 domain에는 학습 가능한 데이터의 수가 많은데, 다른 domain에서는 없는 경우에 활용될 수 있다. 예를 들어 영화 리뷰에 대한 분류기를 학습하였는데, 이를 책 리뷰에 대한 분류기로 adaptation하는 것이다. 그러나 각 domain에 있어서 feature가 다를 수 있다는 점이 이 연구와는 맞지 않는다.
Multimodal Embeddings
Multimodal embeddings는 말 그대로 여러 source의 modality를 한 공간 내에서 정보로서 관련짓는 과정이다. 여러 source modality는 음성+영상이 될 수도 있고 혹은 이미지+캡션(텍스트)가 될 수도 있다. 이전에 리뷰했던 Restricted boltzmann machine을 활용한 multimodal deep network의 경우에도 두 modality의 정보를 알지 못하는 latent 공간 상에서 융합할 수 있는 형태의 연구를 진행했던 것을 생각해볼 수 있다.
Word and Image Representations
핵심이 되는 두 modality인 image와 text(word)에 대한 manifold learning을 위해서 각 modality의 representation이 필요한데, 이 과정에서는 기존 연구에서의 unsupervised method를 활용하였다. Word vector representation에는 pre-trained 50-dimensional word vector를 내보내는 모델을 활용하였는데, 이 모델의 경우 Wikipedia text를 활용, 실제로 각 word가 context 내부에서 얼마나 나오는지 예측하는 과정을 통해 unsupervised learning을 진행한다. 이러한 distributional approach가 실제로 NLP task에서 sense disambiguation(중의성 해소), thesaurus extraction(동의어 추출), cognitive modeling(인지 모델링)에 효과적인 것을 알 수 있다.
이미지에 대한 feature는 마찬가지로 unsupervised method에 따라 raw pixels로부터 $F$ image features를 추출하게 된다. 이를 통해 각 이미지는 representation vector $x \in R^F$로 표현 가능하다.
Projecting Images into Semantic Word Spaces
Image class와 image 사이에 semantic relationship을 학습시키기 위해서 image feature를 50 차원으로 project하는 과정이 필요하다. Training 및 Testing 과정에서 class 집합인 $Y$를 정의하고, 이 중 일부는 training data를 가지고 있고 나머지는 가지고 있지 않다고 하자. Seen class를 $Y_s$, unseen class $Y_u$에 대해 $W = W_s \cup W_u$는 seen 및 unseen visual class 모두에 대한 word distributional information(word vector)라고 하자.
모든 training sample 이미지 $x^{i} \in X_y$($y \in Y_s$)는 모두 특정 과정을 통해 word vector $w_y$로 바뀌게 되고, 이는 class name에 따른 word vector일 것이다. 이러한 과정을 parameterized network$(\Theta)$로 학습하는 과정에서의 목적함수는,
$$J(\Theta) = \sum_{y \in Y_s} \sum_{x^{(i)} \in X_y} \parallel w_y-\theta^{(2)}\tanh ( \theta^{(1)} x^{(i)} )\parallel^2$$
여기서 $\theta$는 학습 가능한 형태의 weight matrix이고, 그 크기는 $\theta^{(1)} \in R^{h \times F}$, $\theta^{(2)} \in R^{50 \times h}$이다. image 자체를 word vector 공간 상으로 mapping하는 형태의 학습을 통해 word semantics를 visual grounding과 내재적으로 연관짓는 형태로 optimize된다.

실제로 t-SNE 방식을 통해 50 dimensional word vecotr space를 2차원 공간 상에서 clusterring된 형태를 보면, 실제로 학습 방향은 이미지를 토대로 word vector로 매핑하는데, 유사한 형태의 class는 space 상에서 거리가 가까운 것을 알 수 있다. 예를 들어 unseen data인 ‘cat’은 ‘dog’와 가깝고 전혀 관계없는 ‘airplane’ 등과 멀지만, ‘truck’은 ‘ automobile’과 가깝고 ‘horse’와는 먼 것을 확인할 수 있다.
Zero-Shot Learning Model
앞서 사용했던 notation을 기반으로 설명하면, test set $x \in X_t$를 조건부로 가지는 seen/unseen class $y(y \in Y_s \cup Y_u)$를 예측하는 과정이다. 따라서 이를 식으로 표현하게 되면 $p(y | x)$이다.
궁극적으로 원하는 바는 위의 확률 분포를 학습하면서 image가 mapping된 semantic vector space $f \in F_t$를 얻는 것이다.
그런데 단순히 위의 식을 최적화한다고 생각하면 seen class/unseen class에 대해서는 구분할 수 없기 때문에, 여기서 새로운 binary random variable $V \in { s, u }$를 주어 이를 기반으로 조건부를 설계하게 된다.
$$\begin{aligned}&p(y | x,X_s,F_s,W,\theta) \ &= \sum_{V \in { s, u }} P(y | V,x,X_s,F_s,W,\theta)P(V | x,X_s,F_s,W,~\theta)\end{aligned}$$
variable $V$로 marginalize함으로써 먼저 seen/unseen class를 구분할 수 있게 된다. 이를 통해 seen class라면 SOTA softmax classifier가 되고, unseen class라면 simple Gaussian discriminator가 될 것이다.
그럼 여기서, image가 주어졌을 때 해당 이미지가 seen class에 속하는 친구일지, 아니면 unseen class에 속하는 이미지일 지 판단하는 상황에서의 전략을 조금 더 구체적으로 살펴보도록 하자.
“만약 ‘고양이’ 사진이 있다고 가정하면, ‘고양이’와 ‘강아지’ 사진이 유사한 것보다는 word vector 상에서는 어느 정도 가깝다고 가정하더라도 그렇게까지 가깝지는 않을 것이다.”
이 말인 즉슨, unseen class에 속하는 이미지가 같은 semantic region에 놓이기는 하지만 training sample로 학습된 seen class와는 어느 정도 거리를 유지할 것이라는 소리이다.
따라서, 바로 위에서 언급한 전략을 testing에서 활용하는 것이 outlier detection method이며, 이를 통해 image가 seen class에 속할지, 아니면 unseen class에 속할 지 결정할 수 있는 기준이 될 수도 있다.
Outlier Detection
Outlier detection에는 두 가지 전략을 생각해볼 수 있다. 두 전략은 모두 semantic word space에 mapping된 manifold를 기준으로 하며, 해당 manifold에는 수많은 학습 데이터들이 mapping된 $f$ 벡터들이 모여있을 것이다. 각 이미지는 서로 독립적인 확률 분포를 가정하기 위해 isometric and class specific Gaussian을 따른다고 하자. 그렇게 되면 seen class에 속하는 $y \in Y_s$에 대해서, 우리는 $P(x | X_y, w_y, F_y, \theta) = P(f|F_y, w_y) = N(f|w_y, \Sigma_y)$
와 같이 정규화가 가능하다. 각 class 별 가우시안은 그에 따른 semantic word vector $w_y$에 따라 parameterized되는데, 이는 해당 라벨이 mapping된 training point를 기준으로 covariance matrix $\Sigma_y$와 평균으로 정해지게 된다. 이러한 상황에서 새로운 이미지 $x$가 들어왔을 때 outlier detection은 다음과 같은 조건 식을 따르게 된다.
$$P(V = u|f, X_s, W, \theta ) := 1\{\forall y \in Y_s : P(f|F_y, w_y) < T_y\}$$
위의 식이 의미하는 바는 새로운 input image $x$가 manifold에 mapping된 $f$를 기준으로 보았을 때, 학습된 manifold 상의 $F_y$와 semantic word vector $w_y$가 어떠한 probability map을 그리고 있을 테고, 그 위에 놓이게 될 것인데, 만약 seen class($Y_s$)에 속하는 모든 $y$에 대해서 특정 Threshold 값보다 작게 되면 새로운 input image $x$는 seen class 그 어떤 것에도 속하지 않는다고 판단, 즉 $V=u$라는 결론을 내리게 되는 것이다.
간단하게 풀어서 설명하자면
$$P(V = u) = \begin{cases}1,&\text{for all seen class, } T_y \text{보다 작은 확률 값을 가지는 경우} \\0,&T_y\text{보다 크거나 같은 확률 값의 class 있을 경우} \end{cases}$$
그러하다.
일단 그런데 여기서 또 하나 짚고 넘어가야 할 점이 보일텐데, 그럼 도대체 확률 값에 대한 Threshold인 $T_y$는 어떤 기준으로 정해야할까에 대한 논의이다. 너무 작게만 설정하면 unseen data가 들어왔을 때의 zero-shot 성능이 좋지 않을 것이고, 너무 크게만 설정하면 seen data가 들어왔을때 unseen data로 처리해버릴 것이기 때문이다.
그렇다면 생각해볼 수 있는 것은 training data로 학습된 실제 probability manifold를 활용하여 threshold를 정하는 것이다. 이러한 방법을 사용하면 seen class에 대한 정확도를 유지할 수 있게 된다. 여기서, test image는 전혀 사용하지 않고 판단을 하게 되는데, 이는 단순히 생각해서 zero-shot learning에 test image를 사용하는 순간 이미 확률 분포 상에 training point로 자리잡기 때문에 outlier로 처리하지 않게 된다.
이와 같은 metric에 사용한 parameter는 nearest neighbors의 수인 $k = 20$, 그리고 standard deviation의 multiplier인 $\lambda=3$가 있다. $\lambda$가 크면 클수록 outlier로 취급되기 위해서 확률분포의 중심으로부터 멀어져야하는 거리가 멀어진다고 생각하면 된다.
각 point $f \in F_t$에 대해, seen categories에 속하는 training set에 있는 $k$개의 nearest neighbors에 의한 context set $C(f) \subseteq F_s$를 정의하자. 그렇게 되면 probabilistic set distance(pdist)를 $C(f)$에 속하는 각 point $x$에 대해서 정의할 수 있게 된다.
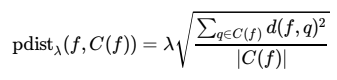
해당 논문에서는 distance function $d(\cdot)$에 대해 Euclidean distance를 활용했다고 한다. 이제 이 pdist를 활용하여 local outlier factor(lof)를 정의하면,
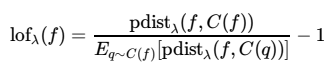
즉, 큰 값을 가지는 lof는 outlier일 가능성을 높이게 된다. 그러나 lof value 자체는 probability 값이 아니기 때문에, normalization factor가 필요하고 이 normalization은 seen class의 training set에 기반한 lof value의 standard deviation과 같이 작용할 것이다.
$$Z_\lambda(F_s) = \lambda \sqrt{E_{q\sim F_s}[(\text{lof}(q))]^2}$$
이를 토대로 Local outlier probability를 다음과 같이 정의할 수 있다.
$$LoOP(f) = \max{ \left[ 0, \text{erf}\left( \frac{\text{lof}_\lambda(f)}{Z_{\lambda}(F_s)} \right) \right]}$$
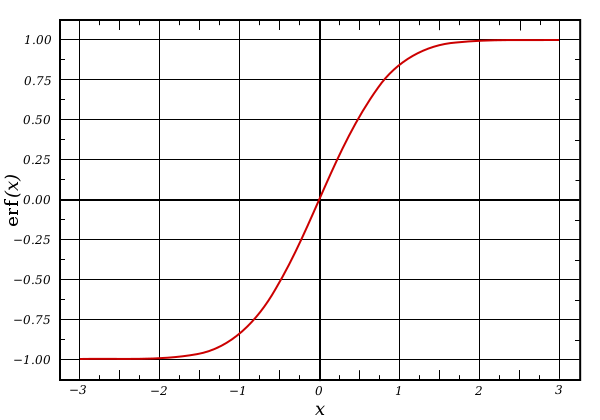
erf는 흔히 알고 있는 gaussian error function이다.
$$erf(x) = \frac{2}{\sqrt{\pi}}\int_0^x{e^{-t^2} dt}$$
Experiment
실험에서는 CIFAR-10 dataset을 사용했으며 10개의 class 중에서 8개는 seen class, 2개는 unseen class로 취급한다. 각 class 별로 5,000개의 $32\times 32 \times 3$의 RGB 이미지가 있다. Image embedding(feature vector라고 논문에 명시)를 추출하기 위해서 사용한 feature extraction 방법은 12,800 (3,072 → 12,800) dimension으로 뽑아낸다고 한다. Word vector는 50-dimensional word vector를 뽑아내게끔 한다.
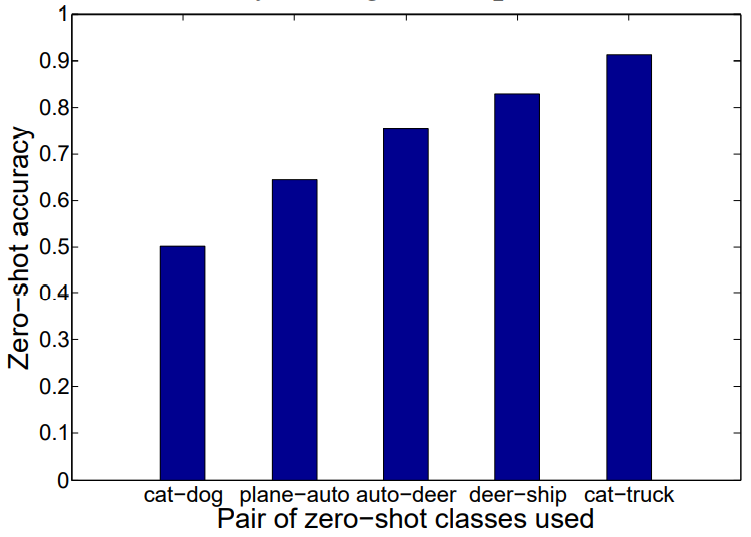
실험을 진행하는데 있어서 8개의 seen class에 대한 accuracy 및 2개의 unseen class에 대한 zero-shot accuracy를 모두 보았는데, 결과로 보자면 seen class에 대한 정확도 자체가 82.5%로 기존 SVM-based classification 결과와 거의 유사하게 나왔다고 한다.
여기서 사용된 class는 cat, truck을 제외한 8개의 class이다. zero-shot learning 에 대한 내용의 경우, 위에서 과정을 설명했던 것과 같이 unseen class에 대한 거리와 semantic space에 mapping된 거리를 기준으로 결정하게 되는데, 이 때 그래프에서 보는 것과 같이 유사한 데이터셋이 학습에 활용된 경우에 성능이 가장 좋았다.
예컨데 cat/dog 두 class가 모두 학습에서 배제된 경우에는 성능이 좋지 않았는데, cat/truck이 학습에서 배제된 경우에는 고양이와 유사한 ‘dog’는 학습에 활용되었기 때문에 better performance를 보여주는 것을 확인할 수 있다.
Influence of novelty detectors on average accuracy
다음으로 조사할 부분은 seen 및 unseen classification 모두에 대해서 얼마나 정확도가 잘 나오는지 확인하는 것이다. 위에서 설명한 실험의 경우에는 두 task를 따로 보았을 때의 경우이다.
따라서 이 실험에서는 seen class라면 softmax classifier를 통과하거나, unseen class라면 nearest semantic word를 찾는 classifier를 통과하는 결과에 대한 performance를 측정하였다.
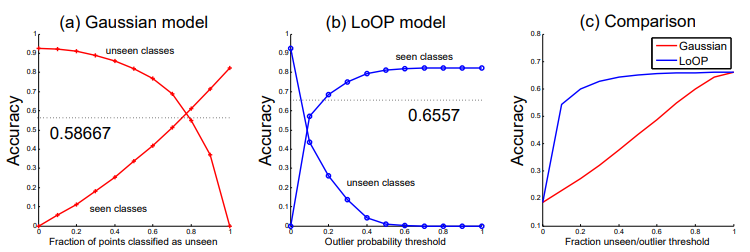
모든 test image는 class 별로 동일한 개수를 통해 accuracy를 측정하였고, 그래프는 seen class에 대한 그래프와 unsen class에 대한 그래프를 따로 그리게 되었다.
곡선의 가장 좌측을 보게 되면 Gaussian model의 경우 모든 test image를 unseen으로 처리하고, LoOP model은 probability threshold를 0으로 잡은 상태임을 보여준다. 이 부분에서는 test set에서 모든 unseen class에 해당되는 data는 제대로 classify되기 때문에 정확도가 높다. 그리고 가장 우측을 보게 되면, 이번에는 반대로 모든 image가 seen으로 처리되기 때문에 seen class에 해당되는 정확도가 높게 나온다.
그래프를 보면 gaussian model과 LoOP model의 accuray falling rate이 다른데, 일반적으로 gaussian model의 경우 image를 unseen class로 지명하기에 용이하며, 반대로 LoOP는 zero-shot image에 high outlier probability를 주지 않는다. 이는 zero-shot image들도 seen images 상의 manifold 근처에 떨어지기 때문이다. 따라서 LoOP를 사용하게 되는 경우는 seen class에 대한 성능을 유지하되, zero-shot accuracy도 어느 정도는 얻고 싶을 때이다. 실제로 정확도를 비교한 세 번째 그래프를 보면, zero-shot image에 대해서 깐깐하게 판단하는 LoOP model 자체는 overall accuracy가 높게 나오는 것을 알 수 있다. 이는 사실 seen class와 unseen class 간의 차이에서 비롯된 결과일 수도 있다.
결국 이 실험에서 완수하고자 하는 목적은 full bayesian pipeline을 한 모델로 해결하는 것이다.
$$p(y|x, X_s, F_s, W, \theta) = \sum_{V \in {s,u} } P(y|V, x, X_s. F_s, W, \theta) P(V|x, X_s, F_s, W, \theta)$$
바로 앞서 소개했던 $V$로 marginalize한 식이다. LoOP 모델은 각 이미지 instance에 대해 outlier일 확률을 return한다. Gaussian threshold model은 log probability에 대해 cutoff fraction을 tuning하게 된다. 바로 이 tuning 작업이 상단에서 설명한 그래프 중 (c)의 가로축에 해당된다.
'Multimodal' 카테고리의 다른 글
| [논문 리뷰] Variational AutoEncoder(VAE) (0) | 2022.07.23 |
|---|
