
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- YAI 9기
- GAN #StyleCLIP #YAI 11기 #연세대학교 인공지능학회
- YAI
- cl
- PytorchZeroToAll
- 컴퓨터 비전
- Googlenet
- 3D
- CNN
- Fast RCNN
- YAI 11기
- nerf
- CS231n
- CS224N
- Faster RCNN
- Perception 강의
- YAI 10기
- 컴퓨터비전
- VIT
- YAI 8기
- RCNN
- GaN
- NLP
- cv
- 연세대학교 인공지능학회
- rl
- NLP #자연어 처리 #CS224N #연세대학교 인공지능학회
- transformer
- 자연어처리
- 강화학습
- Today
- Total
연세대 인공지능학회 YAI
[논문 리뷰] Transformer 본문
Transformer
* YAI 9기 윤수진님이 창의자율과제 NLP팀에서 작성한 글입니다.
논문 소개
- Attention Is All You Need
- Transformer, 고려대학교 산업경영공학과 일반대학원 Unstructured Data Analysis, Youtube
- The Illustrated Transformer, Jay Alammar, Github
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
The Illustrated Transformer
Discussions: Hacker News (65 points, 4 comments), Reddit r/MachineLearning (29 points, 3 comments) Translations: Chinese (Simplified), French 1, French 2, Japanese, Korean, Russian, Spanish, Vietnamese Watch: MIT’s Deep Learning State of the Art lecture
jalammar.github.io
Introduction
- RNN처럼 순차적 데이터를 처리하지 않음, 한꺼번에 처리
- Model that uses attention to boost the speed with which these models can be trained and easy to parallelize
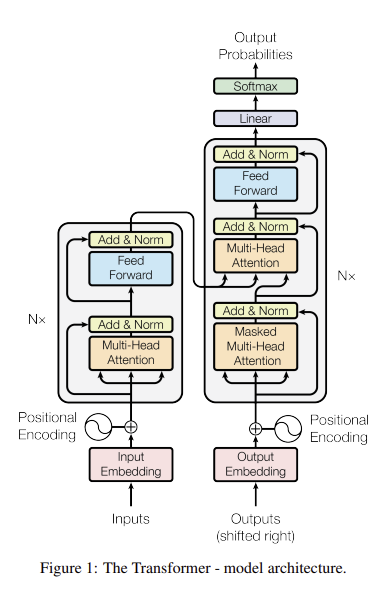
- Encoding component와 decoding component, 그리고 연결
- Encoding component : Encoder의 stack, 논문에서는 6개를 쌓음
Decoding component : Decoder의 stack, 마찬가지로 6개
→ seq2seq와 달리 반복적 수행
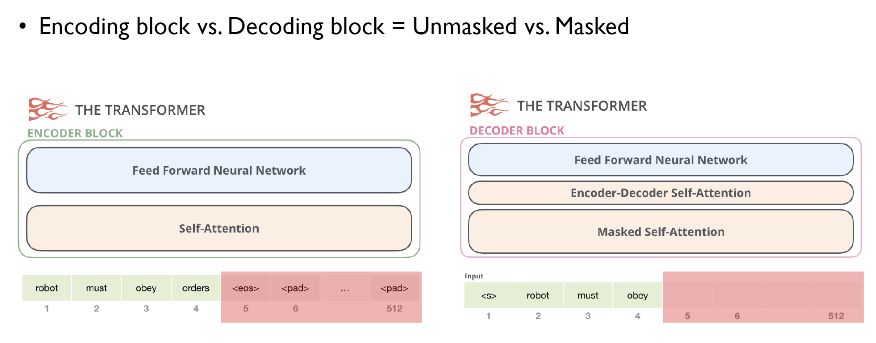
512개의 token활용, 문장이 더 짧으면 padding
Main
Encoder
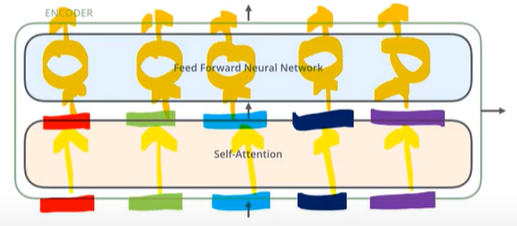
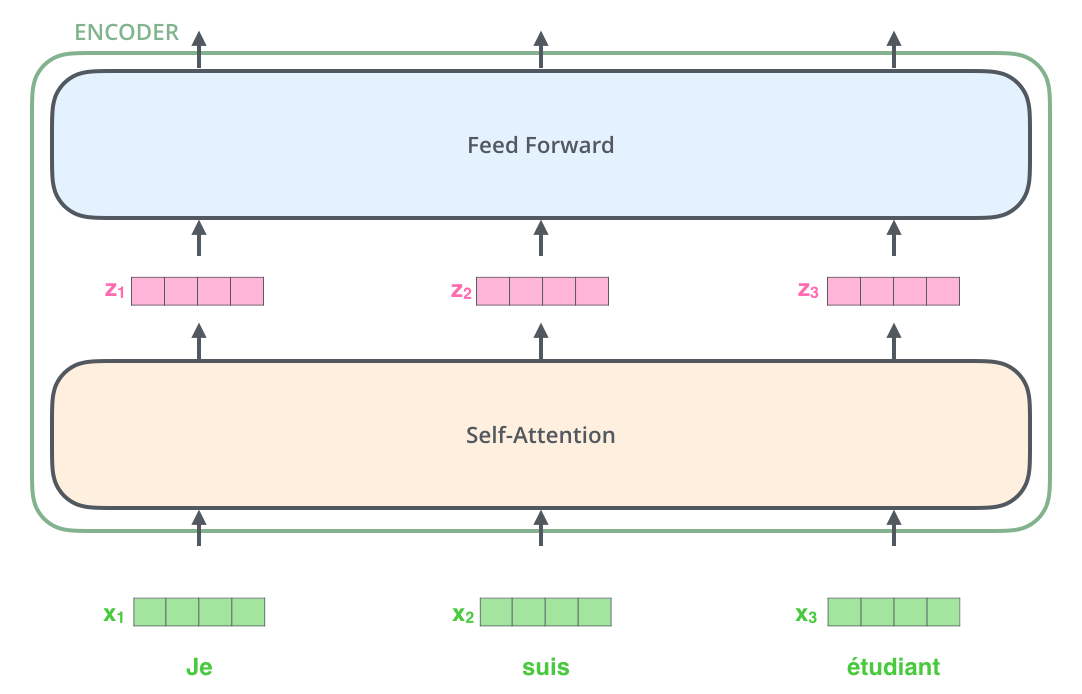
- 각각 입력된 문장내 단어간의 관계를 보여주는 self-attention layer와 모든 단어들에 동일하게 적용되는 fully connected feed-foward layer
- 순차적 X, 한번에 모든 sequence를 사용하는 unmasked
- 각각의 encoder는 구조관점에서 모두 동일한 구조 → 가중치를 share하는 것은 아님
- 각 encoder는 self attention layer와 fully connected feed-foward layer로 구성
- self attention layer
- self-attention layer는 다른 단어를 참고해 각 단어의 vector들끼리 서로간의 관계가 얼마나 중요한지 점수화한다 (a layer helps the encoder look at other words in the input sentence as it encodes a specific word)
- fully connected feed-foward layer
- self attention layer의 결과물이 input으로 들어가게됨
- 각 position에 대해 feed forward network이 한번에 적용되는 것이 아닌 각각 한번씩 적용되어 output이 나오게됨
Decoder
- encoder layer의 두개의 sublayer에 더해서 세번째 sublayer인 Encoder-decoder attention layer가 두 layer 사이에 들어가 있음
- Encoder-decoder attention layer : 최종 output을 생성할때 encoder에서 넘어온 정보를 어떻게 활용할 것인지 연산하는 layer
- 순차적인 처리가 필요, Masked self attention
- s 토큰으로 인해 마지막 단어가 masked
N = 6
1. Input Embedding : 처음에 들어갈 정보에 대한 vector
- The embedding only happens in the bottom-most encoder : 제일 첫번째 encoder의 입력으로써 사용됨
- Word2vec, fasttext, globe와 같은 embedding algorithm활용
- common to all the encoders is that they receive a list of vectors each of the size 512
- (512차원의 word embedding : 단어 1개)
- 가장 아랫단의 encoder에만 word embedding이 input으로 들어가게되고, 윗단의 encoder들은 바로 아래 encoder의 output을 input으로 받음
- The size of this list is hyperparameter we can set – basically it would be the length of the longest sentence in our training dataset.
- (리스트 자체도 파라미터, 한 시퀀스의 길이를 최대 몇개로 가져갈 것인가 → 가장 긴 문장의 단어수나 상위 95%에 해당하는 단어 수) (512차원 여러개가 모여 문장 하나)
2. Positional Encoding : 어떤 단어가 몇번째 위치에 있는지에 대한 정보
- input embedding에 positional encoding을 더함(그대로 옆에 이어 붙이는 concat과는 다름!)
- input embedding 512차원 + positional encoding 512차원 합 ⇒ 512차원
- 각각의 input embedding에 더해지는 vector

- transformer는 한번에 모든 sequence를 입력받아 단어의 위치정보를 고려하지 못한다 → 최소한 순서를 반영할 수 있는 장치를 마련한 것이 positional encoding

- word embedding에 똑같은 크기로 더해주어야 한다. → 단어의 위치에 따라 positional encoding 의 size가 달라져서는 안된다.
- 위치관계를 표현해야하므로 단어사이의 거리가 멀 경우 positional encoding vector사이의 거리도 멀어져야한다.
- sequence길이, n=100이고 각 단어의 차원이 512일때 positional encoding을 위의 식대로 생성한 후 L2-norm distribution을 계산한 결과

- 평균에 비해 표준편차가 매우 작은것을 확인할 수 있음
- 멀면 멀수록 positional encoding사이 거리가 커야함(The further the two positions, the larger the distacne)
- 하지만 실제로는 그렇지 않은 경우도 있긴함
- 어떤 단어가 앞에나오고 뒤에나오고에 대한 내용은 보전하지 못해도, 얼마나 멀리 떨어져 있는지에 대한 정보는 전달될 수 있다.
3. Multi-head attention
- the word in each position flows through its own path in the encoder
- There are dependencies between these paths in the self-attention layer. The feed-forward layer does not have those dependencies → thus the various paths can be executed in parallel while flowing through the feed-forward layer.
- Self attention layer : Dependency O, feed-forward layer : Dependency X
- Dependency가 있다 : 서로 영향을 미친다
- 차원수는 그대로 유지된다.
- feed foward layer는 구조가 같지만 weight를 공유하지는 않음

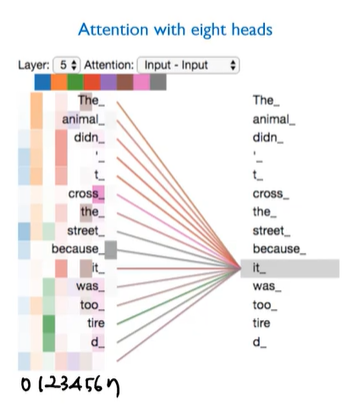
Self attention의 역할 :
- The animal didn’t cross the street because it was too tired
- it : the animal
- it이라는 단어를 processing할때, 문장 내 다른 단어들을 살펴보면서 it과 연관된 단어가 무엇인지에 대한 정답을 얻는 과정이라고 할 수 있음
- =현재 단어와 연관된 단어는 무엇인가?

Self-Attention in Detail
✅ Step 1. create three vectors from each of the encoder’s input vectors
(각각의 input vector에 대해 Query vector, Key vector, Value vector를 생성)
- Query vector : 현재 보고있는 단어의 representation, 다른 단어들을 scoring하기 위한 기준이 되는 값 (We only care about the query of the tocken we’re currently processing)
- Key vector : label, query가 주어졌을 때 이 쿼리에 대해 relevant한 단어를 찾는다고 할때 key 값을 활용해 찾음
- Value vector : actual word representation
⇒ query와 key를 통해 가장 적절한 value를 찾아 연산한다!

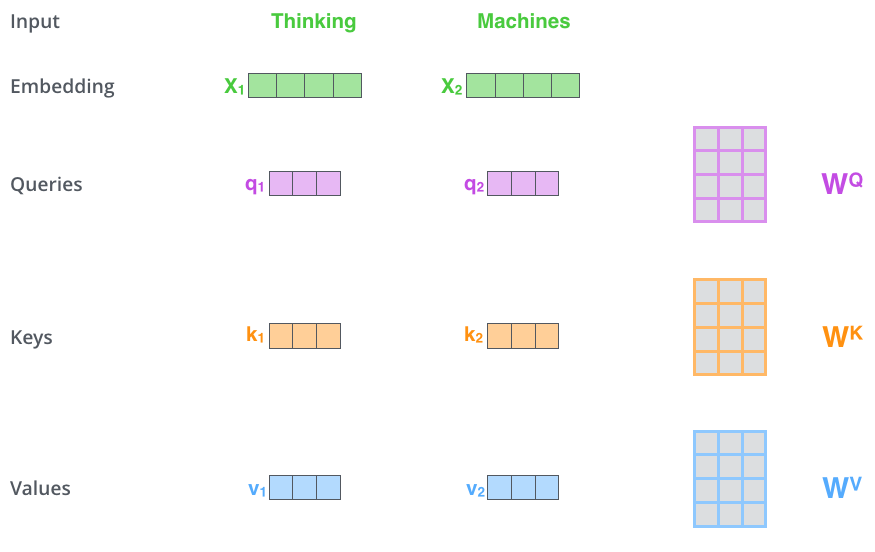
Input Embedding에서 만들어지는 Query, key, value
- 각각에 해당하는 matrix가 존재해서 계산해주면됨
- Ex. X1 x Wq → (1x4) x (4x3) ⇒ (1x3) ⇒ q1
- Wq,Wk,Wv는 학습을 통해 찾아야하는 미지수
- Notice that these new vectors are smaller in dimension than the embedding vector.
- Their dimensionality is 64
- (Multi head attention관점에서 Multi head attention을 통과한 벡터를 concat해서 encoder, decoder를 통과하게 하기때문에 작게 잡는것이 좋음)
- 64 * 8 = 512 → 여기서 8은 Multi-head attention의 숫자
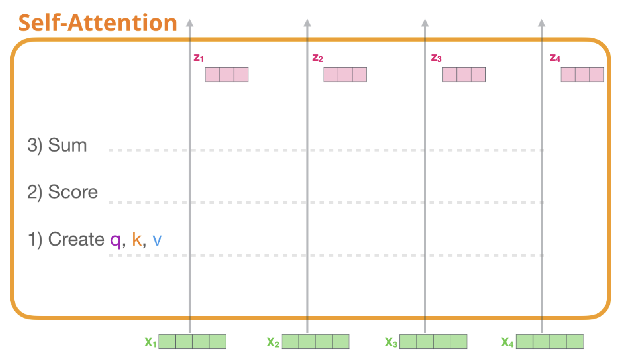
✅ Step 2. calculate a score, i.e, how much focus to place on other parts of the input sentence as we encode a word at a certain position (query와 가장 관련성 높은 단어는 무엇인지 찾기위한 score계산)
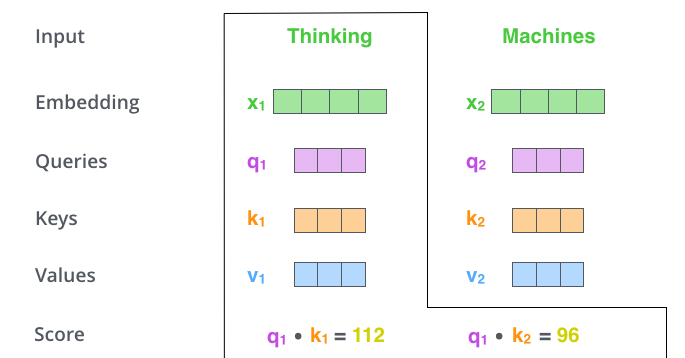
- The score is calculated by taking the dot product of the query vector with the key vector of the respective word we’re scoring.
- 현재 보고있는 토큰의 query(q1)과 자신의 key를 포함한 모든 key와 연산을 수행해 score를 계산
✅ Step 3. divide the scores by the square root of the dimension of the key vectors (query, key, value 차원의 root를 씌운 숫자를 score에서 나눠준다.)
- This leads to having more stable gradients
✅ Step 4. pass the result through a softmax operation
- 이렇게 만들어진 score는 현재 단어에 해당 단어가 얼마나 큰 영향을 미치는지를 나타냄

✅ Step 5. multiply each value vector by the softmax score(실제 value와 softmax를 통과한 값을 곱해준다)
✅ Step 6. sum up the weighted value vectors which produces the output of the self-attention layer at this position (for the first word).
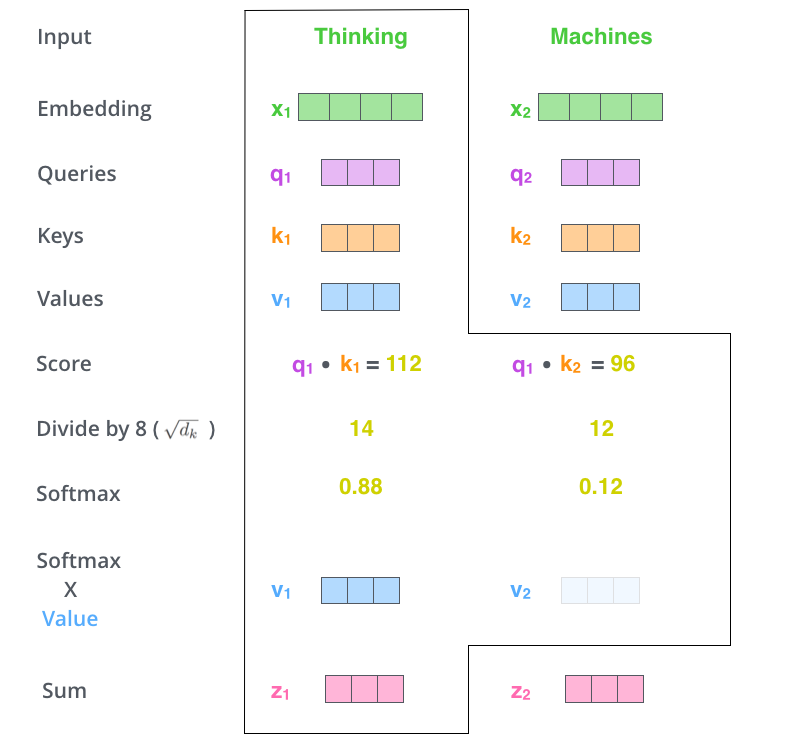
⇒ 현재 단어의 Self-Attention = weighted sum of value vectors

Matrix Calculation of Self-Attention
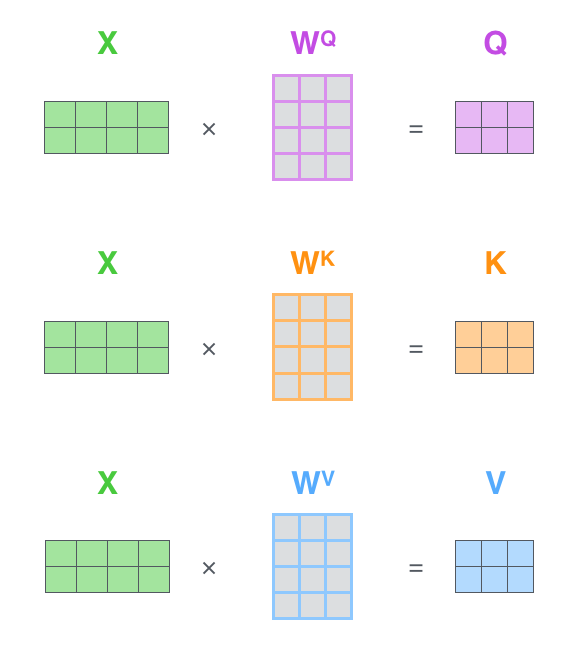
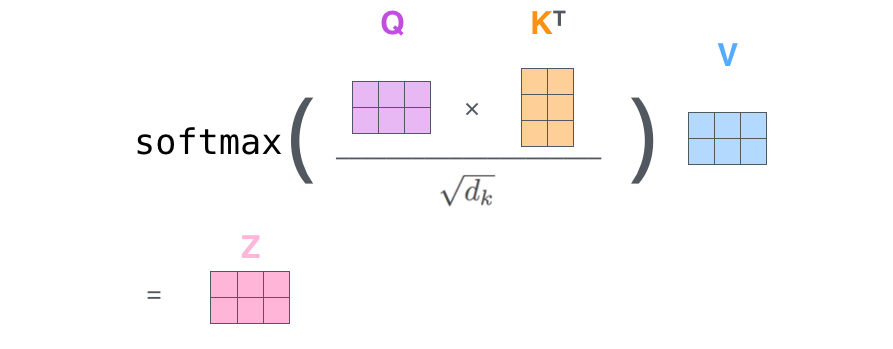
정리하며
1. 각 단어에 대한 Wq, Wk, Wv와의 연산을 통해 각각의 query, key, value를 만들어낸다.
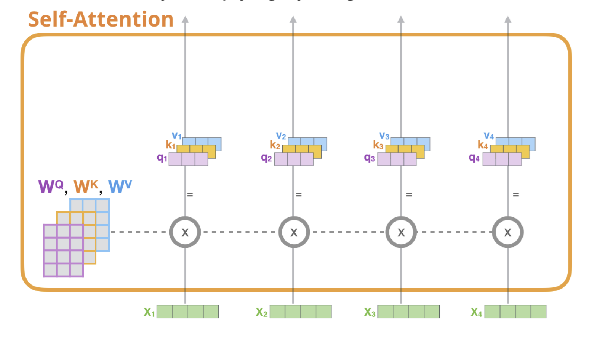
2. 첫번째 단어의 query와 모든 단어의 key value와 연산 → softmax → 가중치

3. 각각의 score와 value의 연산, 후 전체합계를 통해 첫번째 단어의 self attention계산 완료

4. 모든 단어에 대해 아래 과정을 반복해 모든 단어에 대한 self attention 계산 완료
Multi-Head Attention (Expand the model’s ability to focus on different positions)
→ 8개의 서로 다른 representation subspace를 가짐으로써 single-head attention보다 문맥을 더 잘 이해할 수 있게 된다.
→ layer를 여러 번 조금 다른 초기 조건으로 학습시킴으로써 '그것'에 관련된 단어에 대해 더 많은 후보군을 제공한다.
- 아까의 예시에서 it이 어떤 단어와 연관있는지를 1개만 결정하는 것이 아닌, 여러개를 허용한다 = Attention head를 여러개 둔다!
- Calculating attetion seperatly in eight different attention head
- 개별적인 attention을 만든 후 concatenate


<Multi-Head Attention 계산의 전반적인 과정>
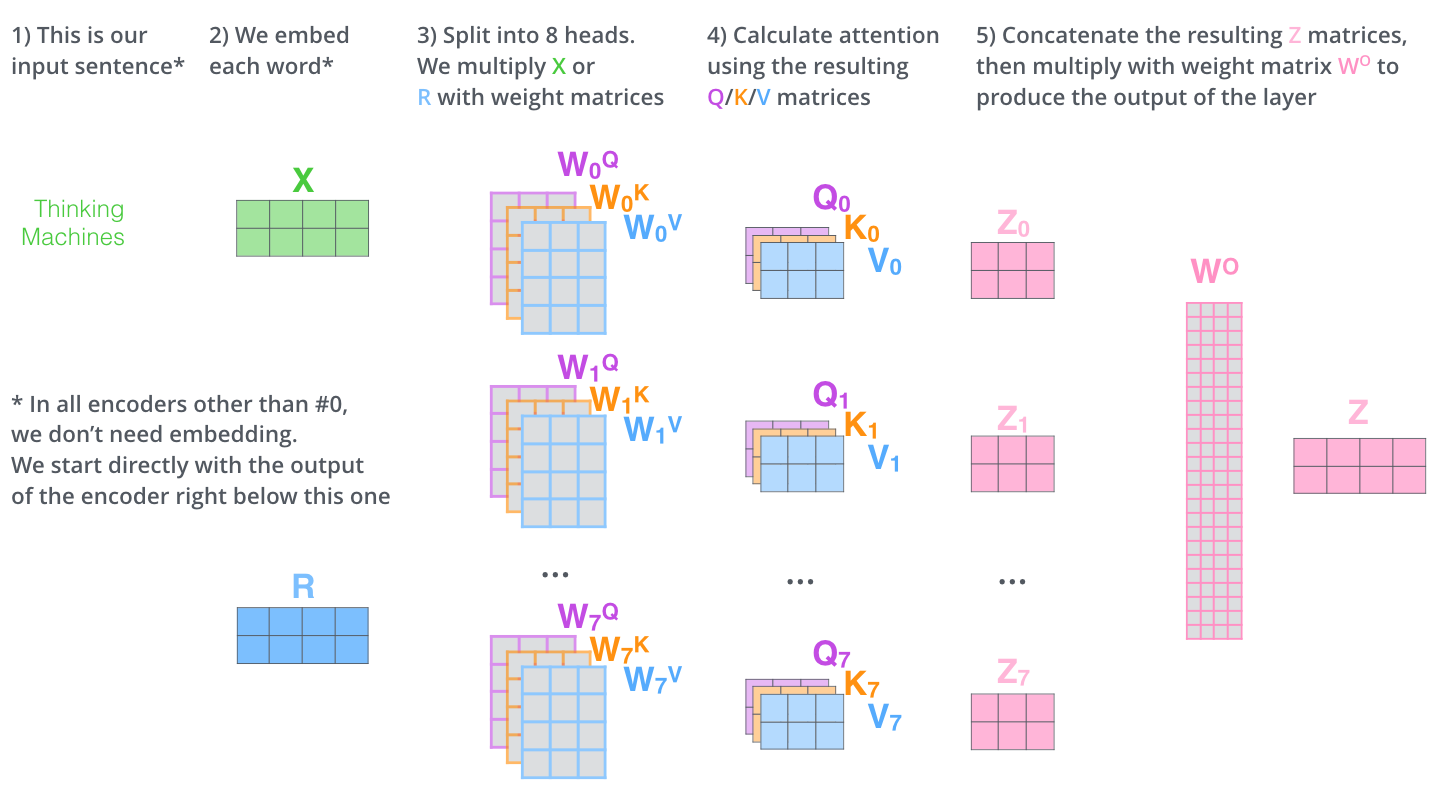
- 첫번째 인코더일 경우에만 input embedding X로 연산이 이루어지고, 이후의 encoder에는 직전 인코더의 output R로 해당 연산이 이루어짐
- 크기는 계속 유지됨!
Self attention layer를 통과한 다음에는?
⇒ Residual block & Normalization

$$ f(x)+x \rightarrow d \rightarrow f’(x)+1$$
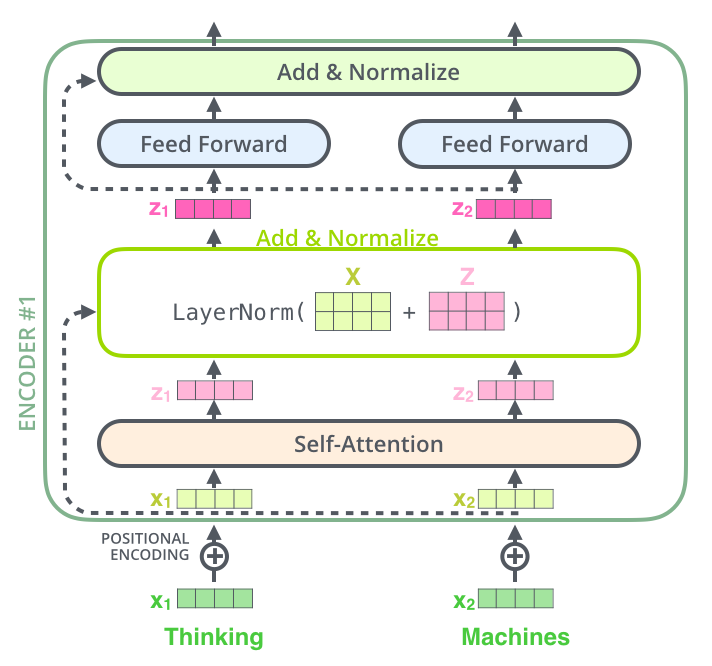
self attention의 output인 z에 x를 그대로 더해준 후 layer normalization을 진행
⇒ FFNN의 입력이 되는 z가 완성됨!
- Residual& Noramlization을 Encoder하나당 2번, decoder하나당 3번 default로 계속 적용됨
Position-wise Feed Forward Networks
- Fully connected feed forward network
- Applied to each position seperatly and identically(각 postition에 대해 개별적 적용)
- Relu function*W+b

$$FFN(x) = max(0,xW_1 + b_1)W_2 + b_2$$
- 각각의 layer마다 서로다른 parameter
- linear transformations are the same across different positions
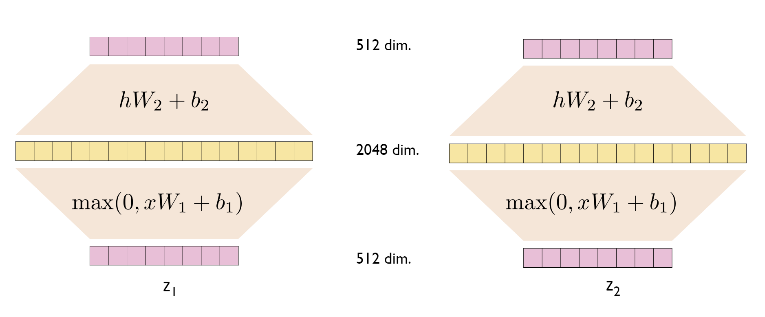
- 같은 encoder블록 내 FFN은 같은 구조
- 각 encoder블록간에는 다름
- 위 그림에서 z1, z2에 대한 W1,W2는 각각 같다!
kernel size = 1인 Convolution으로 생각하기


Decoder
Masked Multi-head attention
- Decoder에서의 self attention layer는 반드시 자기 자신보다 앞쪽 포지션에 해당하는 토큰들에 대해서만 attention score 참조 가능
- 이를 수학적으로 구현하기 위해 뒤에 나오는 단어의 score를 -inf로 주면, softmax를 통해 score = 0이됨

이를 그림으로
표현하면 다음과 같음
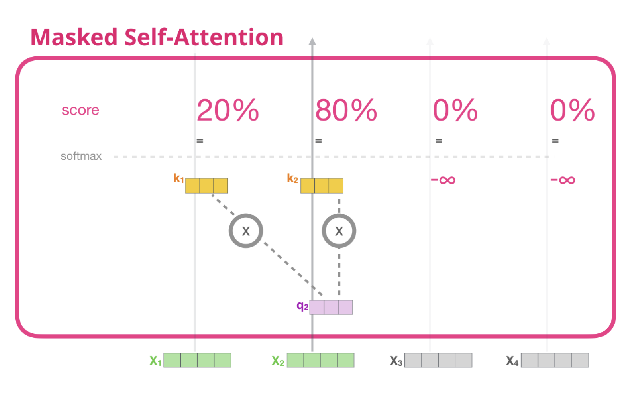
하지만 Sequentially 시행될 필요는 없음, 한번에


- encoder start by processing the input sequence
- The output of the top encoder is then transformed into a set of attention vectors K and V (These are to be used by each decoder in its “encoder-decoder attention” layer which helps the decoder focus on appropriate places in the input sequence)
- Encoder의 최종 output인 K,V는 stacked decoder의 Encoder-decoder attention layer에서 decoder가 어떤 input에 집중해야하는지 결정하는데 사용됨

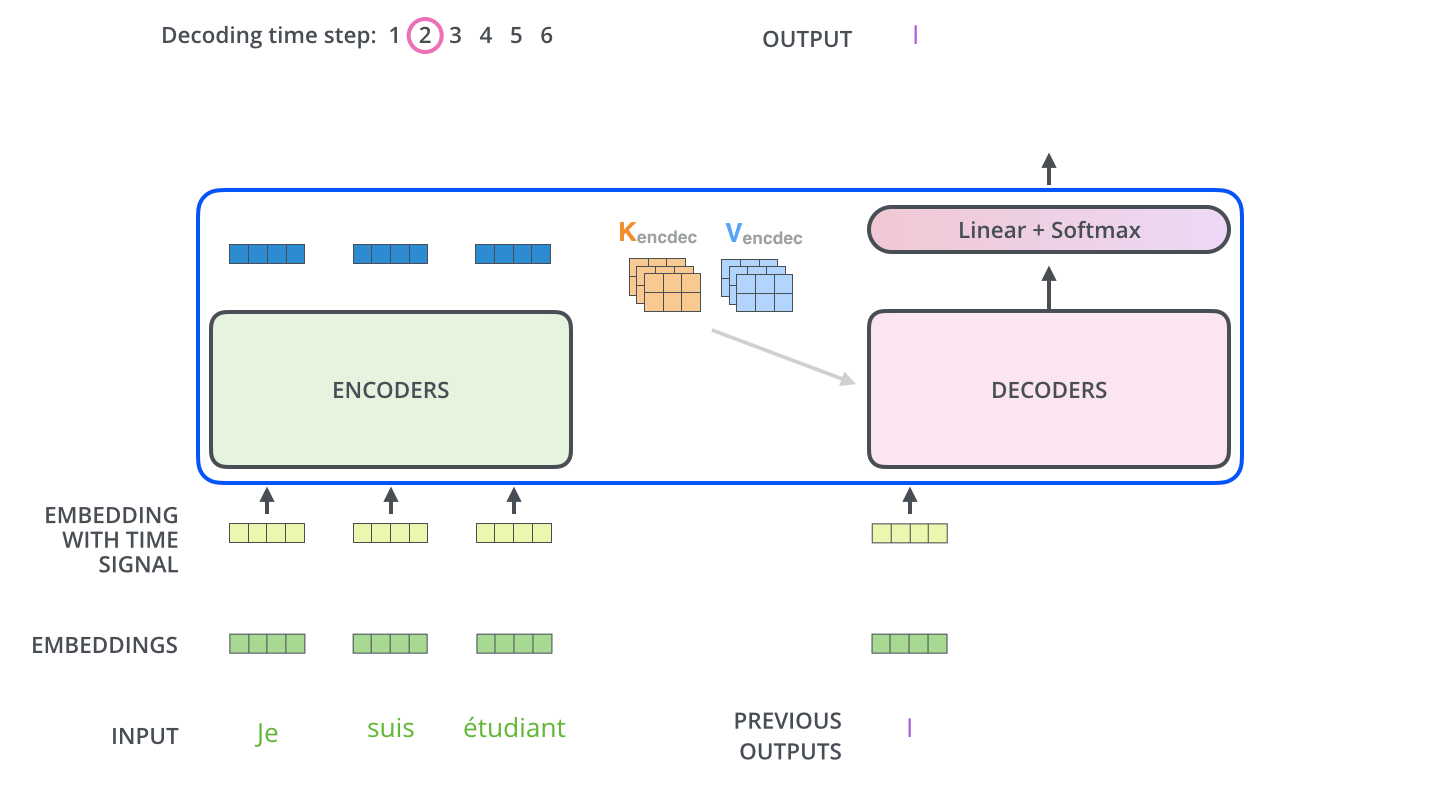
The Final Linear and Softmax Layer
- Linear layer : FFN
- Softmax layer : 최종 output 확률

'자연어처리 : NLP > Transformer based' 카테고리의 다른 글
| [논문 리뷰] RoBERTa: A Robustly Optimized BERT Pretraining Approach (0) | 2022.07.23 |
|---|---|
| BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding (0) | 2022.02.08 |
